That would be great to give some context, thank you!
@lesscomfortable Is there an update on a standard way to do so?  This method seems broke after we have switched to ImageDeleter. Actually, I think the current ImageDeleter may be broken too.
This method seems broke after we have switched to ImageDeleter. Actually, I think the current ImageDeleter may be broken too.
I try to hack the validation set to 0.99 so I can use the old way to clean up image, I find that ImageDeleter is actually looking for my training dataset instead of validation. If I have not misunderstood, I should pass data.valid_ds, it is weird it takes train_ds as default.
You can see in my training set I got 9 images only. And the ImageDeleter is complaining about size

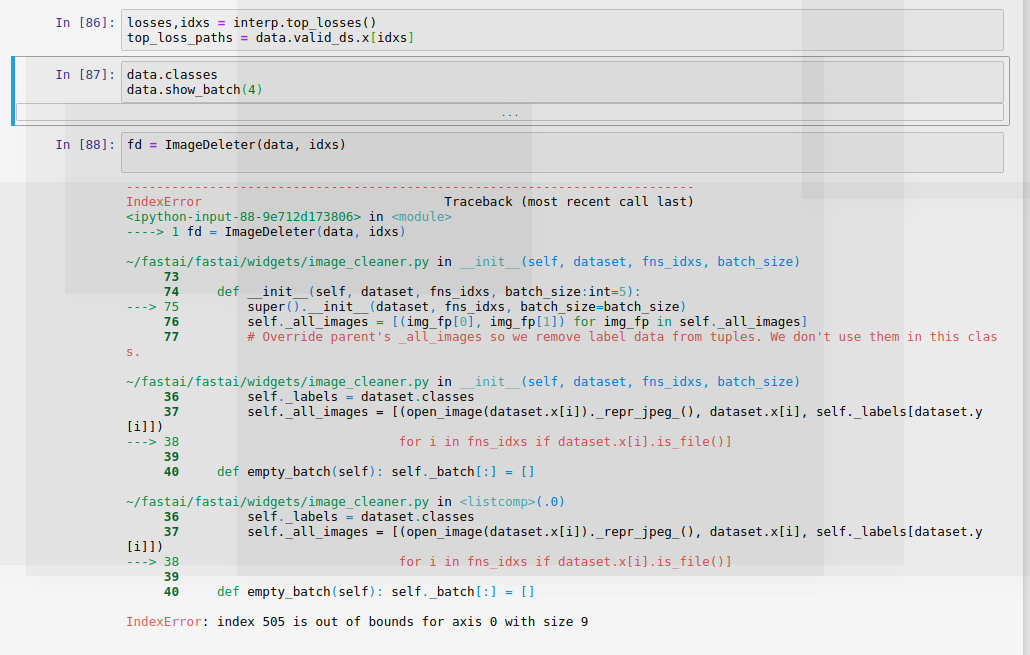
Hey @nok ! You can send data.train_ds to ImageDeleter to work on your training set. I think you are not sending the correct inputs. Please see the example usage here and let me know if it answers the question.
Thanks for the pointer, it shows the usage of ImageDeleter very well. However, I believe it may deserve a quick update in the lecture. The reason is, the lesson 2 notebooks have a commit 2 days ago simply swap the FileDeleter, the result is, it deleting wrong photo silently as the dataset was not pass correctly.
I think most people relies on notebook and only turns into doc if it throws error. It can be quite confusing especially when the changes does not break explicitly but actually cause unexpected behavior, people may simply not aware of they have deleted the wrong photo.
I also add a test for checking length of dataset match len of indexes, to make sure the correct dataset is passed. The reason why it fails silently is because training set is usually bigger than valid set, so it will just delete the wrong photo happily with no complain. I only found out this when i set valid_pct to 0.99, where it throws out of bound error.
I have made a PR to address this issue and fix the notebook. It would be great if someone can help checking on it. As I believe there are a lot of people working on their own classifier over the weekend.
2 Likes
I was having trouble getting the download images javascript code to run, and here is what I had to do:
- Disabled ad blocker, it blocked the window popup.
- Disabled Chrome Office Editing for Docs, Sheets & Slides extension as it tried to handle the csv file download and left me with blank window.
The Javascript code from the lesson2-download notebook didn’t fully work for me.
