i will remove the lowercasing next time i work on the language model. The sp rules that produce TK_MAJ and TK_U should be run before the tokenization but as i lowercased everything that part might not work:(
1 Like
Yah.
I’ve been playing with your code … really like how you’re processing the data prior to SP training. I’m going to message you a gist to the modifications (if you’re interested). Would love to get your input.
Thanks again!
1 Like
I had to miss a few of the later sessions and now I’m having a hard time finding this extra session: When was the audio module ultimately covered?
Can anyone please show me how to send a hidden state in AWD-LSTM model if I want to use AWD-LSTM as a decoder for a Seq2Seq model (because the prototype forward(self, input) is confusing me)? Just a heads up I am trying to solve Image Captioning.
1 Like
I would be curios to know what are you using it for?
It was mentioned somewhere. As soon as I’ll find it, will let you know, as it was a great explanation by Jeremy.
How can I view a batch of the mixup (i.e. images)? Want to use domain expertise to see if the dominating class is still clear visually.
I’m interested in working through the Lesson 12 UMLFit notebooks and am having trouble with import apex.
Per this thread, I’ve installed it with pip install git+https://github.com/NVIDIA/apex I appear to be missing a module amp_C
Maybe I’ve missed someone else reporting on this issue, but I couldn’t find it. I’ve run a clean reinstall of fastai (under a fresh conda environment)
Here are key software versions:
NVIDIA-SMI 418.67 Driver Version: 418.67 CUDA Version: 10.1
Here is a summary of the installation and error:
pip install git+https://github.com/NVIDIA/apex
Collecting git+https://github.com/NVIDIA/apex
Cloning https://github.com/NVIDIA/apex to /tmp/pip-req-build-tfklcto1
Running command git clone -q https://github.com/NVIDIA/apex /tmp/pip-req-build-tfklcto1
Building wheels for collected packages: apex
Building wheel for apex (setup.py) ... done
Created wheel for apex: filename=apex-0.1-cp36-none-any.whl size=135295 sha256=b757c8a3aaa50f946f3c9a1d12e5ab93103eaafae06bb5e243dad4fb1ee339f0
Stored in directory: /tmp/pip-ephem-wheel-cache-mywe8qea/wheels/91/1e/dc/41a5ba86547c578bd19be9cb9bdfd90b4e797acc58377e343b
Successfully built apex
Installing collected packages: apex
Successfully installed apex-0.1
(fastai) cdaniels@gold:~$ python
Python 3.6.9 |Anaconda, Inc.| (default, Jul 30 2019, 19:07:31)
[GCC 7.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import apex
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/cdaniels/anaconda3/envs/fastai/lib/python3.6/site-packages/apex/__init__.py", line 6, in <module>
from . import amp
File "/home/cdaniels/anaconda3/envs/fastai/lib/python3.6/site-packages/apex/amp/__init__.py", line 1, in <module>
from .amp import init, half_function, float_function, promote_function,\
File "/home/cdaniels/anaconda3/envs/fastai/lib/python3.6/site-packages/apex/amp/amp.py", line 5, in <module>
from .frontend import *
File "/home/cdaniels/anaconda3/envs/fastai/lib/python3.6/site-packages/apex/amp/frontend.py", line 2, in <module>
from ._initialize import _initialize
File "/home/cdaniels/anaconda3/envs/fastai/lib/python3.6/site-packages/apex/amp/_initialize.py", line 9, in <module>
from ._process_optimizer import _process_optimizer
File "/home/cdaniels/anaconda3/envs/fastai/lib/python3.6/site-packages/apex/amp/_process_optimizer.py", line 6, in <module>
from ..optimizers import FusedSGD
File "/home/cdaniels/anaconda3/envs/fastai/lib/python3.6/site-packages/apex/optimizers/__init__.py", line 2, in <module>
from .fused_adam import FusedAdam
File "/home/cdaniels/anaconda3/envs/fastai/lib/python3.6/site-packages/apex/optimizers/fused_adam.py", line 3, in <module>
from amp_C import multi_tensor_adam
ModuleNotFoundError: No module named 'amp_C'
Any advice would be appreciated.
