In the final “Training” section towards the end of the 12c_ulmfit.ipynb notebook, at the first training run, I encountered the following error (see below). I am running Windows 10 64-bit. Has anyone else encountered this error? Is there a workaround?
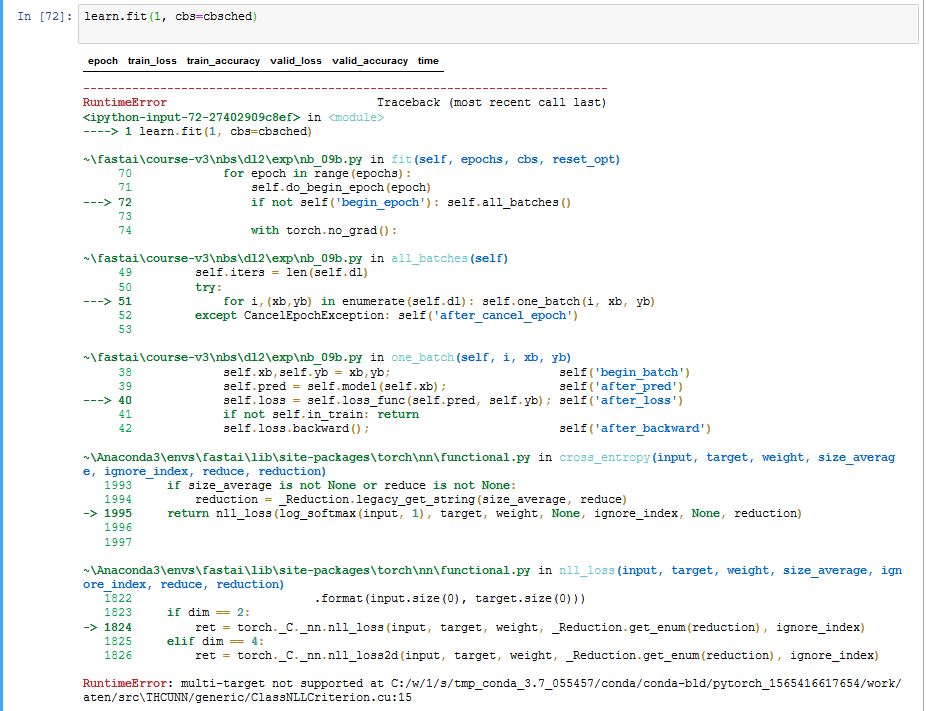
Later: found a workaround, suggested in this post.
Replace F.cross_entropy with nn.CrossEntropyLoss() as the loss function in the instantiation of theLearner class.
`#learn = Learner(model, data, F.cross_entropy, opt_func=adam_opt(), cb_funcs=cbs, splitter=class_splitter)
learn = Learner(model, data, nn.CrossEntropyLoss(), opt_func=adam_opt(), cb_funcs=cbs, splitter=class_splitter)`
I’m not going to track down why F.cross_entropy throws an error.