@vettukal thanks for your suggestions.
Tried the first - uninstalling the HF diffusers and installing a custom version, but that still yielded a black image.
Then I checked this post:
Since we have an updated diffusers library (0.6.0, as of today), the modification suggested by @cjmills is in essence the same as passing in safety_checker=None during pipeline creation, as suggested here:
Regardless, I did give it a go - manually switched off the safety checker in the pipeline_stable_diffusion.py script, imported StableDiffusionPipeline again and still saw a black image as output. As mentioned in my previous reply, the NSFW warning is gone, but the image output is the same! Suspecting that a low value of num_inference_steps might somehow be causing the problem, I tried bumping that up to 42, but that didn’t work either.
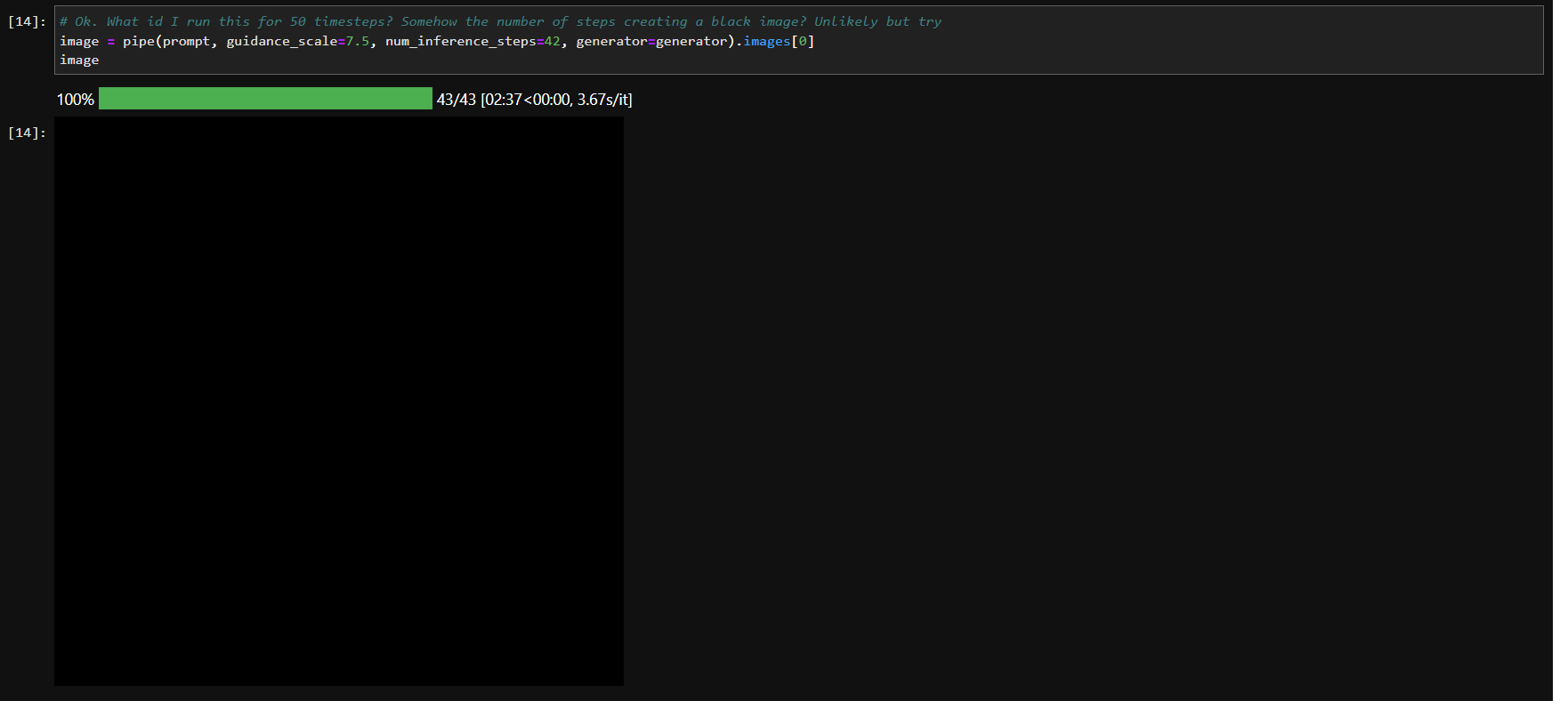
If anyone has any insights on this, please do let me know. Any other alternative directions to explore as to why the model keeps giving a black image output even with the safety checker turned off?
(Apologies for spamming the forum with questions about this one issue!)