I used exactly the same code mentioned in Lesson 2 to download images from Google images but it downloads an empty file. I can’t understand the javascript code and not sure why it isn’t working. Did anyone else have the same issue? If yes, how did you solve?
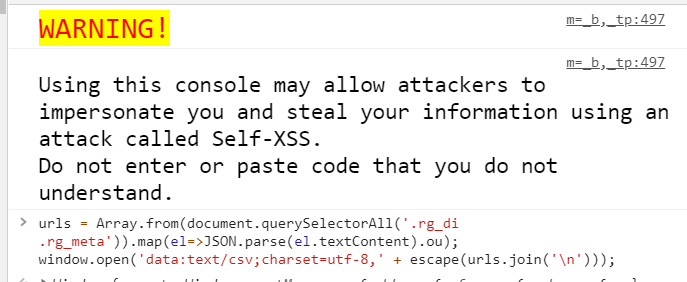
PS: The following code was ran in the java script console:
urls = Array.from(document.querySelectorAll(’.rg_di .rg_meta’)).map(el=>JSON.parse(el.textContent).ou);
window.open(‘data:text/csv;charset=utf-8,’ + escape(urls.join(’\n’)));
If I searched with “cn.bing.com” and then executed the script : elements = document.querySelectorAll(’.mimg’) var urls = []; for (var i = 0; i < elements.length; i++) {
**var url = elements[i].getAttribute(‘src’) ** if (url&&url.includes(‘https’)) { urls.push(URL); } } window.open(‘data:text/csv;charset=utf-8,’ + escape(urls.join(’\n’)));
the download file was many lines of the same string:
function URL() { [native code] }
function URL() { [native code] }
function URL() { [native code] }
I too have that problem and I have tried going Incognito , reinstalling Chrome , nothing seems to work , the file that gets downloaded is still 0 KB . Kindly help , Thank you !!
Below is the code i used
you can use (cn.bing.com) to download images by this code.
elements = document.querySelectorAll(’.mimg’)
var urls = [];
for (var i = 0; i < elements.length; i++) {
var url = elements[i].getAttribute(‘src’)
if (url&&url.includes(‘https’)) {
urls.push(url);
}
}
window.open(‘data:text/csv;charset=utf-8,’ + escape(urls.join(’\n’)));
It seems that Google has modified/optimized their image search results so it’s harder to extract image urls from the DOM attributes. I instead used DuckDuckGo image search, and modified the first line of the Javascript code to be urls = Array.from(document.querySelectorAll('.tile--img__img')).map(el=> el.hasAttribute('data-src')? "https:"+el.getAttribute('data-src'):"https:"+el.getAttribute('src'));
I found this useful and I downloaded successfully. Try my code if neccessary. var urls=Array.from(document.querySelectorAll('.rg_i')).map(el=> el.hasAttribute('data-src')?el.getAttribute('data-src'):el.getAttribute('data-iurl')); var hiddenElement = document.createElement('a'); hiddenElement.href = 'data:text/csv;charset=utf-8,' + encodeURI(urls.join('\n')); hiddenElement.target = '_blank'; hiddenElement.download = 'myFile.csv'; hiddenElement.click();
I used this, but it seems to just list the urls instead of downloading them directly to a folder. Has anyone found a way to modify the code so it directly downloads?
// Google Images
var urls=Array.from(document.querySelectorAll(“.rg_i”)).map(el=>el.hasAttribute(“data-src”)?el.getAttribute(“data-src”):el.getAttribute(“data-iurl”)).filter(l=>l!=null).join(“\n”);
var a = document.createElement(“a”);a.download = “filename.txt”;a.href = “data:text/csv;charset=utf-8,”+urls;a.click();
// DuckDuckGo Images (uses Bing)
var urls=Array.from(document.querySelectorAll(“.tile–img__img”)).map(el=>el.hasAttribute(“data-src”)?el.getAttribute(“src”):el.getAttribute(“data-src”)).filter(l=>l!=null).map(l=>“https:”+l).join(“\n”);
var a = document.createElement(“a”);a.download = “filename.txt”;a.href = “data:text/csv;charset=utf-8,”+urls;a.click();
// Bing Images
var urls=Array.from(document.querySelectorAll(“.mimg”)).map(el=>el.hasAttribute(“src”)?el.getAttribute(“src”):null).filter(l=>l!=null&&l.startsWith(“http”)).join(“\n”);
var a = document.createElement(“a”);a.download = “filename.txt”;a.href = “data:text/csv;charset=utf-8,”+urls;a.click();
{kind=link}