Just speculating, maybe fastai.audio could be called fastai.signals instead. There are many applications in the signal processing field that is not only restricted to audio. One example from my experience is the blind source separation field in which seeks to extract source signals from mixed signals. In audio would be equivalent to extract instruments sounds from a song, but the same techniques can be applied in other fields.
fastai.dsp (digital signal processing?)
5 Likes
One mathematical thing I wanted to mention is that I’d think that keeping track of the variance directly rather than the sum of squares might be numerically advantageous. (The wikipedia references being var/std discussion on the moving average page and Welford’s algorithm and the following variants.)
In my experience, the BN stats can be numerically quite sensitive.
Best regards
Thomas
3 Likes
Short of redefining the .to, .cuda and .cpu methods (and .float, .double, .half, too), I’m not aware of any. More elegant might be to do the moving in the update_stats (moving is a nop if you’re already there).
Between that an you wanting to serialize momentum, I’d suggest that you look into state dict hooks (and we all  hooks, right?).
hooks, right?).
I’m not sure if and where there is extensive documentation of that, but you’d need Module._register_state_dict_hook and Module.__register_load_state_dict_pre_hook.
We changed it because the power made it to close to 1. when the batch size was normal. That’s why we switched to this function that goes more slowly from 0. to 1.
1 Like
Yes, this is where I tried to do it in update_stats and moving silently fails, see my code example above. A bug in pytorch?
So I’m too tired to write it more politely, but I have a hunch that you might have fixed the wrong thing. What happens is that with that formula, you set the have mom == mom1 for a batch size of 1, while it might be tempting to leave the mom parameter as what people use with bs = 32 or whatever. So I would suggest that the right thing is not to change the formula, but change the self.mom, because you moved it from the unit “1 batch” to the unit “1 sample” (and as you might guessed from the above, to me the exponent here is “like time”).
Best regards
Thomas
Running batch norm allows for a high learning rate. Didn’t have more than a few minutes this week for your 1 epoch challenge. So just keeping the batch size at 32, I decided to only vary the learning rate I got some very interesting results, but here are the results I got with an lr of 2.
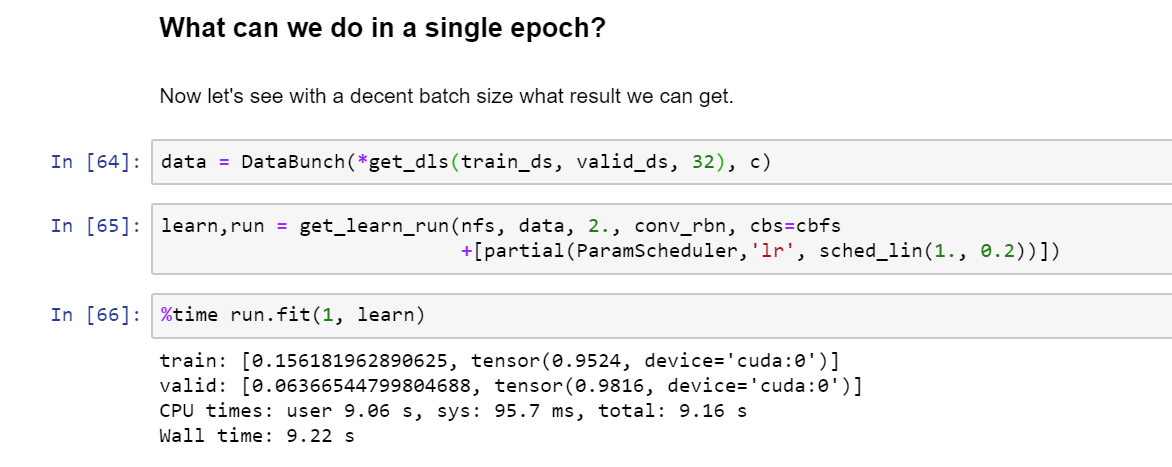
The mom is used differently to that what people do in any case: no one uses the averaged statistics during training in regular BatchNorm.
I must say I’m unconvinced that the two are connected.
@sgugger, @jeremy So if I use LAMB as an example rather than BN, is it fair that I might blog why I think the bath-size-adapted-experimental moving average is good in the mom = 1-(1-mom_for_bs_1)**bs way and not disclose parts of your research that you want to keep under the lid for now?
i would say undefined instead of infinit
Happy to know, I performed my training on Kaggle and had the var() problem too with the current fastai version.
Completely not-technical question. I find part 2 v3 very intense but rewarding. Every time, I listen class video I learn something new. But how is everyone using notebooks? Still tried and tested method of repeating work from notebooks many times until I can replicate it without looking back, is the best? Is there anything, I can do on the top of this to get even deeper understanding?
Please read the first post - you need to run torch-nightly for this class, which kaggle isn’t running, so you won’t be able to run this class on the kaggle platform until pytorch-1.1.0 is released and installed on kaggle.
OK, with @t-v’s help here is the latest incarnation of RunningBatchNorm:
class RunningBatchNorm(nn.Module):
def __init__(self, nf, mom=0.1, eps=1e-5):
super().__init__()
self.mom, self.eps = mom, eps
self.mults = nn.Parameter(torch.ones (nf,1,1))
self.adds = nn.Parameter(torch.zeros(nf,1,1))
self.register_buffer('sums', torch.zeros(1,nf,1,1))
self.register_buffer('sqrs', torch.zeros(1,nf,1,1))
self.register_buffer('count', tensor(0.))
self.register_buffer('factor', None)
self.register_buffer('offset', None)
self.batch = 0
self.accumulated_bs = 0
self.hw = None
def update_stats(self, x):
bs,nc,*_ = x.shape
self.batch += bs
x = x.detach()
dims = (0,2,3)
s = x .sum(dims, keepdim=True)
ss = (x*x).sum(dims, keepdim=True)
if self.hw is None: self.hw = s.new_tensor(x.numel()/nc/bs) # calculate/tensor create once
c = self.hw*bs
if self.accumulated_bs == 0:
self.s, self.ss, self.c = s, ss, c
else:
self.s += s
self.ss += ss
self.c += c
self.accumulated_bs += bs
if self.batch < 10000 or not self.batch % 2: # re-calculate every other batch after 10000
mom1 = self.s.new_tensor(1 - (1-self.mom)/math.sqrt(self.accumulated_bs-1))
self.sums .lerp_(self.s , mom1)
self.sqrs .lerp_(self.ss, mom1)
self.count.lerp_(self.c , mom1)
self.means = self.sums/self.count
self.varns = (self.sqrs/self.count).sub_(self.means.pow(2))
if self.batch < 20: self.varns.clamp_min_(0.01)
self.accumulated_bs = 0
self.factor = self.mults / (self.varns+self.eps).sqrt()
self.offset = self.adds - self.means*self.factor
def forward(self, x):
if self.training: self.update_stats(x)
return x*self.factor + self.offset
-
replaced multiple
detachcalls with justx = x.detach()- which replacedxwith its detached version, without affecting the real x going through the forward call. It shares the same data with the originalx, but since it’s detached none of the calculations involving it will attach anything to the graph. -
small speed up of
c = s.new_tensor(x.numel()/nc), since it’s mostly the same number, so let’s cache all butbs(since the last batch can be of a different size):if self.hw is None: self.hw = s.new_tensor(x.numel()/nc/bs) # calculate/tensor create once c = self.hw*bs -
finally, the big question you @jeremy asked - how can we do less recalculations. I still don’t understand exactly why but you can’t skip calculations that involve parameters, so returning early from
update_statsresults in error:“Trying to backward through the graph a second time, but the buffers have already been freed. Specify retain_graph=True when calling backward the first time.”
So Thomas came up with a workaround of skipping intermediary calculations by using partially the idea I tried earlier to buffer up data, instead of an early return. This is the
if self.batch < 10000 or not self.batch % 2line, so now you can tune it up.
All credits go to Thomas - thank you for your help!
Also here is a simplified example that shows that you can’t skip a calculation involving a parameter:
from random import randint
class RunningBatchNorm(nn.Module):
def __init__(self, nf):
super().__init__()
self.mults = nn.Parameter(torch.ones(nf,1,1))
self.register_buffer('factor', torch.ones(nf,1,1))
def forward(self, x):
if self.training:
if randint(0,1): self.factor = x*self.mults # randomly skip this
return x*self.factor
This fails with the aforementioned error.
4 Likes
So I wrote up my thoughts around the scaling of the momentum for LAMB here: http://lernapparat.de/ewma-and-batch-size/ (it’s not yet proofread or published). In the end, I guess it stays clear of anything related to running batch norm.
3 Likes
Do we know what an ideal distribution of our activation values would look like? We start with 90% in the lowest 2 bins. In the histogram after we fix with kaiming init and leaky relu, we still have ~10-15% in our lowest couple bins. What would the ideal number of zeroes be? Would we want no zeroes if we could have it (because the info is being wasted)? Or would we want zeroes to just be a representative share (uniformally distributed)? Thank you!
Also if you look at slide 32 of Dmytro Mishkin - CNNS - FROM THE BASICS TO RECENT ADVANCES 2016 - his metrics over different architectures (of that time) show that before or after placement of BN really depends on the dataset and the specifics of your architecture.
So, probably, it’s best to place it after as discussed, but to also test before and compare the 2.
back up link in case that pdf disappears.
3 Likes
Thanks, very useful!
1 Like
@t-v @stas unfortunately that doesn’t quite work. I had to put this back to get good results in the final bs=32 cell:
self.sums.detach_()
self.sqrs.detach_()
Otherwise it doesn’t have the gradients that it needs to get good results.
However it doesn’t actually skip any computation at the moment, since you’re checking self.batch%2, which is always true, since bs is even. You should instead create and check an iteration counter - if you do that, you’ll find you still have the dreaded “Trying to backward through the graph a second time, but the buffers have already been freed” error!..
1 Like