Hi ,
I am getting below error from class -2 script
Any idea?
Hi,
I am still having trouble understanding the distinction between a asynchronous and a synchronous web framework such as Flask and Starlette. Can someone explain in layman terms why asynchronous frameworks work well for model inference? Thanks in advance!
`@app.route(’/analyze’, methods=[‘POST’])
async def analyze(request):
data = await request.form()
img_bytes = await (data['file'].read())
img = open_image(BytesIO(img_bytes))
prediction = learn.predict(img)[0]
return JSONResponse({'result': str(prediction)})
`
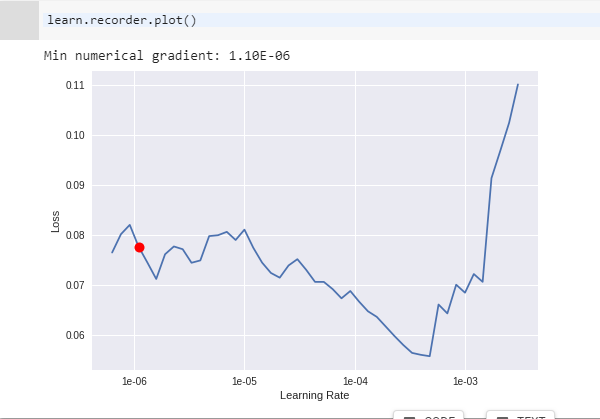
How to choose the best learning rate?
Hi there, I have a little puzzle.
When I run ‘too few epochs’ part:
learn = create_cnn(data, models.resnet34, metrics=error_rate, pretrained=False) learn.fit_one_cycle(1).
It is supposed to be train_loss > valid_loss, but somehow I got this:
What am I doing wrong?
Did anyone try to train another model with cleaned dataset?
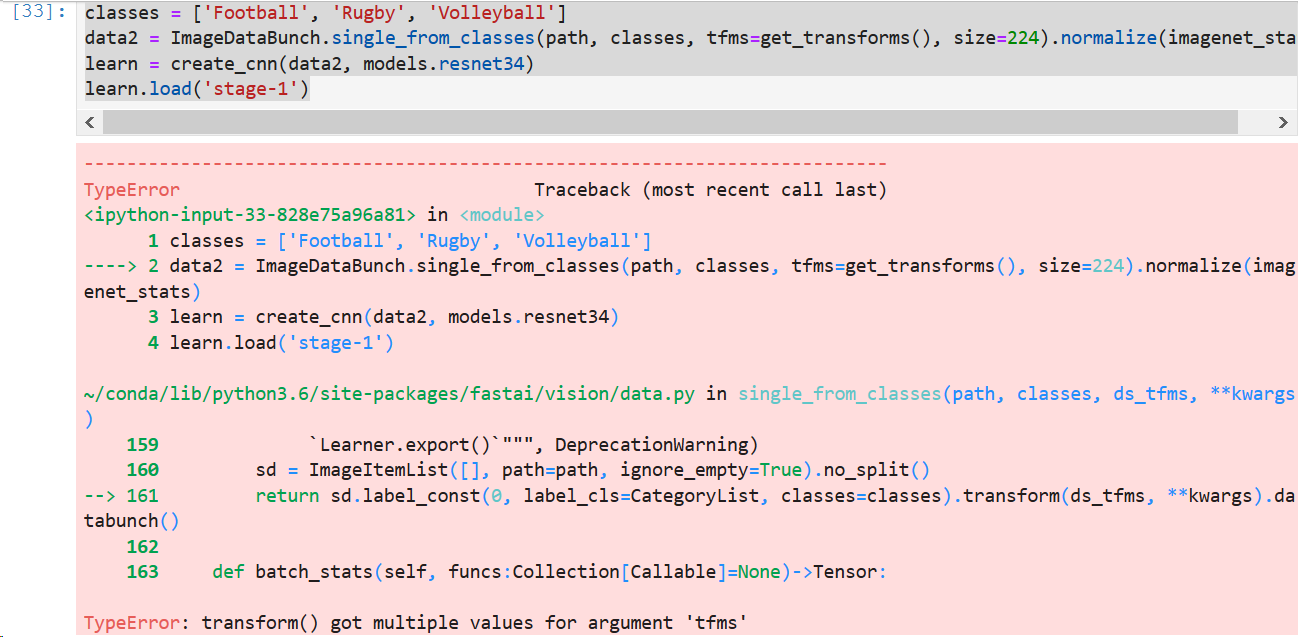
I am struggling with creating ImageDataBunch with the constructor ImageDataBunch.from_csv(). The file cleaned.csv generated by DatasetFormatter and saved in the ‘data/bears’ directory doesn’t work with the from_csv() method. How one should use the from_csv() to get the cleaned dataset created?