Thanks
Since I’m running my own server, I thought I might have had conflicting versions of the System CUDA Libraries and Python fastai and pytorch modules. I signed up for Salamender and spun up a new instance and got the same error as my own server and replicated the steps described previously and got the same error: No module named ‘amp_C’
Here is my hack for doing the lesson12*.ipynb series notebooks without relying on import apex: comment out all original and downstream references to apex and fp16. This works because apex is used for vision (not text).
Comment out all lines in ~/course_v3/nbs/dl2/exp/nb_10c.py except for:
from exp.nb_10b import *
I can’t reproduce the reduction in accuracy after turning off gradients (problem that is supposed to occure due to Natchnorm). Anyone has a guess why that is ?
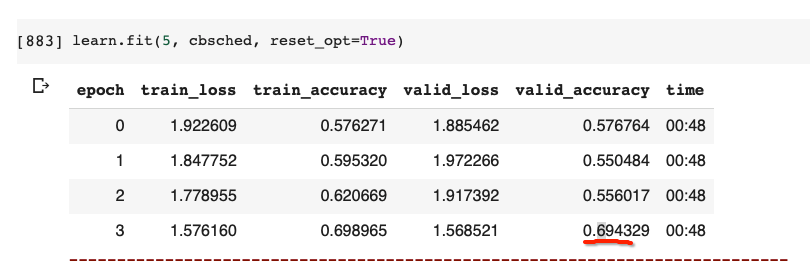
I’ve been on this for days, does anyone have an idea why that could happen ?? help would be much appreciated as I can’t advance
or… as I prefer, add greek keyboard and use crtl space to switch keyboards, then just type a for alpha, b for beta, etc.
What is the idea of crappify?
Is there an automation tool for this? The problem with notebooks is that you will need to strip a lot of things to keep in git. Another problem I usually have is that I no only wnat to keep track of parameters but also organize the results: model, charts, etc. I am not aware of anything that can help with this… besides Obsessive-Compulsive Disorder.
1 Like
Crappify adds noise to images so you can test how crappy the images have to get in order to break your model.
1 Like
In notebook ‘12a_awd_lstm.ipynb’, it is said that the Activation Regularization applied uses the L2 norm of the last layer’s output activation “with dropout applied” (in the Markdown above the definition of RNNTrainer). But in AWD_LSTM.forward, doesn’t this line:
if l != self.n_layers - 1: raw_output = hid_dp(raw_output)
, prevent the output dropout from being applied to the last layer’s raw output activation? There doesn’t seem to be any other dropout applied subsequently. In fact,
test_near_zero((outputs[-1] - raw_outputs[-1]).sum())
passes.
1 Like
Another bit I don’t understand is that, for the Temporal Activation Regularization, there is a if len(h) > 1, which I think here means “if the batch size is greater than 1”. Why do we only apply this regularization when the batch size is as such?
