I am trying to reproduce the results from Lesson 14 with a different dataset (original images at different resolutions from 964 × 672 up to 4288 × 2848).
I train with 128x128 size and get a dice of 0.899197. Then when I try to load this model for 512x512, it doesn’t start at 0.899197, but at 0.785793
In @jeremy 's notebook, increasing the resolution only improves the result.
Can anyone suggest what might be happening here? What can I do to prevent this loss in accuracy?
I have not played around with this but if you think about this, it’s hard to expect that a model trained at some resolution will perform as well / better when run on images with a different resolution.
The features that it learns should be most useful for discerning images at the resolution it was trained on.
I think the reasoning is more along the lines that we want to pretrain the model on lower resolution to have a good starting point for training on higher resolution images. BTW the jump from 128x128 to 512x512 is really, really big. Might make benefiting from features learned at lower resolution harder. Might be worth trying to go from 128 -> 256 -> 512 and ensuring the model is well trained at each of the phases before proceeding on the next one (just a hunch - might be worth to experiment with this).
If I understand this correctly, model’s performance should increase as we step up the resolution but only after we train for a while with the new resolution.
It’s a feature of the Carvana dataset: shape of a car looks almost the same both at 128x128 and 512x512 resolutions. As was suggested you should probably jump to 256 x256 first. Plus Jeremy freezes most of weights at the start of training at 512.
I work on a segmentation problem as well and ran into a problem with tfms_from_model() function. Judging by documentation it has SZ and SZ_Y parameters, latter of which I assumed to be of use, when I don’t want to use square images and prefer rectangular. But somehow it looks like SZ_Y controls image size for target since I get exception “Target size (torch.Size([4, 2048, 2048])) must be the same as input size (torch.Size([4, 512, 512]))” after setting sz=512, sz_y=2048, even though looking at image_gen() function SZ and SZ_Y should be width and height of the image.
Is there a way to use non-square images during learning?
Thanks @radek, I was wondering the same thing. By the way, do you know how do you use learn.TTA within a segmentation problem? Is it possible?
If I use learn.TTA(n_aug=2), its output are 3 segmentations, 1 from the input image not transformed and 2 transformed by augmentation transformations. That is not what I was expecting, I supposed when I used tfm_y=CLASS it would detransform the augmented inputs. Not what is happening.
Sorry, I have not played with this. I am not sure I fully understand the situation, but generally this is how TTA works - for the final prediction you would take say 0.6 of the prediction of unaugmented inputs and say 0.2 times each of the predictions with augmentations. Or you might take some other number of predictions with augmentations and combine them using some other ratio. This generally tends to give better results than just taking a single prediction on the unaugmented input.
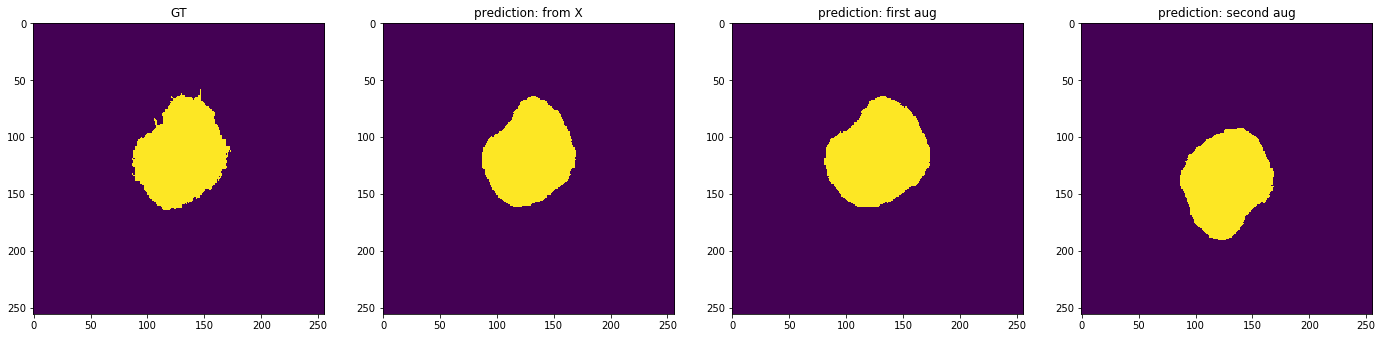
GT and prediction without augmentation are very similar. But if you analyse GT versus the 4th image (2nd augmentation), the prediction is upside down.
