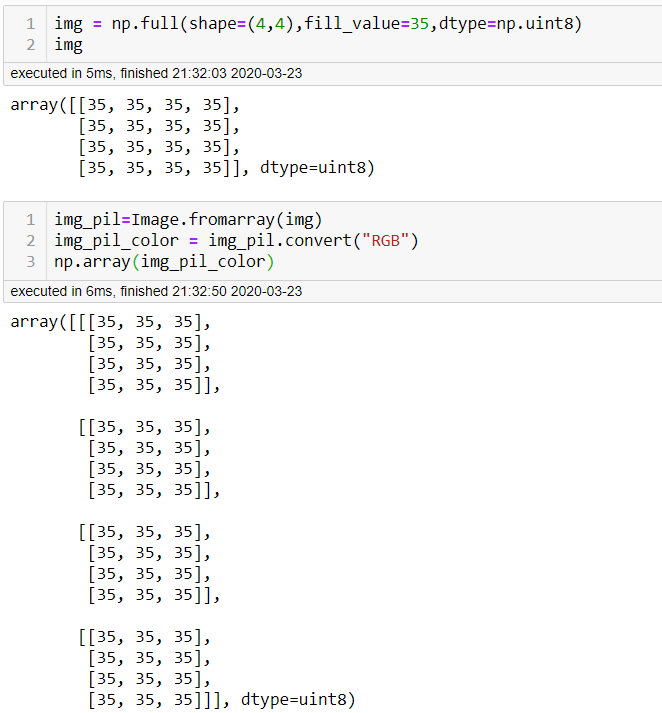
ImageBlock points out to this code fastai2/vision/core.py
_bypass_type=Image.Image
_show_args = {'cmap':'viridis'}
_open_args = {'mode': 'RGB'}
@classmethod
def create(cls, fn:(Path,str,Tensor,ndarray,bytes), **kwargs)->None:
"Open an `Image` from path `fn`"
if isinstance(fn,TensorImage): fn = fn.permute(1,2,0).type(torch.uint8)
if isinstance(fn,Tensor): fn = fn.numpy()
if isinstance(fn,ndarray): return cls(Image.fromarray(fn))
if isinstance(fn,bytes): fn = io.BytesIO(fn)
return cls(load_image(fn, **merge(cls._open_args, kwargs)))
In the create function, it handles certain types like TensorImage, ndarray. In the example, you pointed the output of get_x would be passed to ImageBlock which is already an image. If you do not use PILImage.create then just file path to the image is passed to the Image block and the lask line of create function gets executed.
@arora_aman also FYI, you should pass into ImageBlock saying you’re doing one channel images like so: ImageBlock(cls=PILImageBW) otherwise if you want to do get_x, make sure you use BW
Thanks @muellerzr and @barnacl . Not passing PILImageBW works too because it converts my images to 3 channel (by copying one channel across the others), I find this beneficial because then I don’t need to update model for single channel.
It’s just a different approach I think. I don’t know much about this too tbh but when I participated in BengaliAI, Kagglers got top scores both by using single channel or multi channel images for Black and White handwritten graphemes images.
I find using 3 channel intutive, as imagenet models are trained on images with 3 channels. In some of my experiments I found 3 channel to work better even for BW images.
for bengali as Aman and other mentioned after extensive experiments I did not find any difference training on 1 channel or 3 channels. The only difference was when you use 1 channel and dont copy weights from 1st conv layers the training takes a bit longer because you have to relearn weights. I made a post here: https://www.kaggle.com/c/bengaliai-cv19/discussion/130311#745589 explaining some stuff
But I think one can do proper investigation and benchmarks …
I find 3 channel approach better too. Only because they need no new changes to be made to the model and transfer learning just works fine, 1 channel or 3 channel theoretically they both have the same information.
Just to add to this! The thing which I had mix feelings is normalization. Suppose you modify first conv and the question is should you normalize using imagnet stats but converted to 1 channel ? or use your data specific normalization ?
To add to my previous comment
1 channel image is just stacked 3 times to make the 3 channel image. Other than saving memory I see no other use case for using 1 channel images for transfer learning.
Agree… I think the best way in some competition when 1 channel input was given people were finding different ways to code information in to other channels. For example in Hemorrhage Detection competition one could code different windows like brain or bone. In Google doodle drawing competition people were encoding diffrent strokes in to channels =)
I don’t think replacing a pretrained model’s first conv layer is a good technique, the second layer in the model has weights trained in such a way to understand patterns by combining the lower-level patterns the first layer was able to recognise, if you throw away that layer’s weights and replace it with random weights(1 channel version), you lose everything that you get by using a pretrained model.
agree if just replacing first conv with random weights it will take longer to train, but substituting weights from1st conv by average from 3conv result in much more stable training.
I think it is mainly for visualisation in show_batch. Shouldn’t effect training in anyway. That is a good point about transfer learning (when applicable).