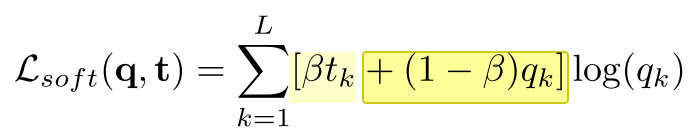I am reading the paper discussed in class
Training Deep Neural Networks on Noisy Labels with Bootstrapping https://arxiv.org/abs/1412.6596
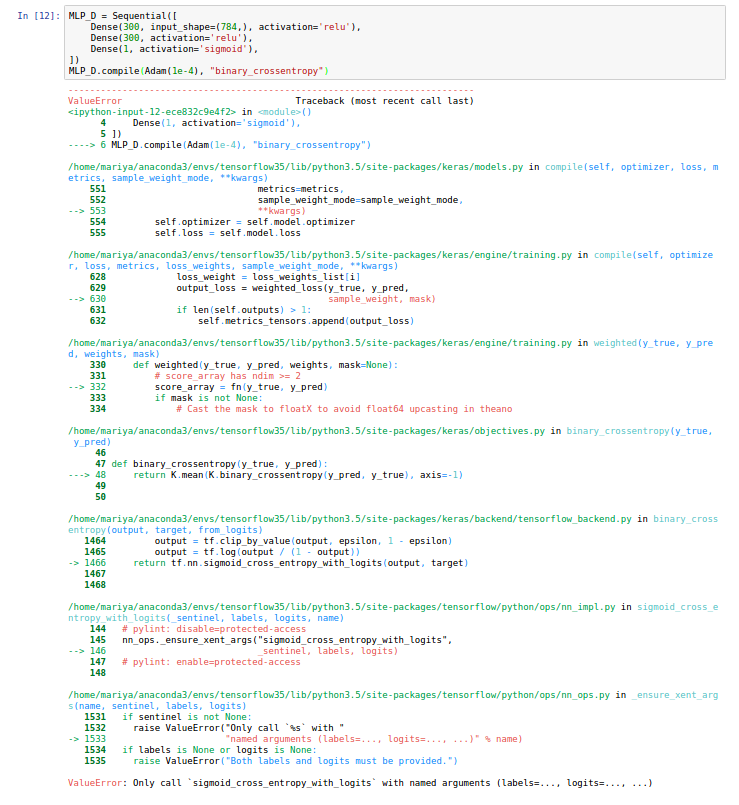
I am having trouble understanding equation 6. What is L_soft? Is it the loss? The paper says regression targets. If it is a regression target, then shouldn’t it change for each class (one hot encoded)?
Sure. Glad you’re checking out that paper! The notation is introduced all over the place in it, so to find out what things are, you’ll need to search around a bit!
q are the predicted probabilities. t are the actual labels. And inside the sum() these are being indexed as t[k] and q[k]. If you replace the bit I highlighted with just q[k], then you have the standard cross-entropy loss, which we’ve used for nearly all of our classification models (and we have an XL spreadsheet showing it).
So we’re simply creating a new function which replaces the label, q[k], with a mix of a bit of the prediction t[k] and a bit of the true label q[k] (using a parameter beta which the paper says they set to 0.8).
So basically this is a lot like pseudo-labeling, except that it’s happening for the labeled data, rather than unlabeled.
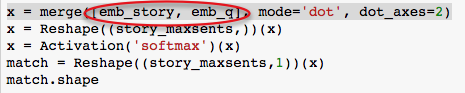
But in the notebook, the query embeding emb_q is merged only with emb_story, but not with emb_c:
Anybody knows why we are skipping the query embedding before 2nd Softmax here?
BTW, another difference I noticed is that, in the paper “+” (sum) is used before the 2nd Softmax, while in our notebook ‘dot’ is used. It seems that different architectures lead to similar results.
So, if I have to implement bootstrapping in Keras, do I have to explicitly relabel examples in each minibatch? Or can I implement a custom loss function to handle it?
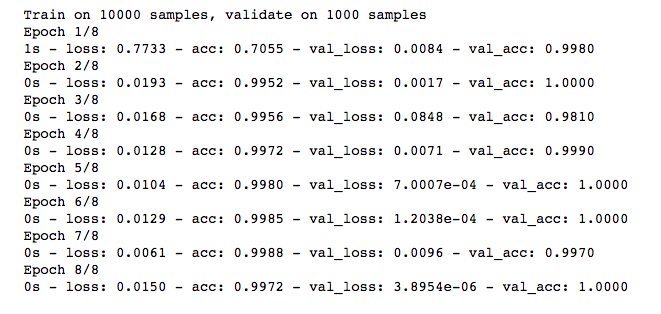
It looks to me that it does not make a big difference. I trained them a few times, sometimes one is a bit better than another, but overall the result is quite similar.
I will try it on two hops later to see whether it makes a difference.
Classes not present in ImageNet: Any insights on how are we able to find images with w2v classes which are not defined in imagenet e.g. net and rod (Lesson 11 video, 7:45m)?
OK, so now try changing to the ‘two supporting facts’ dataset, and use multiple hops (you can just uncomment the relevant line at the top of the notebook). That would be interesting, since I had a lot of trouble getting that to fit.
Migrated old homework code off of AWS instance and to my own deep learning server which I built this week (yay!) but running into new issues getting the code the run that didn’t happen before. Would appreciate some ideas / help debugging.
00:07:30 Linear algebra cheat sheet for deep learning (student’s post on Medium)
& Zero-Shot Learning by Convex Combination of Semantinc Embeddings (arXiv)
00:10:00 Systematic evaluation of CNN advances on ImageNet (arXiv)
ELU better than RELU, learning rate annealing, different color transformations,
Max pooling vs Average pooling, learning rate & batch size, design patterns.