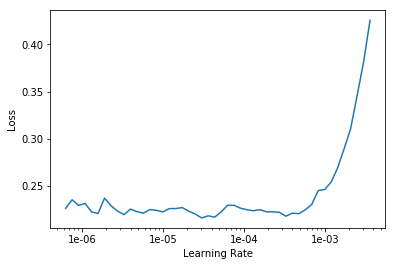
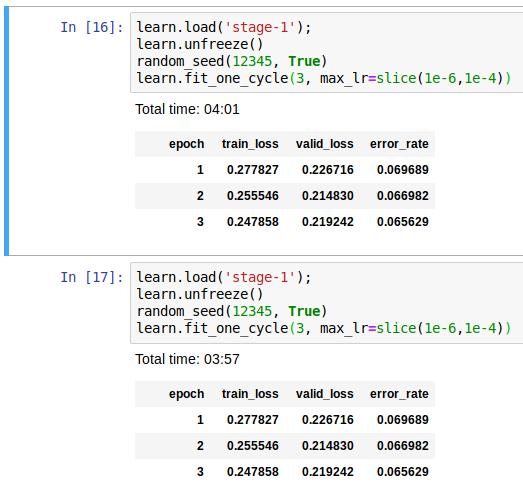
I’m trying to understand if this behaviour is normal (because batches get selected randomly and therefore the error rate comes out different because of which batches happen to get selected during fit_one_cycle() ?)
Yes I did as “stage-1” … I just forgot to put it in the code sequence above as it’s not a screenshot. If I load the model and run lr-find on it, it shows the same graph as in the original notebook.
I read in a related thread that these issues may have something to do with the random seed being reset during fit_one_cycle but I haven’t tried it.
This is likely due to learning rate annealing. Basically, when using fit_one_cycle, your learning rate is changing behind the scenes over the course of the run.
Because of this, comparing the 5th epoch of learn.fit_one_cycle(8) is not equivalent to the last epoch of learn.fit_one_cycle(5).
If you run them both with 5 or both with 8 epochs you should see more similar results.
There are a couple of other topics about this here:
If you want actual 100% identical runs, there are several random seeds and a few settings to set. There’s a random_seed function here that will do the trick: