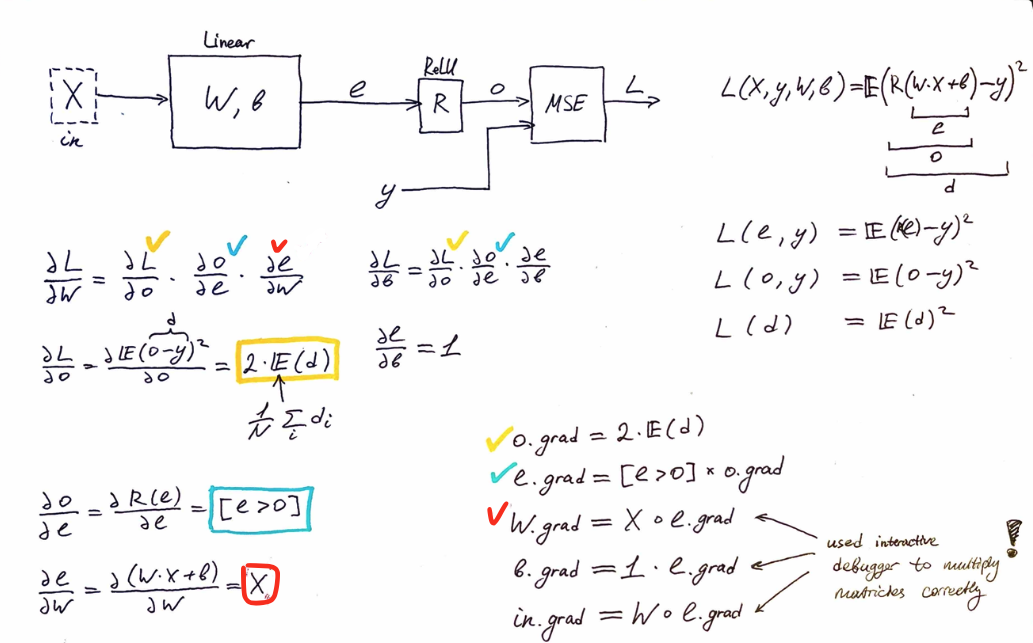
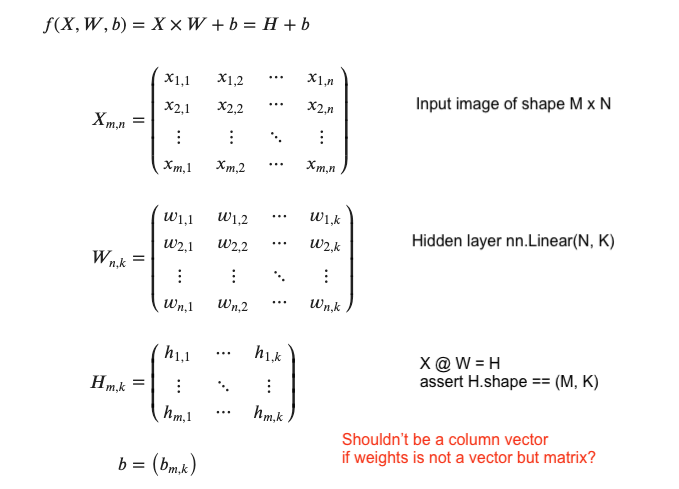
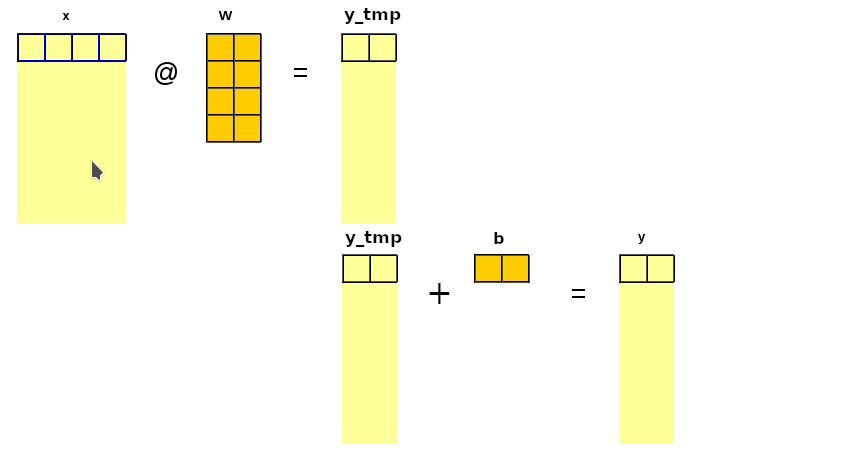
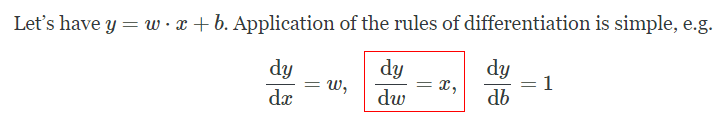I have added some outputs (within 03_backprop.ipynb) and simplified training set to dum it down as much as possible and track every single step happening on forward&backward pass. It helped me a lot! Here it is:
# dummy training set
x_train = tensor([[1.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,1.0],
[1.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,1.0],
[1.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,0.0,1.0],
[0.0,0.0,0.0,1.0,0.0,1.0,0.0,0.0,0.0,0.0],
[0.0,0.0,0.0,1.0,0.0,1.0,0.0,0.0,0.0,0.0],
[0.0,0.0,0.0,1.0,0.0,1.0,0.0,0.0,0.0,0.0],
])
y_train = tensor([1,1,1,0,0,0])
x_valid, y_valid = x_train[:5], y_train[:5]
# predefined simple initial weights so you can track calculations
w1 = tensor([[1.0, 0.],
[1., 0.],
[-1., -1.],
[-1., 1.],
[-1., -1.],
[0., 0.],
[-1., 0.],
[0., 0.],
[-1., 0.],
[0., 0.],])
b1 = torch.zeros(nh)
w2 = tensor([[-1.0],
[ 1.0]])
b2 = torch.zeros(1)
### [...]
# and finally two main functions modified with some output
def lin_grad(inpt, outpt, ww, bb, inpt_n, outpt_n, ww_n, bb_n):
print("*lin_grad(inpt, outpt, ww, bb)*")
# grad of matmul with respect to input
print("{}.t:".format(ww_n),ww.t())
inpt.g = outpt.g @ ww.t()
print("~~~{}.g = {}.g @ {}.t():".format(inpt_n,outpt_n,ww_n),inpt.g)
#print("{}.unsqueeze(-1):".format(inpt_n),inpt.unsqueeze(-1))
ww.g = (inpt.unsqueeze(-1) * outpt.g.unsqueeze(1)).sum(0)