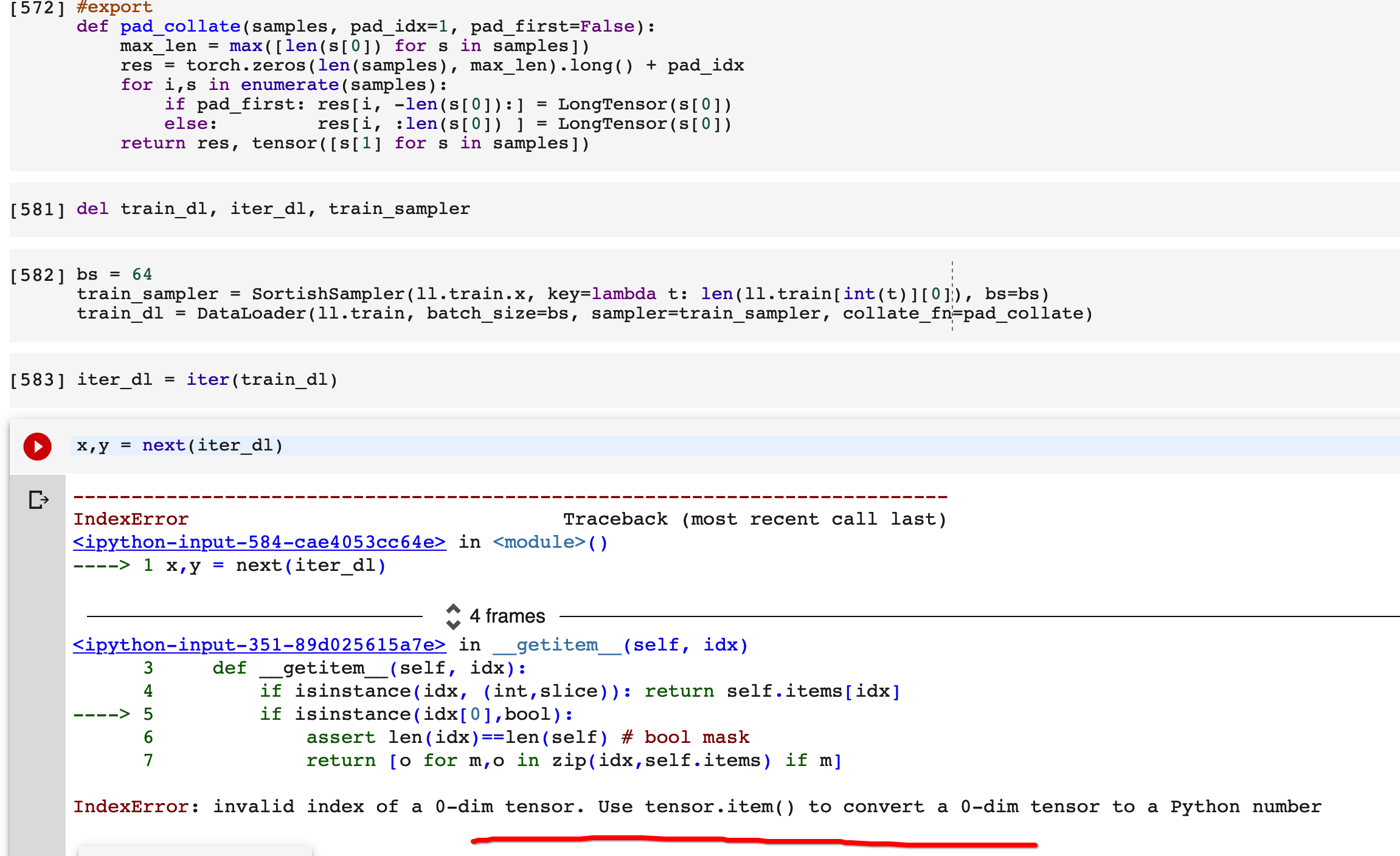
I have been struggling to get lesson 12 notebook working. Very early in the notebook after executing this line:
il = TextList.from_files(path, include=[‘train’, ‘test’, ‘unsup’])
I continued to get zero items in il which is supposed to contain 100000 items.
After hour+ of debugging, I traced this down to extensions having to be provided as {’.txt’} in the
definition of the from_files method of the TextList class. Othewise if extensions=’.txt’ then when the
get_files() method is used from 08_data_block notebook, it tries to listify the extensions string leading to problems.
The value provided in the notebook is just the string ‘.txt’. Just providing extensions as a string extensions=’.txt’ does not seem to work as setify of ‘.txt’ results in {’.’, ‘x’, ‘t’} which is NOT what we want to use in the get_files() method.
Am I doing something wrong or do the extensions have to be provided as a set.
(Note that image_extensions as defined in notebook 08_data_block.ipynb is already a set and so works fine when used with get_files() method.)
What is the name of this notebook (i.e. blah.ipynb)?