hi, I had this error the other day, this post was helpful:
hi, when I was experimenting with the bear detector example I end up with interesting results. My error rate is actually 0 as you can see on the image below. (I downloaded around 150 images from bing for that exercise)
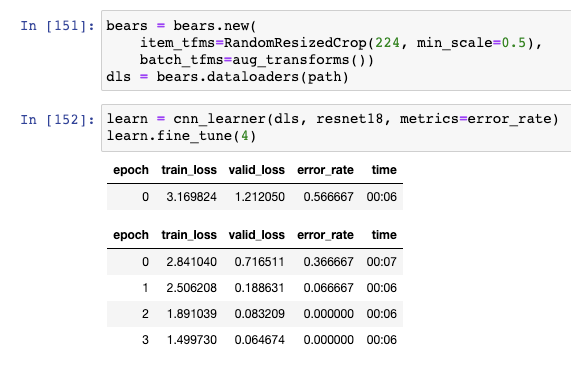
I’m wondering if this might be an indicator of some form of overfitting/memoization ?

I am dealing with the same issue on the same platform, can you tell me specifically what is wrong here.
In the video at around the 1:06:40 mark, The topic of model maintenance (how to update it over time, how to know if your model still works). It’s mentioned that there are few papers on this topic, despite its importance.
Could anyone point me to some (or even one) of these paper. Or even the terms to use for searching for them.
Hi _alex hope you are having a fabulous day!
Surf “how to keep your ai model up to date” and let the articles you find guide your next searches!
Cheers mrfabulous1 ![]()
![]()
By setting unique=True you are instructing show_batch to pick a single image, apply all the defined transformations and display the image.
And in the item_tfms you’ve only used a single transformation ie., RandomResizedCrop
Hi there, I started the course and am really liking it (currently in lesson 2).
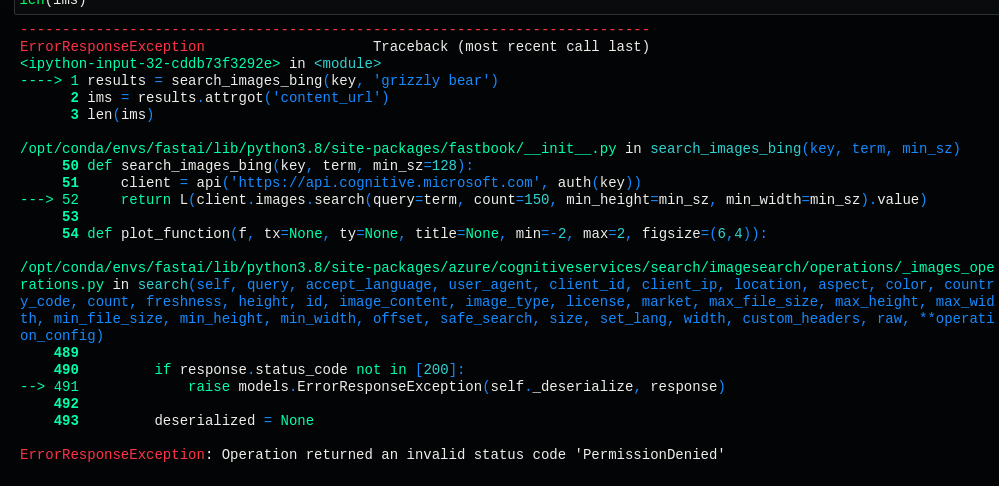
When trying to use the azure key, I always get this error and I can’t figure out what to do:
#To download images with Bing Image Search, sign up at Microsoft Azure for a free account. You will be given a key, which you can copy and enter in a cell as follows (replacing ‘XXX’ with your key and executing it):
key = os.environ.get('AZURE_SEARCH_KEY', 'XXX')
#Once you’ve set key, you can use search_images_bing. This function is provided by the small utils class included with the notebooks online. If you’re not sure where a function is defined, you can just type it in your notebook to find out:
search_images_bing
results = search_images_bing(key, 'grizzly bear')
ims = results.attrgot('content_url')
len(ims)
HTTPError Traceback (most recent call last)
<ipython-input-18-cddb73f3292e> in <module>()
----> 1 results = search_images_bing(key, 'grizzly bear')
2 ims = results.attrgot('content_url')
3 len(ims)
1 frames
/usr/local/lib/python3.6/dist-packages/requests/models.py in raise_for_status(self)
939
940 if http_error_msg:
--> 941 raise HTTPError(http_error_msg, response=self)
942
943 def close(self):
HTTPError: 401 Client Error: PermissionDenied for url:
https://api.bing.microsoft.com/v7.0/images/search?
