Hello world. I am currently on part 1 lesson 2 and I am trying to implement the general steps suggested by Jeremy for fine-tuning model on my own project. The project I am doing is to classify dresses type from dresses images. The data have 5 classes (ard 2400 training images/ 200 validation images/ 200 test images for each class). By the way I am implementing each steps, a few questions pop up on my mind, some related to model performance and some related to some practices that Jeremy didn’t raise in the lecture. I will post my steps one by one here. Your help or answers would be much appreciated!
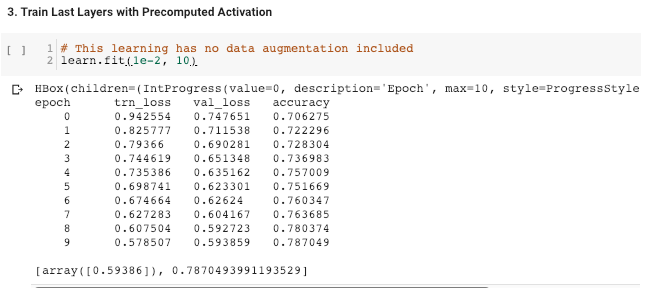
Step 1: Finding optimal learning rate for training last layer with precompute = True
I don’t have any difficulties and questions in this step. As suggested by the attached picture below, 1e-2 turn to be a suitable learning rate.

Step 2: Train the last layer with precompute = True
My question to this step is related to the number of epochs. While Jeremy suggests to train the model with only 1-2 epochs. I found that the model performance keeps improving with epochs (for both training and validation set). In this case, I set epochs to be 10 and it seems the training can tolerate even more epochs.
In this step, should I keep increase the epochs until it shows sign of overfitting? (i.e loss of training set is way lower than that of validation set)
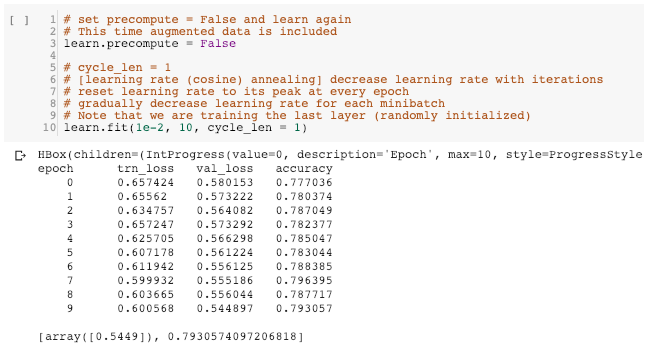
Step 3: Finding optimal learning rate again for training last layer with data augmentation and precompute = False
As demonstrated in lesson 2, we firstly train the last layer with precompute = True, followed by one more training on last layer with precompute = False with data augmentation. I doubt if the two training steps would have the same learning rates. Currently I didn’t implement this step in my project, but the question naturally pops up:
Is it reasonable to find the learning rate again for training last layer with data augmentation and precompute = False?
Step 4: Training last layer with data augmentation and precompute = False
Without doing step 3, I kept the learning rate = 1e-2 in this step. In turns out the model slightly improve after the training. (accuracy 0.787 before this step v.s. accuracy = 0.793 after this step)
In this step, I have questions related to the setting of fastai package:
I noticed that the training in this step starts with the loss and accuracy (accuracy = 0.777, validation loss = 0.580) very similar to final results in step 2 (accuracy = 0.787, validation loss = 0.594). I assume the model didn’t reset the weight and re-learn again. Could I say that the training process in “learn” object is always on top of the latest training result?
