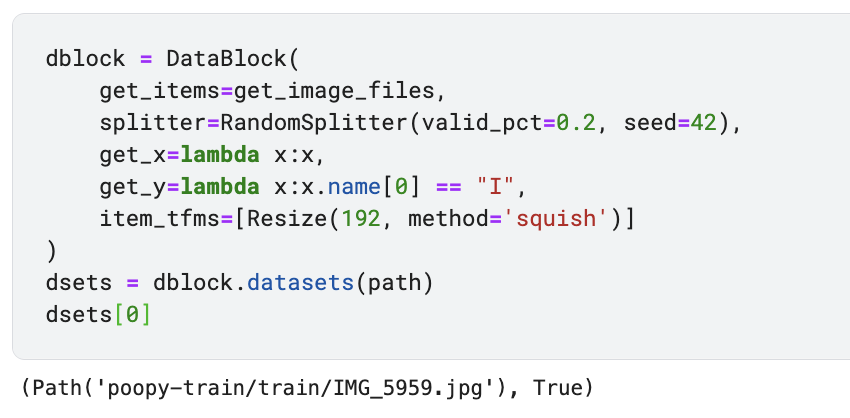
I was distracted by Poopys cuteness, so I didn’t think of it before 
Right now (at least it seems so in the notebook/datasets) you only provide data for your “True” label (images of Poopy) during training.
In order to make the model learn to predict “False” for other things you also have to provide the “other things” to the Learner. Your last screenshot suggest that you already have a ‘notpoopy’ folder, so to keep things simple I would do the following:
Locally create a single poopy_dataset folder. This folder contains poopy and notpoopy subfolders (we’re going to derive the labels from the folder names) and put all the images (so no split into train and valid as in your kaggle datasets before) into the according folders. The folder structure should look something like:
poopy_dataset
├── notpoopy
│ ├── IMG_2314.jpg <-- images of something else
│ ├── IMG_3142.jpg
│ └── etc…
└── poopy
├── IMG_1234.jpg <-- images of Poopy
├── IMG_4321.jpg
└── etc…
Zip poopy_dataset and upload the .zip file to kaggle, creating a new Dataset (kaggle automatically unzips it). Say you use the method to add a dataset to a notebook that I mentioned before, you will have the same folder structure as above at path = Path('..input/poopy_dataset') (depending on the name you gave the dataset).
For training you only have to adjust the dblock in one place, namely the get_y function that generates the labels for each image. You can use parent_label which fastai provides. It returns the folder name each image is contained in as the label, so notpoopy for parent_label('../input/poopy_dataset/notpoopy/IMG_2314.jpg') for example.
A functioning result might look like this:
from fastai.vision.all import *
path = Path('../input/poopy_dataset')
dblock = DataBlock(
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_y=parent_label,
item_tfms=[Resize(192, method='squish')]
)
dls = dblock.dataloaders(path, bs=8)
dls.show_batch() ## Check if the labels match the images.
learn = vision_learner(dls, resnet18, metrics=error_rate)
learn.fine_tune(3)
Let me know if it worked or if you need any other help  .
.