12_text.ipynb is the name of the nb
Were you able to solve/address this issue? Seems like in newer Pytorch version(s) index of 0-dim tensor is invalid. So the IndexError complain with idx[0], bool
"That’s because in PyTorch >=0.5, the index of 0-dim tensor is invalid.
I tried isinstance(idx[0].item(),bool): and that continues to give the same error.
Has anyone else figured out the fix with the current version of fastai yet?
I have been unable to address this problem either and so am dead in water too? I am on Google colab? Are you on some other platform. One other person has told me that they are able to work through this notebook without this problem and they were on a local machine with a GPU.
Any pointers anyone on how to fix/address move past this issue for the 12_text.ipynb notebook?
I revised and extended the discussion on label smoothing in the 10_b_mixup_label_smoothing_jcat.ipynb notebook.
A Note on Label Smoothing
Another regularization technique that’s often used is label smoothing. The basic idea is to make the model a little bit less certain of its decision. Here we describe two approaches:
Method #1 (section 5.2 in the “Bag of Tricks” paper)
We effectively add noise to the training labels by replacing each target label with a mixture distribution, with weights of 1-\varepsilon for the case where the label is the correct class and \varepsilon for the case where the label is distributed uniformly among the incorrect classes. We choose \varepsilon to be a positive number that is much smaller than one (0.1 by default), so that the mixture is dominated by the case with the correct training label. This leads to the following loss function:
loss = (1-\varepsilon) \ell(i) + \varepsilon \sum_{k \ne i} \frac{\ell(k)}{K-1}
where \ell(k) = -\log(p_{k}) is the cross-entropy loss for class k, K is the number of classes, and i is the correct class.
Method #2 (original description of label-smoothing, from section 7 of the “Inception” paper)
Again we form a mixture distribution, this time with weights of 1-\varepsilon for the case where the label is the correct class and \varepsilon for the case where we know nothing about the label. The latter case is represented by assuming the label is distributed uniformly across the K classes. Again, since \varepsilon is a small probability, the mixture is dominated by the correct case. This leads to a slightly different loss function:
loss = (1-\varepsilon) \ell(i) + \varepsilon \sum_{k=1}^K \frac{\ell(k)}{K}
We implemented both methods for comparison, and performed a set of of ten single-epoch training runs for each. We found that the resulting accuracies for the two methods are statistically indistinguishable, i.e. both methods give essentially the same result.
Label smoothing Method #2 is the one that’s implemented in the notebook.
Does Label-smoothing improve accuracy?
I performed a test and wrote up the results in a Conclusion section:
We performed 10 single-epoch training runs each without label-smoothing and with label-smoothing.
Without label smoothing the mean and standard deviation in accuracy are: 0.264 and 0.082
With label smoothing the mean and standard deviation in accuracy are: 0.306 and 0.055
The standard deviations in the means are
\sigma_{MeanAccuracyWithoutLS} = \frac{0.082}{\sqrt 10} = 0.03, and
\sigma_{MeanAccuracyWithLS} = \frac{0.055}{\sqrt 10} = 0.02
The accuracies are therefore
0.26\pm0.03 without label smoothing
0.31\pm0.02 with label smoothing
The results are different by about two standard deviations, showing that label-smoothing significantly improves accuracy!
It appears that the problem seems to originate with use of tensors as idxs in SortishSampler in the 12_text.ipynb. I saw that fastai V1 library uses ndarray rather than tensors in its SortishSampler code and so I replaced the SortishSampler code in 12b_text code with the library (numpy ndarray based code) and just as a precaution, I also changed in the pad_collate code from the library (it has an additional feature but that should not hinder current use in this nb). Having done that I re-ran nb only to encounter
IndexError: invalid index to scalar variable.in the code of ListContainer.
Is there a workaround to using tensors in SortishSampler that works in the context of the V3 lesson nbs that anyone is aware since the V1 library seems to sidestep this issue by avoiding the use of ListContainer class and re-defining the ItemList class comprehensively. I am hesitant to go that route of using a completely new ItemList class as I am concerned about what other unknown dependencies embedded in the NBs that I will be breaking.
I direly need some suggestions to work around these issues (on Collab) or else I guess I have to give up and move on.
- Mixup can extend your training data infinitely, since there are an infinite number of affine transformations for every pair of images. Remember that adding training data is generally the first remedy of choice for a model that doesn’t generalize.
- Additionally, allowing affine combinations of labels (instead of requiring that every image has only one label) adds uncertainty, which has a ‘regularizing’ effect.
- An added benefit of Mixup is that you get the probability of the predicted class, which measures the confidence in the prediction, as one of the outputs.
These are a few ideas that come to mind to explain why mixup works well, but I feel that I fell short of capturing a full answer to your question – perhaps others can weigh in with their ideas?
Excellent question @harikrishnanrajeev A “Language Model” tries to predict the next word in a series of words. But more generally you might imagine trying to predict the next note in a melody, or tomorrow’s stock prices. A “Language Model” is a special case of a “Sequence Model”, which tries to predict the next element in a sequence. In principle, you can construct such a model for any kind of sequential data. Examples include words, musical notes, DNA sequences, 1D time series data such as stock prices, 2D time series data such as video, etc.
See this post by @KarlH for application to genomics data Lesson 12 (2019) discussion and wiki
1 Like
In the final “Training” section towards the end of the 12c_ulmfit.ipynb notebook, at the first training run, I encountered the following error (see below). I am running Windows 10 64-bit. Has anyone else encountered this error? Is there a workaround?
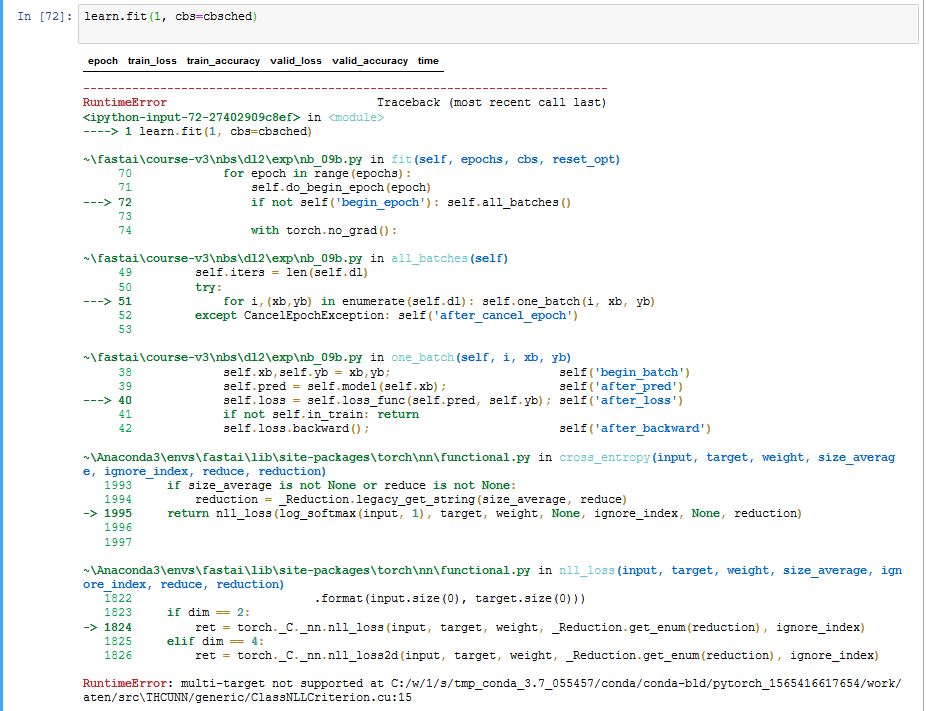
Later: found a workaround, suggested in this post.
Replace F.cross_entropy with nn.CrossEntropyLoss() as the loss function in the instantiation of theLearner class.
`#learn = Learner(model, data, F.cross_entropy, opt_func=adam_opt(), cb_funcs=cbs, splitter=class_splitter)
learn = Learner(model, data, nn.CrossEntropyLoss(), opt_func=adam_opt(), cb_funcs=cbs, splitter=class_splitter)`
I’m not going to track down why F.cross_entropy throws an error.
when I run the code in 12a_awd_lstm.ipynb: ll = label_by_func(sd, lambda x: 0, proc_x = [proc_tok,proc_num]), I get the index error:
~/sharedData/swp/dlLabSwp/fastaiRepository/course-v3/nbs/dl2/exp/nb_12.py in __call__(self, items)
113 def __call__(self, items):
114 toks = []
--> 115 if isinstance(items[0], Path): items = [read_file(i) for i in items]
116 chunks = [items[i: i+self.chunksize] for i in (range(0, len(items), self.chunksize))]
117 toks = parallel(self.proc_chunk, chunks, max_workers=self.max_workers)
IndexError: list index out of range
Can anyone give me some tips? appreciate it!
