For installing image classification learner which Jeremy showed in lesson2. When I am running in a notebook, I got the below error:

I used the following imports only:
from fastai.vision.all import *
from fastai.vision.widgets import *
For installing image classification learner which Jeremy showed in lesson2. When I am running in a notebook, I got the below error:
I used the following imports only:
from fastai.vision.all import *
from fastai.vision.widgets import *
fastai/widgets.py at ab154927696338741e59e0ffc4774777c4a9781c · fastai/fastai · GitHub seems to be where the cleaner comes from.
It’s just the setup-conda script that you’re meant to run. Don’t run ubuntu-initial.sh.
I don’t see an error in the image you’ve provided - I’m just seeing the text output of that cell. Is that what you’re referring to?
If so - just execute the cell (shift-enter) to and the interface will pop up.
Yes it’s not an error. It’s a text output in shell. The code is as show below in screenshot.
So the first screenshot was when I ran on JupyterLabs on top of JarvisLabs. On running shift+enter multiple times I get the same output, which is a bunch of images with text output for the value of cleaner. (cc: @VishnuSubramanian )
While when I tried in Kaggle I noticed, it’s working perfectly fine.
Does ImageClassifierCleaner run only in Jupyter notebooks?
You can still do that for additional distros, or I think you can even start the install fresh from the Windows Store with your first distro. You can then start each from Start, or you will see them added to the drop down of different ‘terminals’ to open in Windows Terminal.
Quite possibly - I haven’t tried it in JupyterLab.
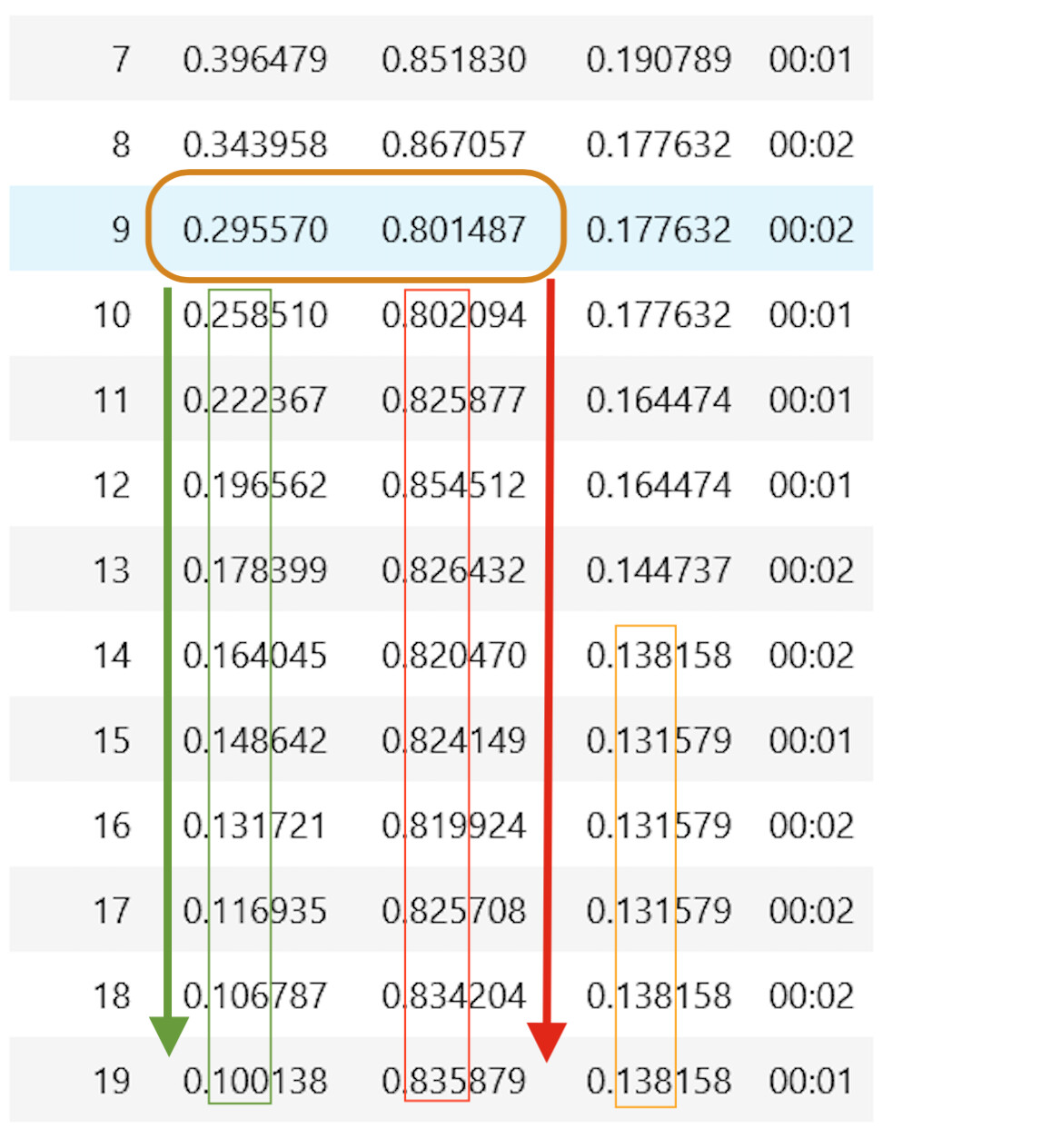
I’ve annotated the image a bit from the lowest point for validation_loss (i’m assuming), where it seems like training loss and validation loss has diverged.