Moreover, after deleting the files with the DatasetFormatter and performingImageDataBunch.from_folder() like at the beginning of the notebook I got the same statistics for number of examples in training and validation dataset.
From Lesson-2 notebook (clearly speaking about deletion of files):
Flag photos for deletion by clicking ‘Delete’. Then click ‘Next Batch’ to delete flagged photos and keep the rest in that row.
ImageCleanerwill show you a new row of images until there are no more to show. In this case, the widget will show you images until there are none left fromtop_losses.ImageCleaner(ds, idxs)
Thank you for your help!
Hey Jeff
Really simply - the code will run in order that it is written, however, if some part of the code is taking time, in this case the request.form(), then the code will continue to run before the request has been 100% completed.
This generally results in errors because the following code is dependent on the response of request.form.
asynchronous or async is a way of telling the computer to wait. In this case:
data = await request.form() … the await call is halting the code from running until the request.form() is fully complete.
It can definitely be tricky - but keep at it and it becomes pretty simple. Check this out for some more async await info: https://www.youtube.com/watch?v=XO77Fib9tSI
That is all exactly as it is written in the notebook.
My guess would be that its the data variable that is wrong. It may have gotten messed up somewhere along the way. I would try re-running the notebook after a reset making sure you do the image download folder and file bit correctly. See the “Create directory and upload urls file into your server.” section.
To be sure your data set is correct look in your path (should be ‘data/bears’) and there should be 3 folders ‘black’, ‘teddys’ and ‘grizzly’.
If you just run the code from top to bottom you will probably only have a ‘grizzly’ folder.
Hope that helps…
Hey Preka
Running learner.fit_one_cycle(2, slice(lr)) is different to running learner.fit_one_cycle(1, slice(lr)) twice
Fit_one_cycle refers to the way the model will handle the mini batches and the first argument of the function relates to how many epochs. Does that make sense.
Check this for more details. https://medium.com/@nachiket.tanksale/finding-good-learning-rate-and-the-one-cycle-policy-7159fe1db5d6
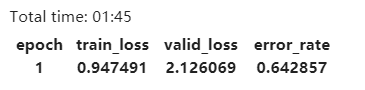
Thanks, actually I wrote a loop to load the data, and I made a double check about it. That’s probably not the case. To figure out, I tried different models with or without pretrained, and I got this.

What happens if you run more epochs on it?
Are you using your own data set or are you using the bears?
Confusing !!
hey fast.ai folks  As a classical music buff I created a CNN (with 4.5% error rate) based on the “download” notebook - it classifies grand pianos, upright pianos & violins. (I am stoked!)
As a classical music buff I created a CNN (with 4.5% error rate) based on the “download” notebook - it classifies grand pianos, upright pianos & violins. (I am stoked!)
But before creating this instruments classifier, I have tried creating a few different classifiers that failed terribly, the error rates were 30-40%:
Do you know the possible reasons certain types of datasets seem to work really well, while some others didn’t? Thanks!
CY Ooi
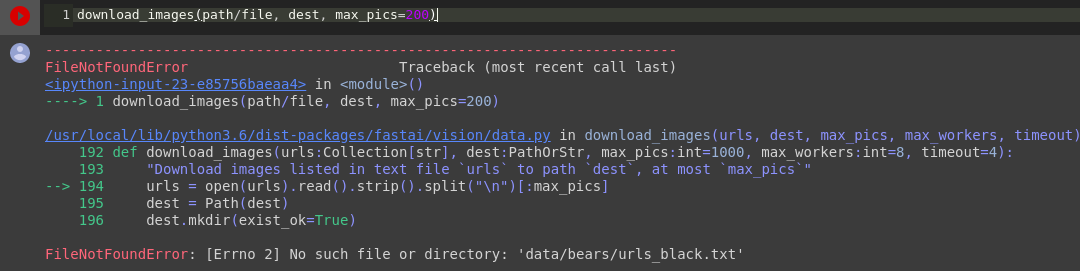
Hi! My workspce is Colab.In the code of the Lesson 2, when I execute this line of code:
download_images(path/file, dest, max_pics=200)
the code fails to run. The error message is as follows:
FileNotFoundError: [Errno 2] No such file or directory: 'data/bears/urls_black.txt'
Hi @Tianze Tang,
Colab has its own way of uploading files. See the Snippets tab on the left part of the screen.
You can type the following code in a cell:
from google.colab import files
files.upload()
When you run the cell, an upload button will appear in your notebook, allowing you to
upload the file. It will store the file in current directory (usually /content)
HTH.
