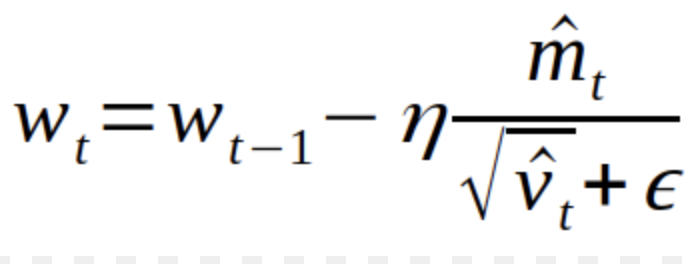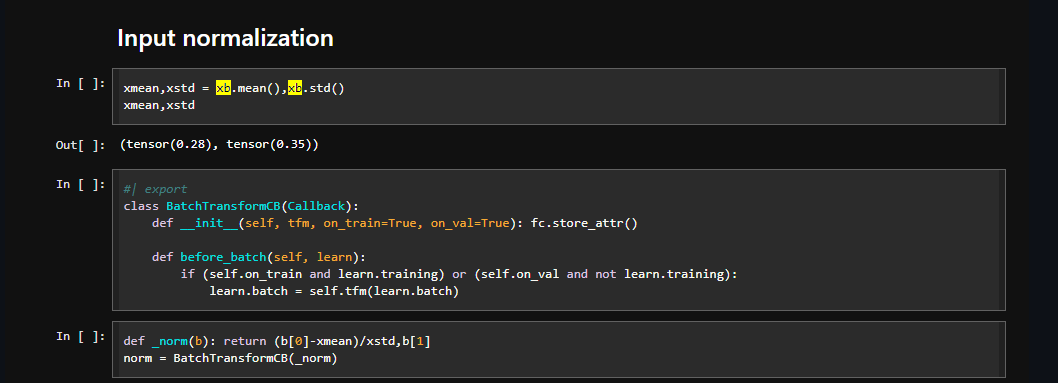
why are we using some predefined value for batch transform and not calculating xb.mean() and xb.std() before ever batch.
1 Like
Yess! Finally someone noticed this bit. I wrote the norm function but with the mean and the standard deviation of the batch itself, but the performance dropped significantly. Super odd.