The error rate (once again i’m assuming) also eventually increases towards the end again. With this information, I would assume that if the training continued in the same trajectory as it is in the image above, the model would definitely get worse overall (it’s currently overfitting, started at epoch 9, and also got worse from epoch 18 in terms of metrics).
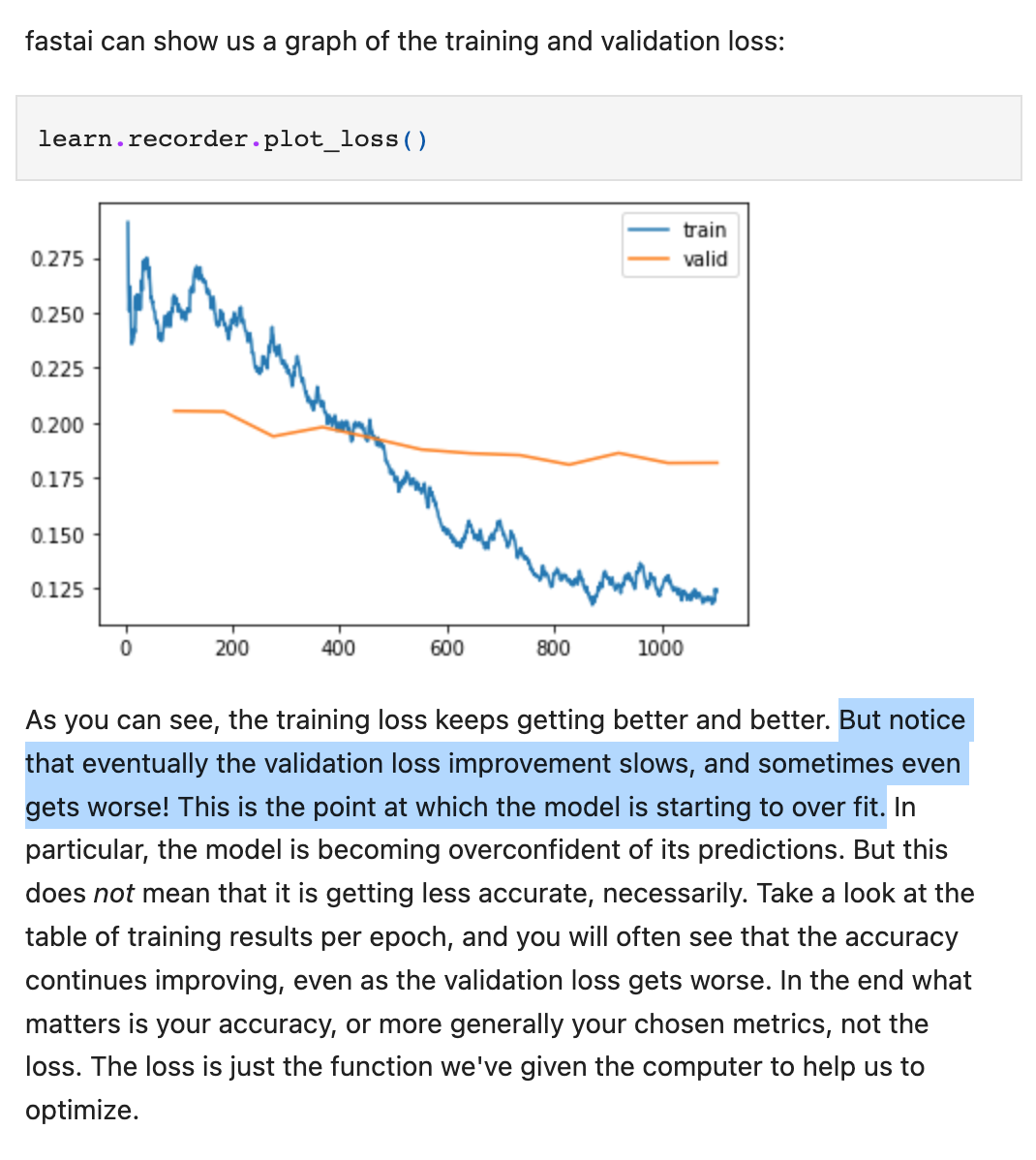
The learner object also has a recorder that can plot losses after each fit session. You can get a plot via learn.recorder.plot_loss() and interpret the results better. Image below taken from Chapter 5 of the book. And as the book mentions, in the end what matters is your metrics, not the losses really.