print("~~~{}.g = ({}.unsqueeze(-1) * {}.g.unsqueeze(1)).sum(0):\n".format(ww_n,
inpt_n, outpt_n)
,ww.g)
bb.g = outpt.g.sum(0)
print("~~~{}.g = {}.g.sum(0):\n".format(bb_n,outpt_n),bb.g)
return ww.g, bb.g
def forward_and_backward(inp, targ):
# forward pass:
l1 = inp @ w1 + b1
print("l1 = inp @ w1 + b1:",l1)
l2 = relu(l1)
print("l2 = relu(l1):", l2)
out = l2 @ w2 + b2
print("out = l2 @ w2 + b2:", out)
diff = out[:,0]-targ
print("diff = out[:,0]-targ:", diff)
loss = diff.pow(2).mean()
print("\n**** !!! loss = diff.pow(2).mean():", loss)
#pdb.set_trace()
# backward pass:
print("\n***backward pass***")
out.g = 2.*diff[:,None] / inp.shape[0]
print("out:",out)
print("out.g = 2.*diff[:,None] / inp.shape[0]:",out.g)
print("\n*working on l2*")
print("lin_grad(l2, out, w2, b2):")
w2_grad, b2_grad = lin_grad(l2, out, w2, b2,
inpt_n="l2",
outpt_n="out",
ww_n="w2",
bb_n="b2")
print("\n*working on l1*")
print("(l1>0).float():",(l1>0).float())
l1.g = (l1>0).float() * l2.g
print("l1.g = (l1>0).float() * l2.g:",l1.g)
print("lin_grad(inp, l1, w1, b1)")
w1_grad, b1_grad = lin_grad(inp, l1, w1, b1,
inpt_n="input",
outpt_n="l1",
ww_n="w1",
bb_n="b1")
return w2_grad, b2_grad, w1_grad, b1_grad
# call it
w2_grad, b2_grad, w1_grad, b1_grad = forward_and_backward(x_train, y_train)
# and you can also make another call after updating weights and see how loss changes
lr = 0.5
w1 = w1 - w1_grad*lr
b1 = b1 - b1_grad*lr
w2 = w2 - w2_grad*lr
b2 = b2 - b2_grad*lr
Hope this can help someone as helped me.