After lesson 1, I decided to try classifying Nigerian business registration documents that my company collects as part of customer registration process. My aim is to create a model that can help my team identify and classify these documents as they are uploaded without needing users to manually select what kind of documents they just uploaded.
I’ve blacked out the names of the business and the registration IDs at the top left corner.
As you can see, the differences between them aren’t very conspicuous. Apart from the names of the certificates on the body of the documents and the abbreviations at the top left corner, there’s no other visible differences to tell them apart. The RC and CAC/IT even have the same names.
I followed the steps in lesson 1 and the best I got with resnet50 was 19% error rate. I can tell that this is a big jump from the first lesson considering how alike the documents look, but I just wanted to know if there was any trick that could have gotten a better result. All I’ve done so far is follow everything in the first lesson. I could see that the image resize made the images smaller and likely made it harder for the model to find the already tiny differences.
What could you have done differently to get a better result?
Hey, welcome! Have you tried using the classification interpretation to check out your top losses and confusion matrix? I think it would help you shine a lot of light on what’s going on. For instance #1 (BN) is very different in color from #2 (RC) and #3 (CAC/IT) (which are almost identical). Is your model confusing 1, 2, and 3 equally? Or are almost all the errors between 2 and 3?
Also the differences don’t really have much to do with color. Older registration documents are white and the newer ones have different hues of green. Also because of how people scan and upload the pictures, the colors will look very different.
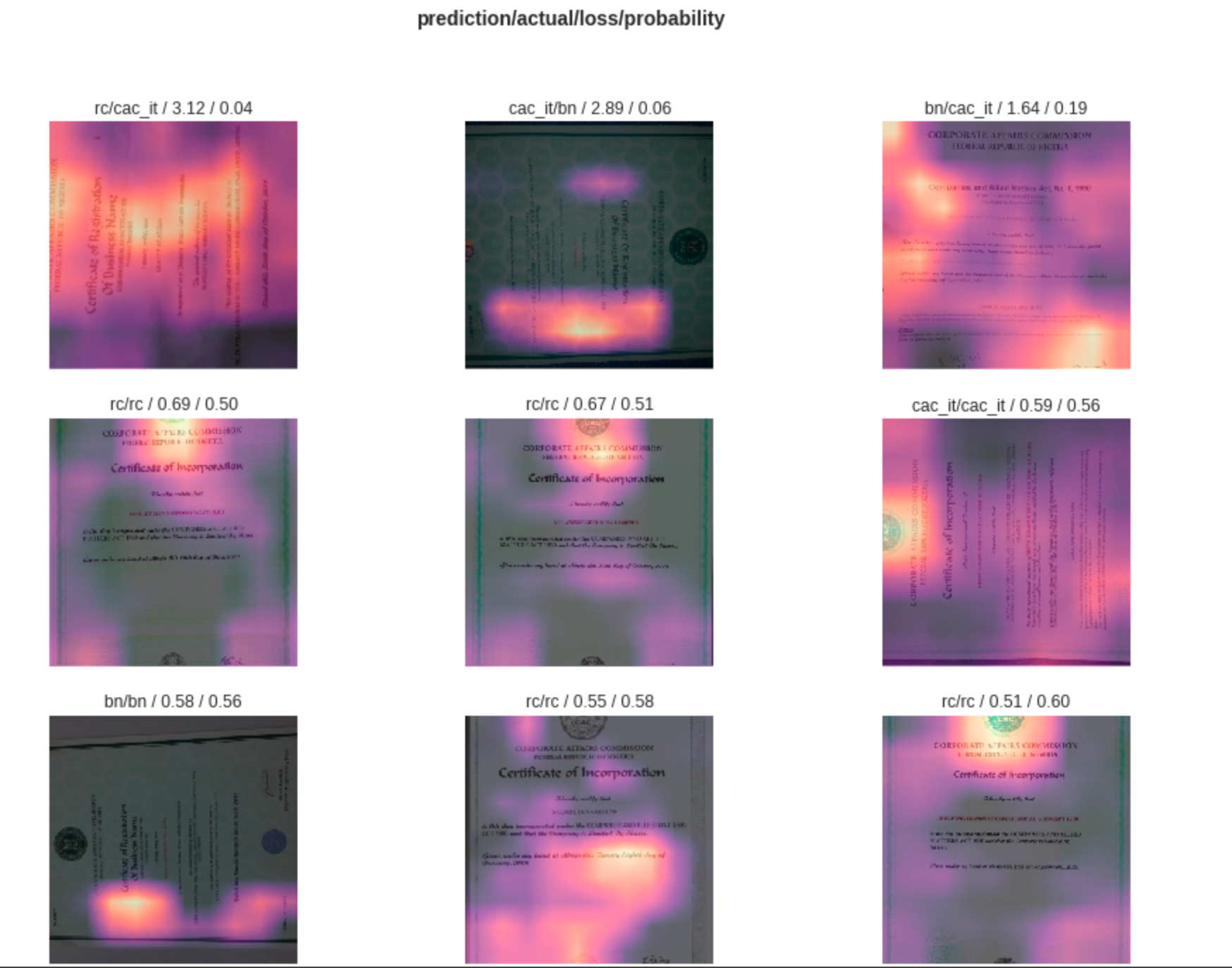
I also tried to plot the top losses and I can see that some of them have the same category as actual and predicted. I’m not sure I understand. Can someone please explain to me.
Yeah if there is a lot of variation in colors and you don’t have that large a sample of documents, it may be a good idea to try extracting the text via OCR as thousfeet suggested and then just looking for words that are unique to each document (doesn’t require deep learning).
I’m not entirely sure about this myself. I know that you can have the correct prediction and still a high loss (think about the case where it’s rc, but it predicts rc 34% and the other two 33% each), but the losses should still be higher in the cases where you predicted incorrectly. How big is your sample size and how many total incorrect predictions are there in that 19% error rate?