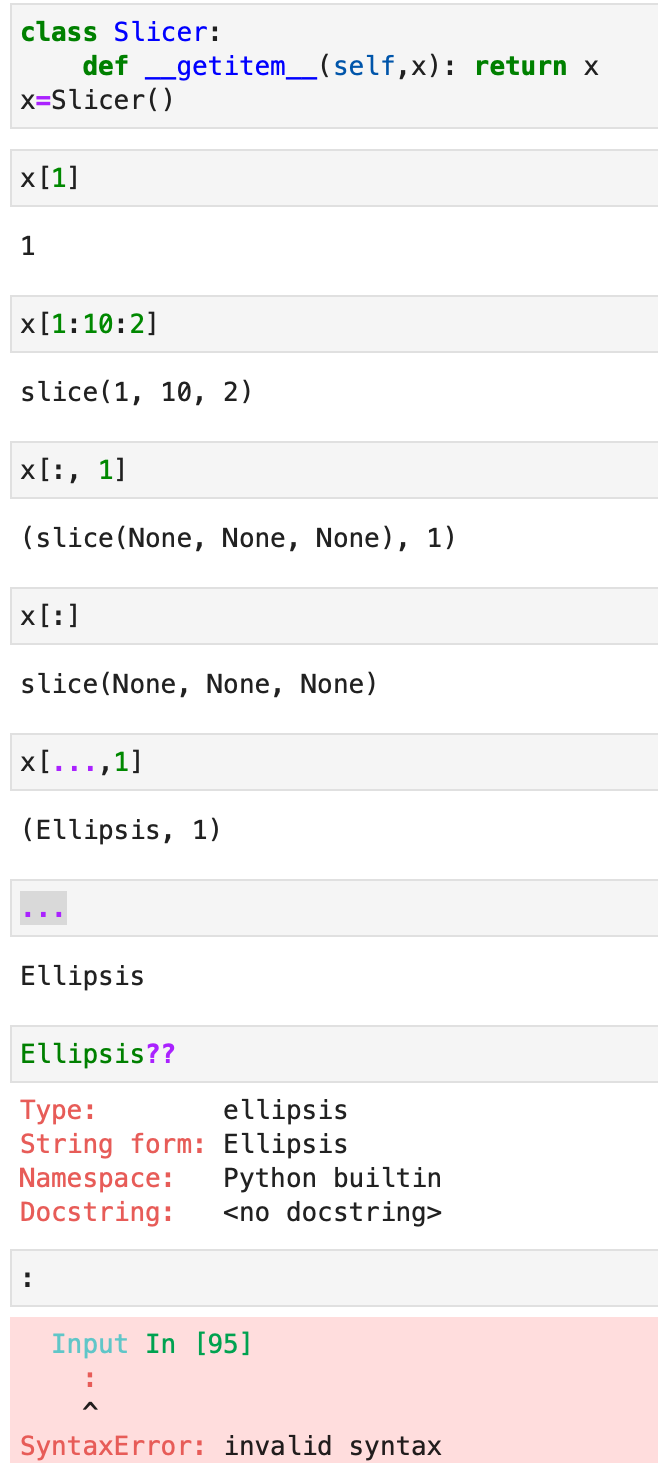
A few of us had a go at Jeremy today for explaining the Chain Rule by writing
\frac{dy}{dx} = \frac{dy}{du} \frac{du}{dx}
and “cancelling out” the du's — which isn’t kosher, because a derivative isn’t really a fraction! (It’s just the limit of a fraction.)
So what would be a kosher way of understanding the chain rule? Well, I think the way to think about it is to think of a derivative as “replacing” a curve by a linear function that is tangent to the curve at a given point: e.g. f(x) \approx \frac{df}{dx}(x_0)x + \text{some constant} for values of x close to x_0.
Now, what happens if we compose two linear functions? Let’s try it with f(x) = mx + c and g(x) = nx + d:
g(f(x)) = n(mx + c) + d = nmx + nc + d.
So what’s the slope of the composite function? It’s nm, which is the product of the slopes of the two component functions!
To bring everything full-circle, let’s say we want to compute \frac{dy}{dx} at some value x=x_0; and let’s say that u_0 is the value of u corresponding to x_0. Then we have
y \approx \frac{dy}{du}(u_0)u + c
for some constant c, and values of u close to u_0; and
u \approx \frac{du}{dx}(x_0)x + d
for some constant d, and values of x close to x_0. Composing the two, we have
y \approx \frac{dy}{du}(u_0)\left(\frac{du}{dx}(x_0)x + d\right) + c = \frac{dy}{du}(u_0)\frac{du}{dx}(x_0)x + \text{some stuff}.
Since this is true for any arbitrary value of x_0, and since u_0 is uniquely determined by x_0, we can drop both u_0 and x_0 from the above expression. Thus we see that the slope of y with respect to x — i.e. \frac{dy}{dx} — is nothing more than \frac{dy}{du} \frac{du\vphantom{y}}{dx}! No cancellation required.