Could be something as simple as not finding the files. Check that you are able to access the file i with read_file. Maybe add a print statement to look at len(items) in the __call__ function
If train loss decreases while valid loss and accuracy increases while training a language model, what does it mean? Overfitting?
Please correct me if my understanding is wrong but I believe that something is incorrectly implemented in the AWD_LSTM class and specifically in its RNNDropout.
As mentioned by in the lecture and notebook we want to zero out sequence of words but the below line drops one dimension from the word embeddings.
raw_output = self.input_dp(self.emb_dp(input))
Basically, the calculation works like that:
- the input is 64x70 matrix which has numericalized tokens in rows
- self.emb_dp(input) returns 3D tensor which is 64(bs) x 70(words) x embedding vector dimension
- RNNDropout will be 64x1xemb_size which means that we would zero out one dimension of our embedding matrix
Please let me know if i am missing something here or where indeed there is an issue with this implementation.
In the video (around 34th minute), Jeremy says that initialising batch norm’s layer weights to 0 helps as we are adding 0 to the identity block weights which means the whole block does nothing!
I understand it will help in avoiding “exploding or vanishing gradient problem” but we are also not allowing the parameters to learn and learnings to be carried forward which begs the question why have deep networks if after a batch norm layer we set the weights to 0? The reason we added BN was to ensure that data distribution across every layer is uniform but setting the weights to 0 seems counter-intuitive. Can someone clarify?
1 Like
Hi, any chance you could possibly share your code for how you implemented this? I know how to register the forward hook to the embedding layer to mixup the output, but I cannot figure out how correctly modify my target variable and loss. Somehow the shuffle indices need to come out of the hook, but I am not sure how to correctly implement it.
I’m sorry - at the point I was trying it out, it was in the middle of a big Tensorflow project, so it probably won’t be any help here 
I was just about to ask the same question and I saw yours.
If we multiply everything with 0 after 3rd conv layer, then what is the point of the first 3 conv layers? How are they useful?
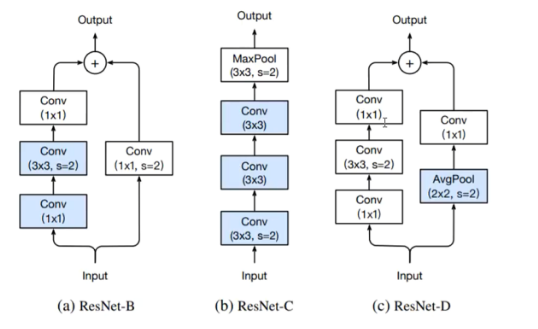
It was mentioned on this graph(ResNet-D).
so i do not like to change a lot
Sorry for the delay… I still don’t have the answer. In case, you or someone else understands, drop a line over here for the community.
Hi,
Someone posted (I cant recall where, sorry for the credit) that actually it comes from a torch update. It seems like you cannot index on a o rank tensor anymore, which causes the problem.
That person suggests simply deleting the [0] in the validate function in the model module. It worked juste fine for me. Just need to reinstall fast 0.7 as the reload module does not work in that case.
cc @berlinwar.
1 Like
Hi,
I’m also facing the same problem as @Srinivas. In my case, it happened when the following block of code is ran (from 12_text.ipynb; last few lines):
iter_dl = iter(train_dl)
x,y = next(iter_dl)
which raised the following error:
IndexError: invalid index of a 0-dim tensor. Use `tensor.item()` in Python or `tensor.item<T>()` in C++ to convert a 0-dim tensor to a number
When I tried to trace the error, it seems to be coming from the __getitem__ method all the way back in ListContainer class. It seems that PyTorch has changed certain behaviors of indexing a Tensor.
Can you (or anyone else) please elaborate more on the solution for the same issue?
Thanks!