q=grizzly+bear&count=150&min_height=128&min_width=128
I am using Google Colab.
Maybe I have to add that I don’t know what the key name is that I should replace the ‘XXX’ with. Jeremy Howard said that you would get one when signing up to Azure, but I didn’t.
I got the same error 
Have you solved it now?
If you have nailed it, could you please tell me the way?
Hi everyone! I am using DuckDuckGo to find bear images, and I can’t create the list of urls. First of all, I had to change the search_images_ddg cause it gave me errors:
def search_images_ddg(key,max_n=200):
"""Search for 'key' with DuckDuckGo and return a unique urls of 'max_n' images
(Adopted from https://github.com/deepanprabhu/duckduckgo-images-api)
"""
url = 'https://duckduckgo.com/'
params = {'q':key}
res = requests.post(url,data=params)
searchObj = re.search(r'vqd=([\d-]+)\&',res.text)
if not searchObj: print('Token Parsing Failed !'); return
requestUrl = url + 'i.js'
headers = {'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:71.0) Gecko/20100101 Firefox/71.0'}
params = (('l','us-en'),('o','json'),('q',key),('vqd',searchObj.group(1)),('f',',,,'),('p','1'),('v7exp','a'))
urls = []
while True:
try:
res = requests.get(requestUrl,headers=headers,params=params)
data = json.loads(res.text)
for obj in data['results']:
urls.append(obj['image'])
max_n = max_n - 1
if max_n < 1: return L(set(urls)) # dedupe