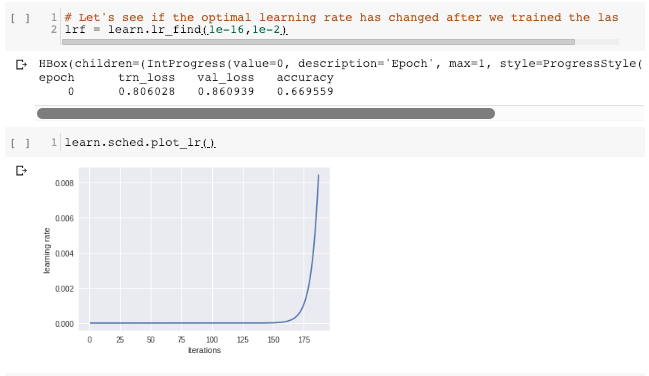
Step 5: Find optimal learning rate again for differential learning of remaining layers
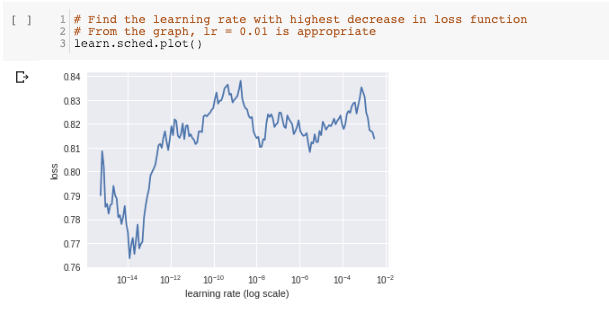
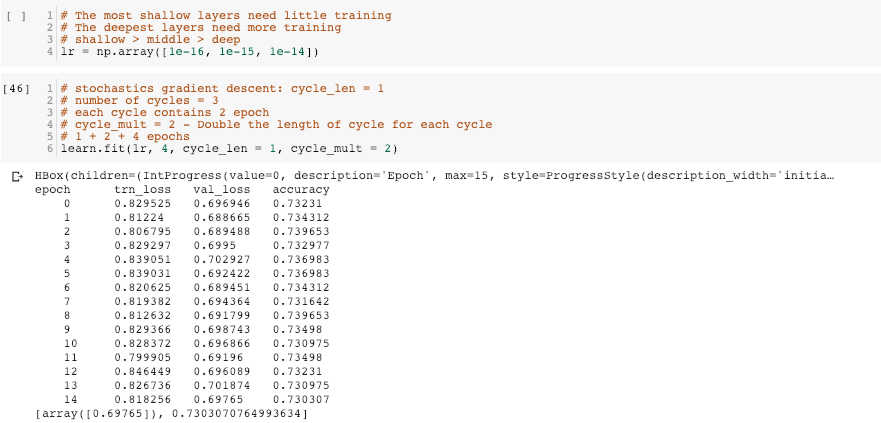
Similar to the logic above, I tried to find optimal learning rate again for the remaining layers. I set the grid search range of learning rate to be 1e-16 to 1e-2 as I assume the optimal learning rate would be much smaller than 1e-2. Below are the find_lr() results. From the learning-rate against loss plot, we found that in most learning rate range, the loss function is increasing. Decrease only occurs very shortly. The most stable decrease occurs when learning rate < 1e-14.
In this case, how should I select my optimal learning rate? Is the above result reliable? Should I rerun the find_lr() again with even smaller range of learning rate? (e.g 1e-30 - 1e-14.)
Besides that, I found that the find_lr() has brought the model to a worse performance (i.e at the end of the learning-rate against loss plot, loss = 0.81x) Would the next training step inherits such worse performance? If it does, should I reset the kernel and train again without running the find_lr()?
Step 6: Training remaining layers differential learning rate
At the end I decided to pick 1e-16 as the learning rate for the remaining layers. I trained the model with 4 cycles, but it turns out the model performance gets worse than the model performance in step 2… (accuracy = 0.787 in step 2 v.s. accuracy = 0.730 in this step)
Does anyone has any clues to the reasons? Is it related to the last find_lr() procedures?
Sorry that the post may be a bit long and messy with many questions. I would appreciate if anyone could give me any insights! Thank you