The line below generated a list of URLs that I then had to copy & paste into a .txt doc:
document.body.innerHTML = `<a href="data:text/csv;charset=utf-8,${escape(Array.from(document.querySelectorAll('.rg_di .rg_meta')).map(el=>JSON.parse(el.textContent).ou).join('\n'))}" download="links.csv">download urls</a>`;
If you want to save time opening the console & pasting in the text, you can (literally) drag-and-drop the text snippet below into your browser’s bookmarks toolbar. Then you can just click it and you will get a download button when ever you want:
javascript:document.body.innerHTML = `<a href="data:text/csv;charset=utf-8,${escape(Array.from(document.querySelectorAll('.rg_di .rg_meta')).map(el=>JSON.parse(el.textContent).ou).join('\n'))}" download="links.csv">download urls</a>`;
Josh C., who runs the East Bay MeetUp Code Self Study made & gave me the above code. Check out his meetup on Wednesdays or Saturdays:
4 Likes
Flask doesn’t have async feature.
there might be some workaround by using it with some other service. But i am not sure.
but Flask doesn’t have async feature. What did you do about that ?
Hi bluesky314,
How did you solve the problem of getting .csv instead of .txt when downloading the URLs?
1 Like
try a different browser
Can someone explain how the activation function is related to the gradient descent? I guess I don’t have a complete understanding of the activation function, and when I look it up, it messes with my understanding of gradient descent. THIS IS MY UNDERSTANDING OF SGD: A model’s goal is to find the parameters that provide the lowest cost; to do this it will start with a random set of weights, then update them based on the slope of the loss function (the gradient) at that point on the horizontal axis (seeing which direction will move it closer to the minimum), and the learning rate (how much to move in that direction). Eventually, the model will converge on the set of weights that give it around the lowest cost. When I look online, it seems that people are saying the slope of the activation function is used instead of that of the loss function, and I just don’t understand how that is true.