This is because the TTA is applying transforms to the input image. That is ok. The problem is that the result is given for the augmented input, not the original input. So, predictions of augmentations (images 3 and 4) are useless.
They could be useful if which functions were applied in those augmentation and how to apply the inverse of that transform.
Ah I see now! From the top of my head I don’t see how TTA could be leveraged here but I have not done much with segmentation so hard to say what people are doing to improve on the results and whether they use any sort of ensembling. Probably the write up on the winning solution to the Kaggle caravana challenge might make for an interesting read.
Sorry, I am not quite following. You say that you expect detransformed augmented inputs, but isn’t the detransform of an augmented input the input image itself by definition?
Would you like to have recording of exact augmentation params for each single image?
Trying to understand what exactly are you trying to achieve with TTA.
I can’t imagine why TTA wouldn’t be possible, but you may need to do some data munging (eg see lesson 8 and 9) to make targets move with the transform, or make some changes to the library.
I’m working on a segmentation problem at the moment. u-net isn’t great at predicting near borders, so I’m using sliding windows in the train set, and padding with image mirrors the test set. You can also use different channel mixes if you have more than 1 channel, and different window/tile sizes, as data augmentation.I’m also using a pytorch SoftDiceLoss which seems to be better than crossentropyloss alone. These are a few ways to move beyond the lesson 14 carvana solution.
It’s not unusual to see the initial loss increase and accuracy drop when you move to a larger image size. You need to find the right hyper parameters to achieve a better result when increasing. In some cases I’ve not had a better result going from 512-1024.
That is very interesting. I tried implementing a soft_jaccard_loss, but the result was worse than BCEWithLogitsLoss and I believe the problem was in my implementation. I saw several soft_jaccard implementations and none applied regularization to prevent output complexity.
You mean using tfm_y=tfm.CLASS? I didn’t follow. I guess what I need is to make the predictions be transformed back. Is that what you are saying?
I saw a post about Carvana comp, where it appears SoftDiceLoss should be in nn.losses module, but docs neither for Pytorch 0.3, nor for 0.4 show such a module. I think, I have 0.3 that fastai asks for during pip install.
Code I had in previous post comes from Pytorch github repo: during one of PR discussions one of PT maintainers posted it. Aside from nn.BCEWithLogitsLoss().forward(inp, tar), which I obviously added myself. The loss the way I implemented it oscillates wildly in range from -50 to hundreds, which dice loss shouldn’t, since it’s locked from 0 to 1.
You’ve got pretty noble wish, but to my understanding not all transforms are deterministically reversible. eg resize: while resizing smaller we lose information and there is no way to get that information back if you want to reverse.
I would be nice feature though, I remember seeing that feature somewhere in an augmentation library, can’t find it though. I vaguely remember seeing library where you had to define both methods: transform and reverse-transform when initializing.
Looked into these but didn’t find:
‘https://github.com/mdbloice/Augmentor’
‘https://github.com/aleju/imgaug’
I am now trying to use the dice loss you mentioned.
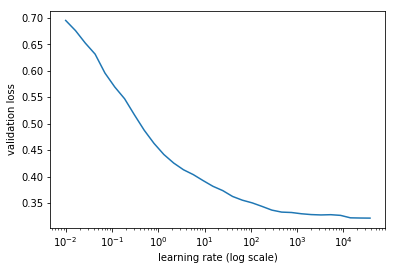
The problem is that it gives a very strange curve when I learn.lr_find:
I set the lr to 1e2 and it didn’t converge.
I then set to 1e-1 and it converged better but was still worse than BCEWithLogitsLoss with a very good learning rate setting.