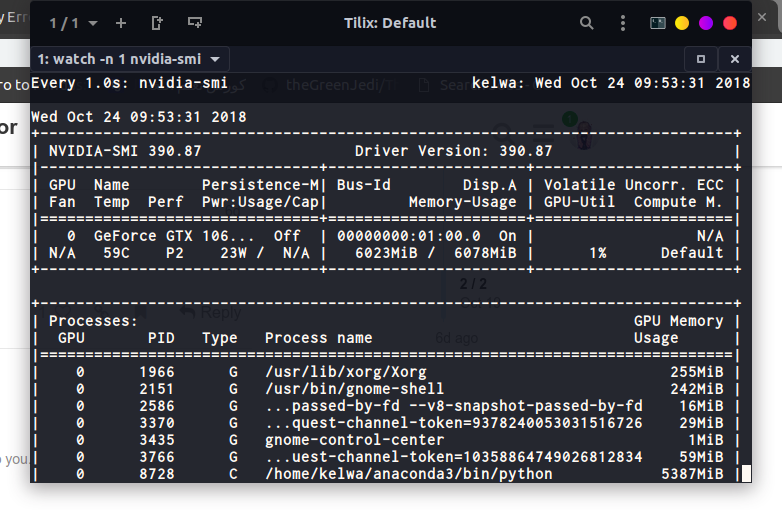
Whenever, I run the line learn = ConvLearner.pretrained(arch, data, precompute=True), I am running out of memory. Any suggestions?
Machine:
Paperspace GPU+
RAM: 30 GB
CPUS: 8
GPU: 8 GB
RuntimeError Traceback (most recent call last)
in
----> 1 learn = ConvLearner.pretrained(arch, data, precompute=True)
~/fastai/courses/dl1/fastai/conv_learner.py in pretrained(cls, f, data, ps, xtra_fc, xtra_cut, custom_head, precompute, pretrained, **kwargs)
112 models = ConvnetBuilder(f, data.c, data.is_multi, data.is_reg,
113 ps=ps, xtra_fc=xtra_fc, xtra_cut=xtra_cut, custom_head=custom_head, pretrained=pretrained)
–> 114 return cls(data, models, precompute, **kwargs)
115
116 @classmethod
~/fastai/courses/dl1/fastai/conv_learner.py in init(self, data, models, precompute, **kwargs)
98 if hasattr(data, ‘is_multi’) and not data.is_reg and self.metrics is None:
99 self.metrics = [accuracy_thresh(0.5)] if self.data.is_multi else [accuracy]
–> 100 if precompute: self.save_fc1()
101 self.freeze()
102 self.precompute = precompute
~/fastai/courses/dl1/fastai/conv_learner.py in save_fc1(self)
177 m=self.models.top_model
178 if len(self.activations[0])!=len(self.data.trn_ds):
–> 179 predict_to_bcolz(m, self.data.fix_dl, act)
180 if len(self.activations[1])!=len(self.data.val_ds):
181 predict_to_bcolz(m, self.data.val_dl, val_act)
~/fastai/courses/dl1/fastai/model.py in predict_to_bcolz(m, gen, arr, workers)
16 m.eval()
17 for x,*_ in tqdm(gen):
—> 18 y = to_np(m(VV(x)).data)
19 with lock:
20 arr.append(y)
~/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/modules/module.py in call(self, *input, **kwargs)
475 result = self._slow_forward(*input, **kwargs)
476 else:
–> 477 result = self.forward(*input, **kwargs)
478 for hook in self._forward_hooks.values():
479 hook_result = hook(self, input, result)
~/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/modules/container.py in forward(self, input)
90 def forward(self, input):
91 for module in self._modules.values():
—> 92 input = module(input)
93 return input
94
~/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/modules/module.py in call(self, *input, **kwargs)
475 result = self._slow_forward(*input, **kwargs)
476 else:
–> 477 result = self.forward(*input, **kwargs)
478 for hook in self._forward_hooks.values():
479 hook_result = hook(self, input, result)
~/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/modules/container.py in forward(self, input)
90 def forward(self, input):
91 for module in self._modules.values():
—> 92 input = module(input)
93 return input
94
~/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/modules/module.py in call(self, *input, **kwargs)
475 result = self._slow_forward(*input, **kwargs)
476 else:
–> 477 result = self.forward(*input, **kwargs)
478 for hook in self._forward_hooks.values():
479 hook_result = hook(self, input, result)
~/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/modules/container.py in forward(self, input)
90 def forward(self, input):
91 for module in self._modules.values():
—> 92 input = module(input)
93 return input
94
~/anaconda3/envs/fastai/lib/python3.6/site-packages/torch/nn/modules/module.py in call(self, *input, **kwargs)
475 result = self._slow_forward(*input, **kwargs)
476 else:
–> 477 result = self.forward(*input, **kwargs)
478 for hook in self._forward_hooks.values():
479 hook_result = hook(self, input, result)
~/fastai/courses/dl1/fastai/models/resnext_101_64x4d.py in forward(self, input)
26 class LambdaReduce(LambdaBase):
27 def forward(self, input):
—> 28 return reduce(self.lambda_func,self.forward_prepare(input))
29
30
~/fastai/courses/dl1/fastai/models/resnext_101_64x4d.py in (x, y)
116 ),
117 ),
–> 118 LambdaReduce(lambda x,y: x+y), # CAddTable,
119 nn.ReLU(),
120 ),
RuntimeError: CUDA error: out of memory