I guess my question can be simplified to: are gradient descent and activation functions independent of each other; if they are what are activation functions used for and is my understanding of GD correct. If they aren’t independent, how should my explanation of GD change to incorporate activation functions?
I am getting the same error with SageMaker note book instance, !pip install ipywidgets did not help, any help?
Error:
ModuleNotFoundError Traceback (most recent call last)
in
----> 1 from fastai.widgets import *
~/SageMaker/envs/fastai/lib/python3.7/site-packages/fastai/widgets/init.py in
----> 1 from .image_cleaner import *
2 from .image_downloader import *
~/SageMaker/envs/fastai/lib/python3.7/site-packages/fastai/widgets/image_cleaner.py in
7 from …callbacks.hooks import *
8 from …layers import *
----> 9 from ipywidgets import widgets, Layout
10 from IPython.display import clear_output, display
11
ModuleNotFoundError: No module named ‘ipywidgets’
was choosing generic python 3 kernel, but for sagemaker instance we need to choose conda_fastai kernel.
@jeremy is it possible to update the instructions or let me know where to submit a PR or something.
Any idea how do I upload my image urls in Colab Notebook as I do not see upload button or notebook directory structure which I usually see locally…
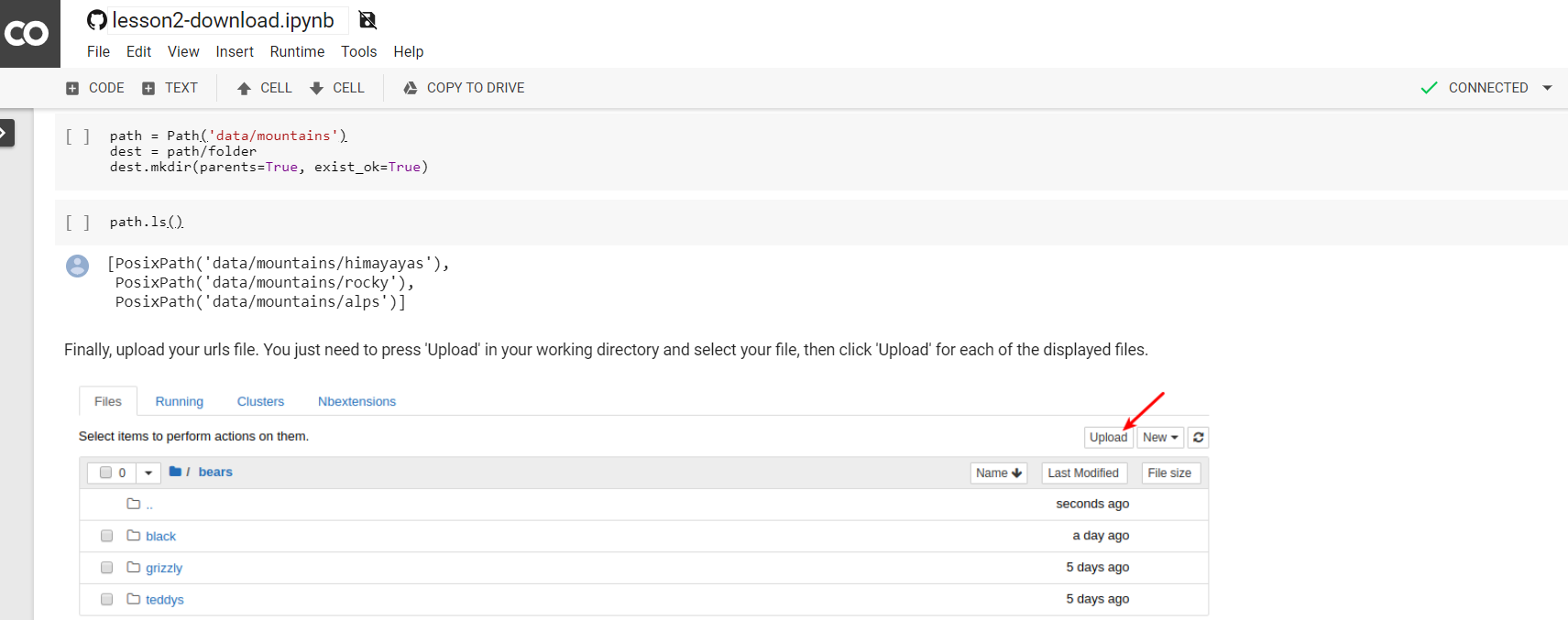
Got the answer from here Platform: Colab ✅
1 Like
Wait, wait wait, how is this  ???
???
So learner.fit_one_cycle(2, slice(lr)) is different from running twice learner.fit_one_cycle(2, slice(lr)) ???
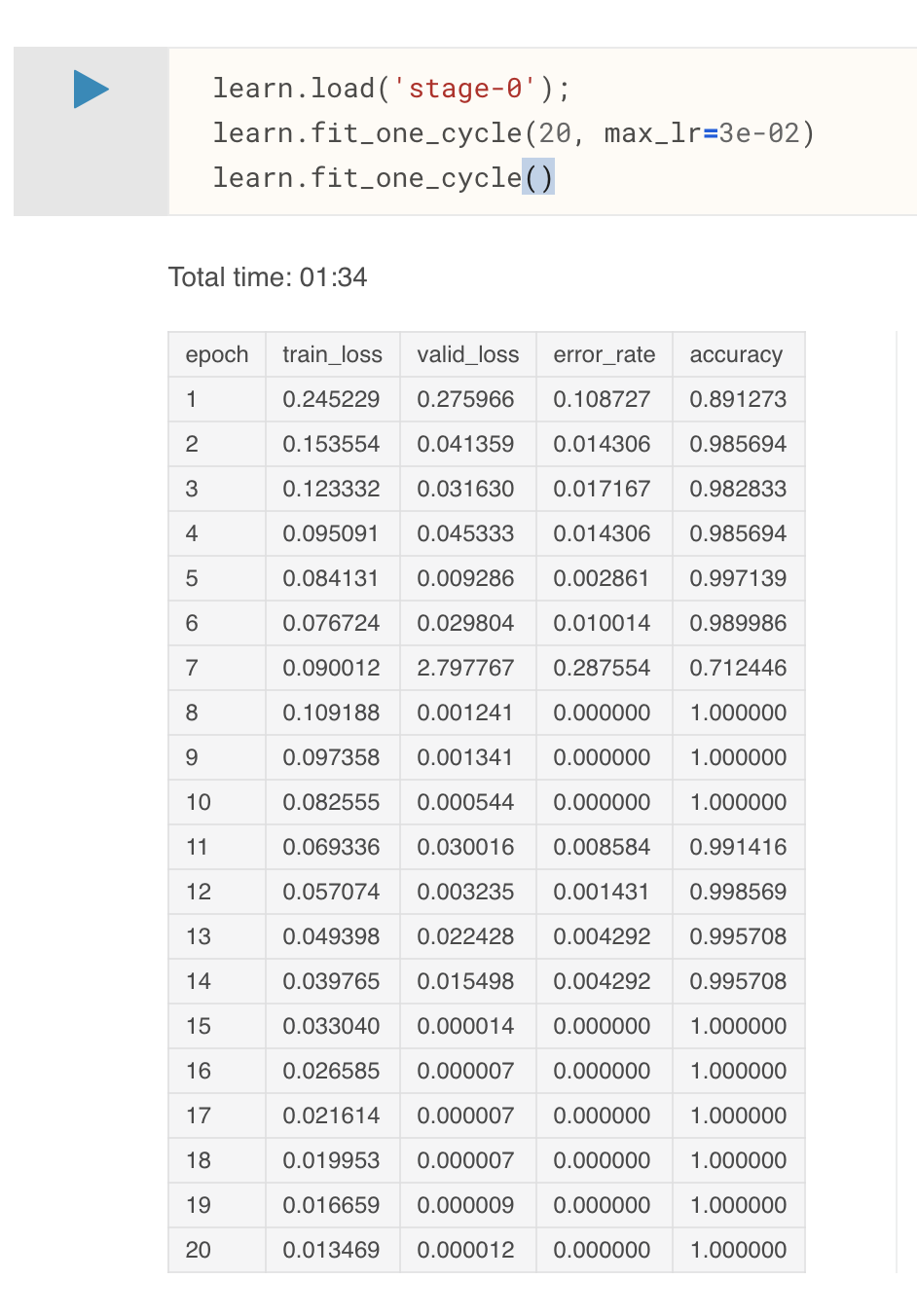
