Hi everyone! I am using DuckDuckGo to find bear images, and I can’t create the list of urls. First of all, I had to change the search_images_ddg cause it gave me errors:
def search_images_ddg(key,max_n=200):
"""Search for 'key' with DuckDuckGo and return a unique urls of 'max_n' images
(Adopted from https://github.com/deepanprabhu/duckduckgo-images-api)
"""
url = 'https://duckduckgo.com/'
params = {'q':key}
res = requests.post(url,data=params)
searchObj = re.search(r'vqd=([\d-]+)\&',res.text)
if not searchObj: print('Token Parsing Failed !'); return
requestUrl = url + 'i.js'
headers = {'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:71.0) Gecko/20100101 Firefox/71.0'}
params = (('l','us-en'),('o','json'),('q',key),('vqd',searchObj.group(1)),('f',',,,'),('p','1'),('v7exp','a'))
urls = []
while True:
try:
res = requests.get(requestUrl,headers=headers,params=params)
data = json.loads(res.text)
for obj in data['results']:
urls.append(obj['image'])
max_n = max_n - 1
if max_n < 1: return L(set(urls)) # dedupe
if 'next' not in data: return L(set(urls))
requestUrl = url + data['next']
except:
pass
ims = search_images_ddg('grizzly bear', max_n=200)
len(ims)
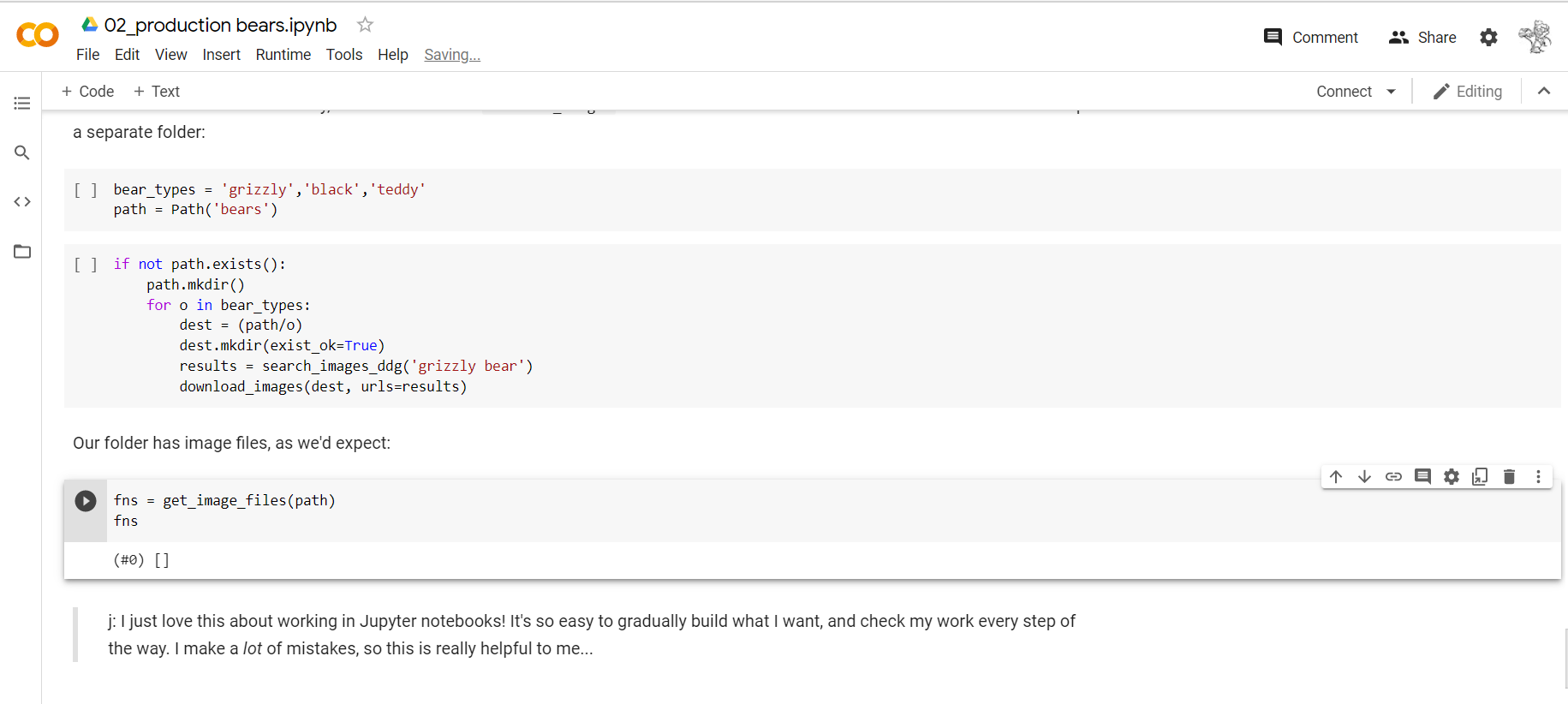
This cell worked, but then I wasn’t able to run fns = get_image_files(path). Am I missing something? Maybe, there is a mistake while changing search_images_ddg. Below is the screenshot of code:
search_images_fail|690x309
{kind=link}