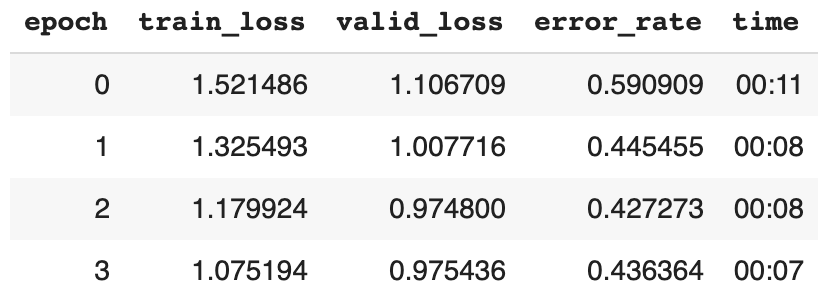
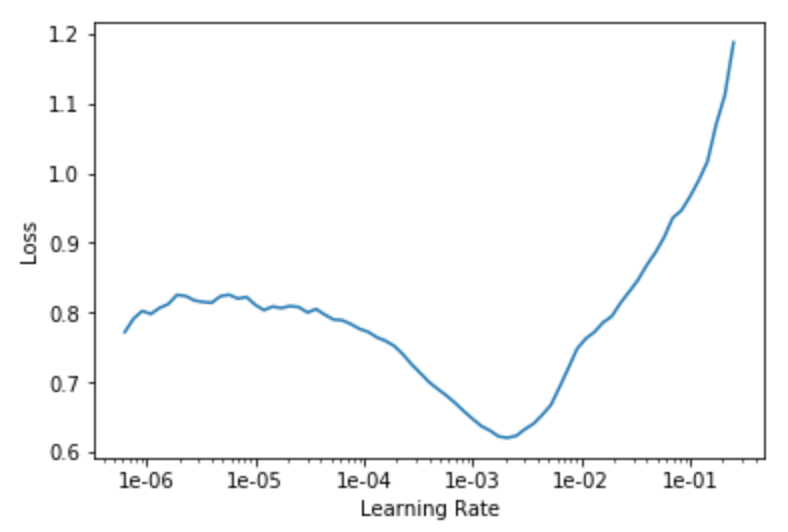
Working with lesson2-download.ipynb, I tried training a model to classify the make of a sedan: Honda vs Toyota vs Hyundai. However, I could not get an accuracy more than 75% at the end of 2-stage training. Here are some results from the training process.
Try increasing image size. The main feature that helps the model classify the cars probably is the logo which is usually very small. Using larger images might help you with that.
Hey Shivam,
I’m working on a similar classifier for recognizing 1960 to 1962 Corvettes (which was kind of a terrible idea but I’m having fun). The best error rate I got was around 14%. I can’t really help you with the math but here are some thoughts.
Did you look at your top losses with interp.plot_top_losses()? I had a lot of problems because the real distinguishing features of my cars were the front grill and the rear tail lights. The way the lesson crops the images, they center the pic on the middle of the car which is probably the least interesting part of the image. I changed size=448 in ImageDataBunch.from_folder() method.
Can you tell the difference in your top losses? Some of my losses were from me asking an impossible question. For example, the rear end of a 1961 and a 1962 Corvette are exactly the same.
How good is your data set? I scrapped using the Google url method in the lesson and uploaded high quality pristine examples. I was having a problem with a lot of people modifying their cars with parts and paint schemes from different years. I now have a problem now with my data set being small but it is very good.
While writing this, I went back and looked at some of my early plots. You loss plot looks very similar to my first run with a ton of crappy images. It’s just a guess but I bet you are asking an overly broad question with limited data. You want it to classify Honda, Toyota, Hyundai sedans. Let’s say they each make 10 models a year for 50 years. That is 1500 makes of cars and you probably have a data set of around 600 images? Try limiting your model years or increasing your number of images.
I feel that the 75% accuracy is good indeed because looking at the images it is difficult even for a manual labeller to predict the correct car make. Adding more images that has distinctive features might help.
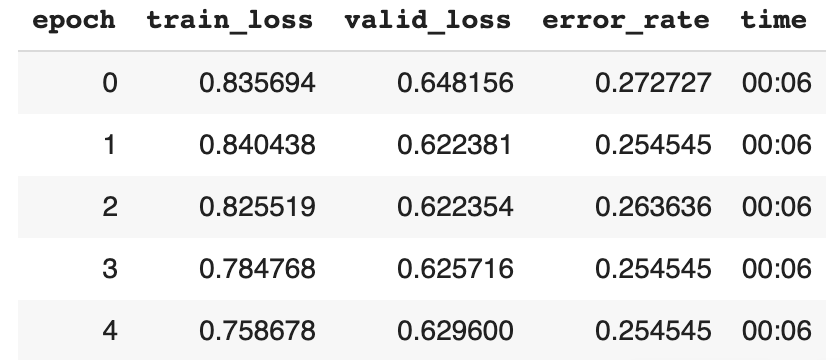
Thanks Mark and Dave, looks like I was working with the latest notebook, which no longer has the code snippet for plotting top losses. I grabbed it from the video lecture and here are the results:
I see that some of the images are clearly hard to classify: (1,0), (1,1) are heavily cropped; (0, 2) has two cars in one image. I should clean up the data. Since I’m working in Google Colab, the ImageCleaner() doesn’t work, so I need to figure out another way of doing this.
Also, good point about data being too small and very diverse in terms of the make of the car. In that context, I feel 75% is a decent accuracy
UPDATE: Doubling the image size to 448, leads to overfitting (trail_loss ~ 0.6, val_loss ~ 0.4)
I agree 75% is a win. My secret suspicion why the CNN doesn’t converge nicely is we chose a rectangular object and made it square. So we either have a severely cropped image with a lot of information that isn’t interesting or a full image with half the array containing blank information. With more data, I’m sure it would come together but seems like a lot of work for not much reward in the learning department.
Depending on your level of obsession, it might be interesting to move on to lesson 3 and see if you can get something to label grills, emblems, wheels, etc then get the net to focus on those elements. I believe the tools are there, we just don’t understand them yet.