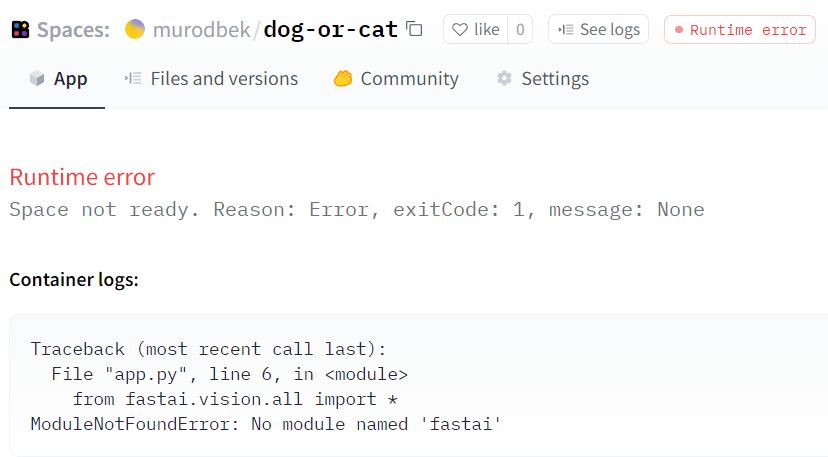
hi @JQsentcae, The aim of the forum is to help you learn how to solve these problems. That is… “teach you to fish” so to speak, rather than just throw you the whole fish. After Jeremy provided tour answer, you don’t report any follow up research. Something like these searches…
If you still unable to make it work, report what you’ve learnt, which will help you ask more targeted questions. It would be nice to hear you managed to sort it out yourself.
If you don’t have one already, create a ‘requirements.txt’ file in your root folder, then write ‘fastai’ in the document. Once you’ve pushed your changes to huggingface you should have access to fastai.
I am a bit confused by the following description in the content of L2:
All of these approaches seem somewhat wasteful, or problematic. If we squish or stretch the images they end up as unrealistic shapes, leading to a model that learns that things look different to how they actually are, which we would expect to result in lower accuracy. If we crop the images then we remove some of the features that allow us to perform recognition…
In my understanding, can’t we just regard those “crop/squish/pad” methods as kind of “augmentation”? How could they be wasteful or problematic?
I am afraid that it’s me keeping misunderstanding the original context, but let me try to elaborate my question again.
When we apply augmentation techniques, the images are often “squished” and even “distorted”, therefore I don’t see why the “squishing” operation will cause any problems.
Similarly, “cropping” is also a common augmentation technique. How could it is okay for augmentation but is wasteful when we apply ResizeMethod?
I think the statement should be viewed in the context of ‘Resize’ vs ‘RandomResizedCrop’. Jeremy is saying that randomly cropping a different part of an image is better than cropping the same part every epoch since the model will get to see different parts of the image.
It is also better than squishing the original image since squishing changes the aspect ratio. Hope this helps?
Thank you for the context part. Can I say that “cropping out different parts” is a better strategy than “just cropping the center part” in the sense of utilizing the original images?
For the squishing part, my understanding now is as the following (FYI and welcome any suggestions or corrections):
If we just squish the image blindly, than it might cause the objects (e.g., bears here) be transformed into extremely aspect ratios and which could be out of reasonable range hence be harmful to our models.
When applying augmentation techniques, however, the aspect ratios would be limited within certain ranges and therefore the effects might be different to the purely squishing operation.
I never expect that I would have to think such basic concepts again after training many models. That’s great to revisit and to clarify these stuff.
Even although it’s common for augmentation, it still has problems. Hopefully from the description you quoted, you can see that it has downsides, and you can think about how to best mitigate these downsides when thinking about how to augment your data.
in the video for this lesson Jeremy said he will share the version of the notebook using ddg instead of bing image search. I can’t see a link to it within this topic. does anyone know if it is available? thanks
By the way: Yuqi’s code (Lesson 2 official topic - #335 by Yuqi) solved a bug in my HF app. Turns out I couldn’t just use my original ‘categories’ list from generating & saving a learner, when I reload it. I needed to do just what Yuqi did and use its “learn.dls.vocab” list instead. Maybe fast.ai alphabetizes the categories?