Butch
When running the plot function on the grizzly/black/teddies images, I saw the following plot, more or less as expected:
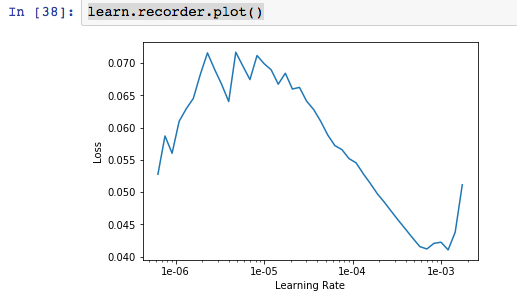
I found that the error_rate was ascending, not descending, with the default parameters 3e-5,3e-4. So I switched to 1e-5,1e-4, figuring that in the above plot, that seemed to be about where the steepest descent is. But still I see an ascending error rate:
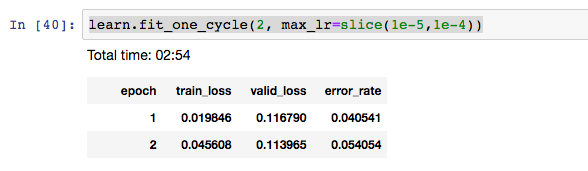
Is this an indication that something is wrong? Or does this mean I should just begin experimenting with other bounds for the max_lr function?
I then thought I might try for a third epoch and got this:
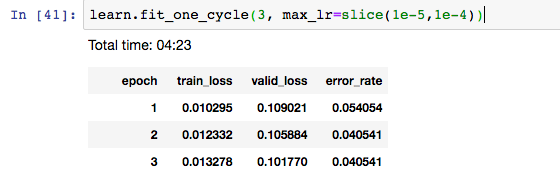
So here the error rate descends but holds steady. I’m wondering why it would first increase from epoch 1 to epoch 2, and then, with a third epoch added, would decrease from epoch 1 to epoch 2. I’m guessing that this is because I need to run more epochs(?). If that is the case then are we just essentially seeing a kind of statistical noise or randomness that will tend to disappear over multiple epochs?
I’m using paperspace gradient.
Thanks!
I had the same issue, found your post while looking for an answer, but don’t see a response here. In case anyone else has the same question, I used these instructions to convert txt to csv: https://support.geekseller.com/knowledgebase/convert-txt-file-csv/
Hello everyone!
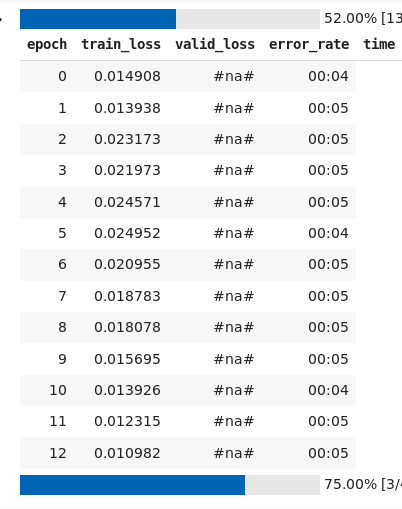
Based on the first and second lessons I have tried to build my own classifier with two classes and i’m having a problem. My trin_loss is always far greater than valid_loss no matter what i do.
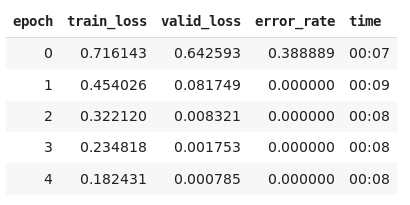
This is same even if i try to unfreeze and fit more cycles.
also i don’t get why i’m getting #na# while trying to find learning rate.
Despite all this the predict() function is giving me accurate predictions when called on completely new images.
I have used the same code used in the first lesson. The platform i’m using is colab.
Any help is appreciated.
Thanks!
Hello, How can we make load and make predictions of multiple images?
so in lesson 2 we are given way to predict single images
img = open_image(image_path)
learn = load_learner(model_path)
pred_class, pred_idx, outputs = learn.predict(img)
So how can we load multiple images (maybe from list)
is there function like
img_set = open_multiple_image(list_of_path)
or something like this?
Even I had a similar question. I actually wanted to label an unlabeled folder of images. What is the best method to do so?
Can anyone advise what is happening to this?
The YouTube totally sways off from the notebook ( ‘Cleaning Up’) part
Picture for reference.
and I’m stuck at
'ImageCleaner(ds, idxs, path) ’ and totally did not understand this portion since the notes desync from the video.
Thanks in advance.
I’m also using Google Colab btw.
Valid loss and error rate are not computed during LR find, that’s why you get NAs. Nothing is wrong here.
Train loss > Valid loss could be due to dropout (since dropout isn’t applied during validation), as long as the validation loss continues to decrease you should continue training.