So, I’d say that you might have to train a bit further to see the error_rate get worse with certainity before you can rule that the model is indeed getting much worse.
I having trouble reconciling these two comments:
WSL is “through Linux”.
Now I suspected this would be the case for `which code`.
My vague memory from last week is that this remained after I uninstalled VSCode from Linux. This indicates “code” was not fully uninstalled, and this is being executed in preference to the “code.exe” located on the windows side. I think I just deleted the file, but not sure - keep a backup of the file.
Yup that file is safe to delete. If it exists, it means you’re running the WSL vscode, which isn’t what you want.
Has anyone had any luck with setting up a rig to use fast.ai with ROCm? I’ll be attempting this by working with the official AMD documentation and looking at this topic, though it has aged somewhat Fastai on AMD GPUs - Working dockerfile . Using docker seems to be the best supported way.
Yeah, it is not working on Jupyterlab which is the default while using Jarvislabs.ai, the simplest way to switch to Jupyter notebooks would be to replace the word lab with tree in the URL.
I will explore if it can be run in Jupyterlab.
Great! Let us know what you find. It’s just using regular ipywidgets.
Question:
Hi All whenever we are running the fine_tune of a particular pre-trained model we get this output.
What does the highlighted one represent? How is it different from below epoch 0?
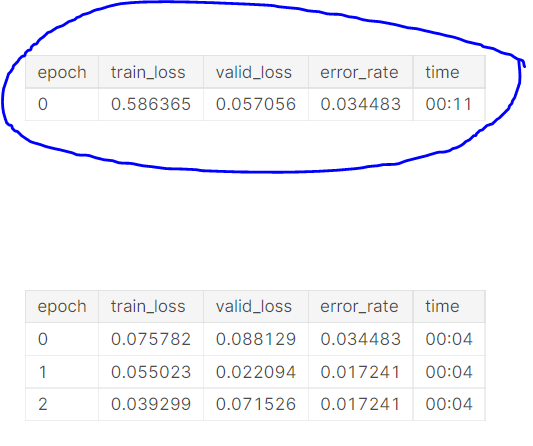
So basically you have a pretrained model, right? This is a model trained on a very large image classification dataset, almost always ImageNet. The idea behind fine-tuning is that many features learned to classify on ImageNet will transfer well to other datasets. So you simply have to fine-tune the pretrained model for it to do well on the target dataset.
The process that fastai takes is that we first change the last few layers of the model and train it from scratch. This is because those last few layers are more specific for performing well on ImageNet the dataset (for example, the last layer outputs 1000 values for the 1000 classes in ImageNet but your dataset will have a different number of classes). So we train just those last few layers, in this case for one epoch. That is where the first “epoch 0” is coming from. Next, we “unfreeze” the whole model and continue training the whole model, but you don’t have to train much because the features are already pretty close so that’s what the remaining epochs 0-2 are for.
Does this clarify stuff a little bit? A lot of this will be discussed in more detail later in the course and the book.
Thanks looking forward for more new things!
Really thankful for the detailed explanations like this and for quoting where in the book also ![]() .
.
If you look at the kaggle notebook, the metrics is not improving after like 20-30 epochs. So it’s indeed over fitting.
Thanks didn’t know that actually existed for using Jupyter notebooks too ![]() .
.
I noticed jupyter-contrib-nbextensions also doesn’t work in JupyterLabs for using collapsible headings.
Hi,
After git pushing the app.py file to spaces I am running into runtime error:
Traceback (most recent call last):
File "app.py", line 6, in <module>
from fastai.vision.all import *
ModuleNotFoundError: No module named 'fastai'
Did I miss any steps?