if 'next' not in data: return L(set(urls))
requestUrl = url + data['next']
except:
pass
ims = search_images_ddg('grizzly bear', max_n=200)
len(ims)
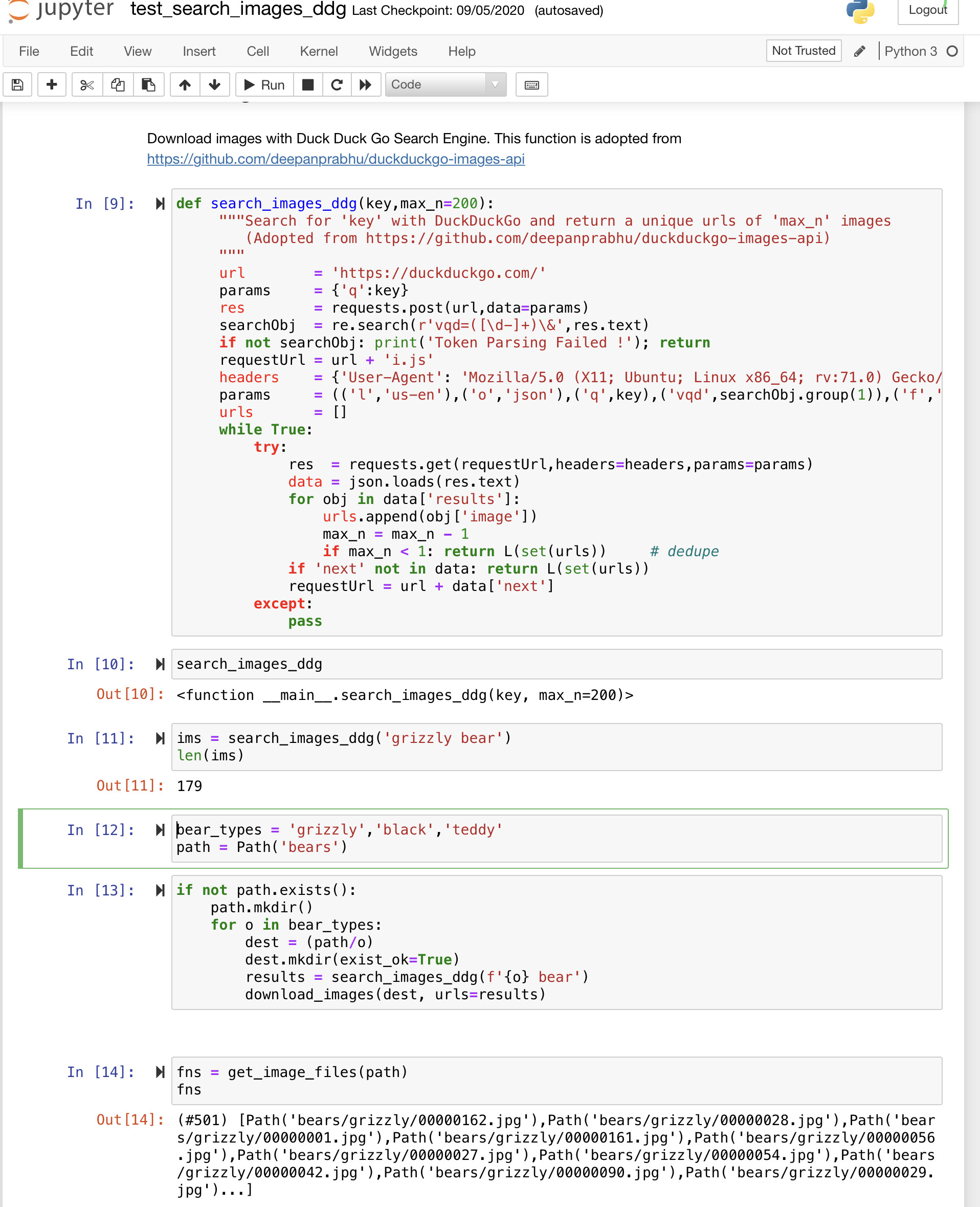
This cell worked, but then I wasn’t able to run fns = get_image_files(path). Am I missing something? Maybe, there is a mistake while changing search_images_ddg. Below is the screenshot of code:
search_images_fail|690x309
1 Like
This works for me. Be sure to be use the correct version of search_images_ddg(), as the pip version is different. (I wrote this function and at one point it was committed to the fastaibook repository. Somehow the pip version of fastaibook has different code.)
Here is just a picture of what works for me. I haven’t looked at this for months, so it may take me a bit to get back up to speed if you have more questions.)
Blockquote
4 Likes
Thank you very much! I saw that you don’t have dest = 'images/grizzly.jpg' and download_url(ims[0], dest). I’ve run cells as on your screenshot, avoiding download_url and dest, and it worked! Thank you very much, now everything works 
@Albertotono @csw @DanielLam Thanks for solving the fastai/ voila/ binder issue
Hi everyone !!
I started working lesson 2 on paperspace gradient when I encountered this error when I was using search_images_ddg api
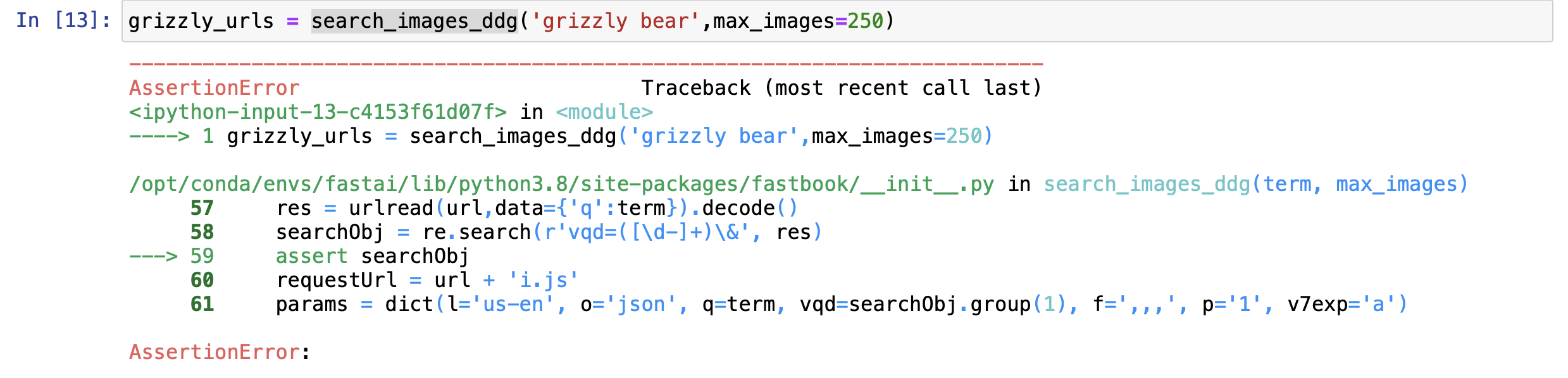
{kind=link}
What can be the issue here ?
