The coefficients come from the equation for q(\mathbf{x}_{t-1} | \mathbf{x}_{t}, \mathbf{x}_{0}):
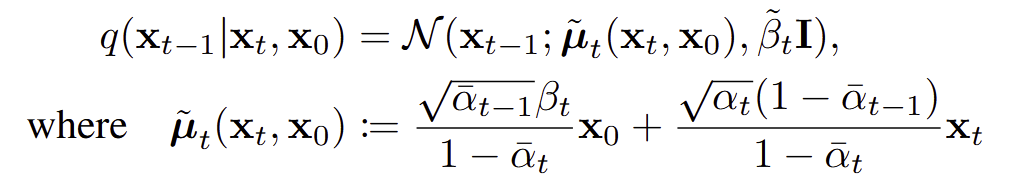
What this equation tells us is how \mathbf{x}_{t-1} is distributed given \mathbf{x}_0 (which we get an estimate of) and \mathbf{x}_{t}.
The loss function math demonstrates that the mean of our reverse process distribution should match the mean of q(\mathbf{x}_{t-1} | \mathbf{x}_{t}, \mathbf{x}_{0}) :
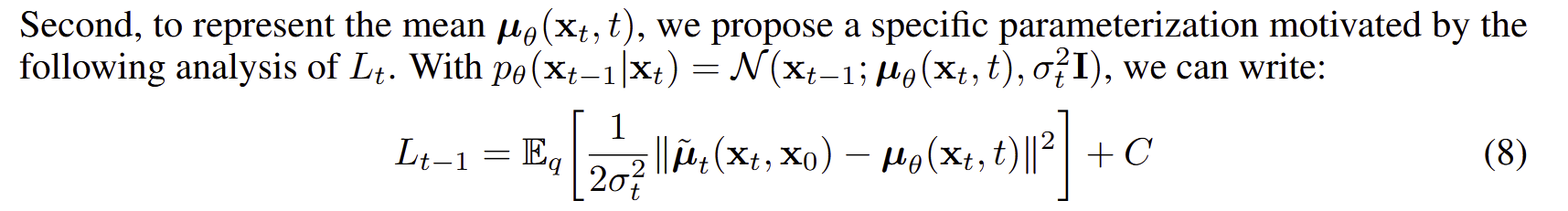
Therefore, our model must learn to predict \tilde{\mathbf{\mu}}_t, which it does by predicting the noise to remove from \mathbf{x}_t to get an estimate of \mathbf{x}_0 which we plug into that equation for to finally get our mean \tilde{\mathbf{\mu}}_t for q(\mathbf{x}_{t-1} | \mathbf{x}_{t}, \mathbf{x}_{0}).
Hope this is clear! Let me know if you have any other questions!