Singe Class or Multi-Label?
Single class
You could probably get away with a get_y that takes in those three columns and then grabs the index of whichever is the 1. (sorta an advanced use of ColReader)
Yeah, that’s what I did. Was curious if there is a way to read EncodedLabels directly.
1 Like
There’s a one_hot_decode function that exists. Looks like it takes in a label and a vocab and spits it back out:
Yeah, I checked that too. Thanks @muellerzr. I ended up converting the one hot encoded to integers and usin ColReader to get_y.
For your target transforms use the below if you are using the low-level API
y_tfms = [
ColReader(<your_ohe_columns>),
EncodedMultiCategorize(<vocab=your_ohe_columns>),
]
… or this if you are using the high-level DataBlock API
blocks = (
TextBlock.from_df(corpus_cols, vocab=vocab, seq_len=bptt, rules=custom_tok_rules, mark_fields=include_fld_tok),
MultiCategoryBlock(encoded=True, vocab=<your_ohe_columns>)
)
dblock = DataBlock(blocks=blocks,
get_x=ColReader('text'),
get_y=ColReader(<your_ohe_columns>),
splitter=ColSplitter(col='is_valid'))
1 Like
Sorry aman just saw this, a bit under the weather.
here is what i did https://github.com/muellerzr/Practical-Deep-Learning-for-Coders-2.0/blob/master/Computer%20Vision/06_Multi_Point_Regression.ipynb.
The evaluation for this was on probability values so i treated it a Regression problem
1 Like
we could also just create a new column(with that logic) and then with get_y just read this new column ![]() DataBlocks is so powerful, so many ways to things
DataBlocks is so powerful, so many ways to things
1 Like
My show_batch is not the prettiest for this 
let me know if you figure out a better solution.
So, is there a variable batch size command if batches are dropped when we don’t have enough elements?
I’ve already seen this pattern before and here once again.
On demonstration of NLP learner on IMDB we get a learner with pretty good classification accuracy near 93%. I assume that the last 7% can be explained by hard things like knowledge of the world and sarcasm and another thing.
But
Why it works so poorly on simple negations?
Is it a simple way to overcome it?

Because you’ve fed it garbage English. Unless you train it on incorrectly constructed sentences you can’t really expect it to understand them properly. Try ‘didn’t like’ instead of ‘don’t liked’ and it should give you better results.

Nope, it should not be on the fence about that one at all. That should be neg and I don’t see why it’s not, unless it saw a very small dataset with a lot of ‘do not’ and not very much ‘don’t’.
I’m messing around with the camvid segmenter on page 42, trying to feed it other images and look at it’s output. Following is my code and the results.
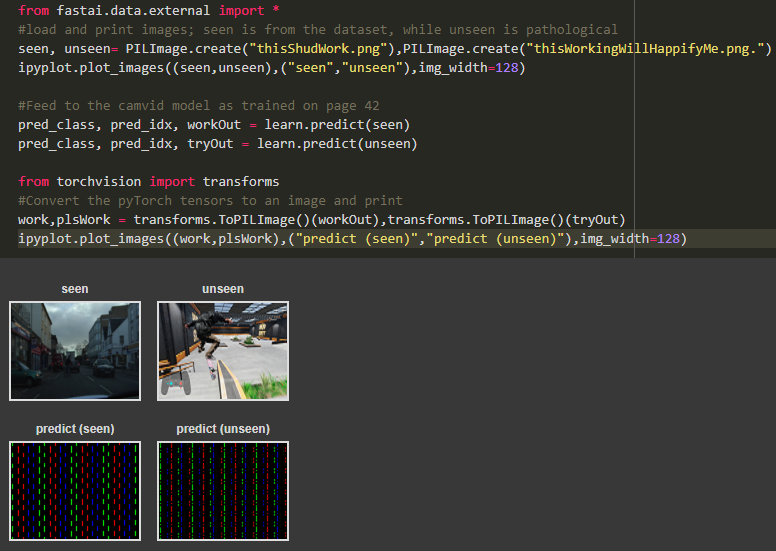
Edit: I see that the above code is stupid wrong, as it’s trying to look at a 128x96x32 array as an image. But I still don’t get how I’m supposed to do this, at the end, every pixel is attached one of the 32 labels. How do I color based on them?
I tried for fun:
“not too bad” => neg
“good would be a euphemism” -> pos
“watching the grass grow” -> pos
“this film had great potential, but faced challenges to live up to that potential” -> pos
“needs some additional work” -> pos
it does not get double negation or irony or sarcasm
as for me, I’m ok with such hard things like double negations and sarcasm. Have you tried plain negations in different forms?
Hi @sgugger, I am using fastai==2.1.2 and fastcore==1.3.1 and am getting the same error.
Is there a way to fix this??