Just a quick tip for anyone training the Attention models discussed in Lesson 13.
I noticed my models were taking awhile to train and the GPU was only running about 20%. So I started doubling batch sizes until my GPU utilization hit 90%, about batch size 4096.
My training time went from 8 min per epoch to 13 seconds.
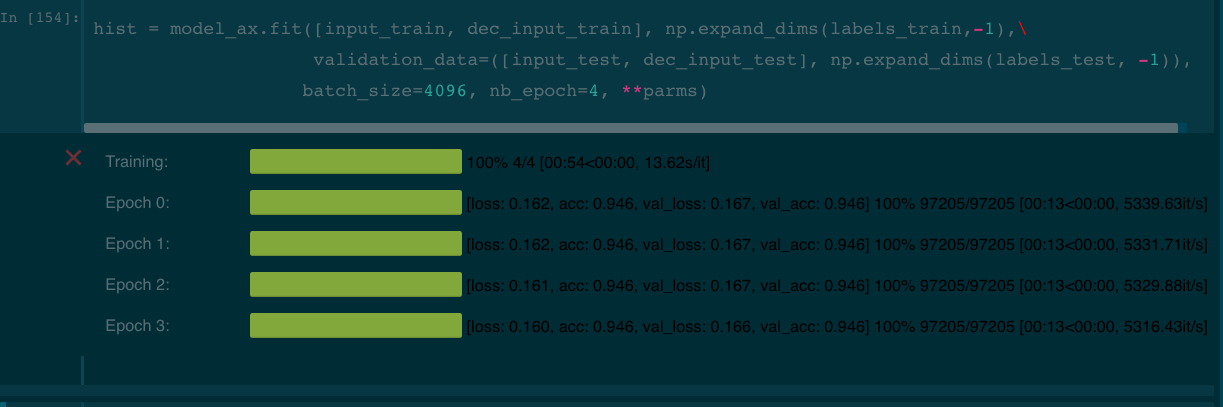
I have a GTX 1080 Ti.