I’ve addressed this issue previously. I originally wrote the search_images_ddg code and contributed it to fastbook Github repo. Somehow, the version that was packaged into pip was altered. Here is code from the fastbook github repo that works.
(If someone can tell me how to send a request to update the pip package, that would be great!)
from fastbook import *
def search_images_ddg(key,max_n=200):
"""Search for 'key' with DuckDuckGo and return a unique urls of 'max_n' images
(Adopted from https://github.com/deepanprabhu/duckduckgo-images-api)
"""
url = 'https://duckduckgo.com/'
params = {'q':key}
res = requests.post(url,data=params)
searchObj = re.search(r'vqd=([\d-]+)\&',res.text)
if not searchObj: print('Token Parsing Failed !'); return
requestUrl = url + 'i.js'
headers = {'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:71.0) Gecko/20100101 Firefox/71.0'}
params = (('l','us-en'),('o','json'),('q',key),('vqd',searchObj.group(1)),('f',',,,'),('p','1'),('v7exp','a'))
urls = []
while True:
try:
res = requests.get(requestUrl,headers=headers,params=params)
data = json.loads(res.text)
for obj in data['results']:
urls.append(obj['image'])
max_n = max_n - 1
if max_n < 1: return L(set(urls)) # dedupe
if 'next' not in data: return L(set(urls))
requestUrl = url + data['next']
except:
pass
1 Like
Thank you !
I’m trying to understand exactly how the dataloaders works and what gets used for training. Specifically, the lines of code I’m confused with is
bears = bears.new(item_tfms=Resize(128), batch_tfms=aug_transforms(mult=2))
dls = bears.dataloaders(path)
dls.train.show_batch(max_n=8, nrows=2, unique=True)
In the book, this outputs 8 versions of the same image but with some transformation on it. Does this mean all 8 augmented versions, or potentially more, of that original image will be used to train? Or is only one of them used to train?
I get that item_tfms=Resize(128) resizes the 150 or so unique images one at a time, but since the output of dls.train.show_batch(max_n=8, nrows=2, unique=True) was 8 versions of the same image, does that mean batch_tfms=aug_transforms(mult=2) created those extra ones?
Basically, I want to know what exactly is in the training set after those 3 lines of code are run.
Just a note - I was getting the following error with the lesson 2 notebook: [Unreadable Notebook NotJSONError(‘Notebook does not appear to be JSON: u’{\n “cells”: [\n {\n “cell_type”: "…’,)]
This seems to have resolved after adding a newline (\n") at the end of the line beginning lbl_pred.value =.
Mine now reads: " lbl_pred.value = (f’I think it is: {pred} ({probs[pred_idx]*100:.00f})%’) \n"
Still no luck running the thing in binder. I’m trying Heroku next!
What’s the link to the blog post Jeremy mentions in Lesson 2 [1:07]?. He describes it as his most popular blog post but I can’t seem to find it
1 Like
Yes me. Any idea on how to solve it ? If it needs solving… Since the classifier works decently even with this warning.