In lesson 2, Jeremy says that when you train your model and your training loss is higher then your validation loss that you have to train longer or increase the learning rate (minute 49:10). However, I have trained a resnet34 on MNIST_TINY and find that with a learning rate of 3e-02 I get 100% accuracy after around 15 epochs. However at this point the loss on my training set is still higher then on my validation set.
What’s the meaning of that?
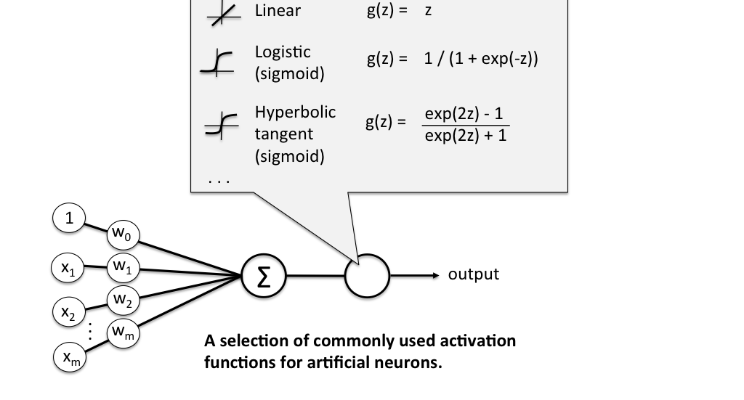
The activation function is a function which determine how nodes in a layer transform the inputs to that layer to outputs of that layer. The output of that layer is then generally used again as input for the next layer, which again has an activation function to transform it into an output.
For example, in the following image you see the inputs of a single neuron (single element of a layer) which are depicted as x1, x2, … xm (and a constant: 1), they get multiplied by their weights (w0, … wm) and summed up (depicted as the summation sign). This scalar is then put through the activation function which can for example be a linear function, logistic function, relu (not displayed) or hyperbolic tangent. The output of that function (again just a single number) is then the input (together with the outputs of all the other neurons in that layer) for the next layer
Now let’s say we have a certain set of weights for our model and we want to improve the weights of our model with gradient descent. Then we are going to do a forward pass on some training data (amount corresponding to the batch size) and see what the model predicts for each of the training items. From these predictions (and their true values) we compute the (training) loss. To update the weights we need to know the derivatives of the loss function with respect to each weight. Because the weights are related to the loss function through (a series of) activation functions this derivate will also involve derivatives of the activation function by the chain rule.
Hope this helps!
1 Like
That makes so much more sense. That also explains where the non-linearity in the model is coming in from. Thank you so much Lucas!