I posted what follows in “Lesson 1 discussion”, but that thread seems to be a bit dead, so I considered worthwhile to open a new thread.
If this infringes any rule, please let me know and remove the present thread. Thanks.
I’m playing with the resnet34 and, like Jeremy suggested, running some experiments on various datasets.
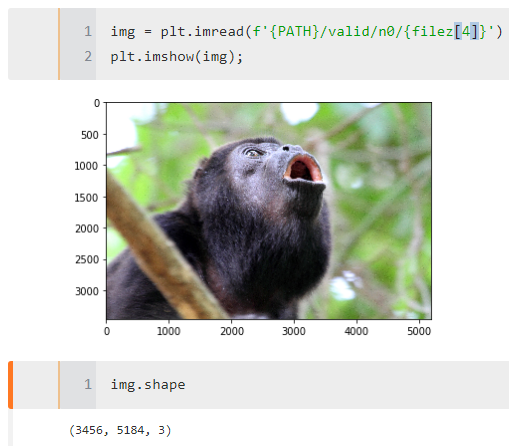
Now, I was feeding it Kaggle’s monkey species dataset, multi-categorical. As you may see from shape, pretty large ( == feature rich) pictures (although they are rescaled to 224). No test set, just a validation set.
.
Let’s see what happens here:
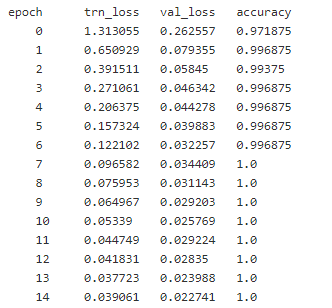
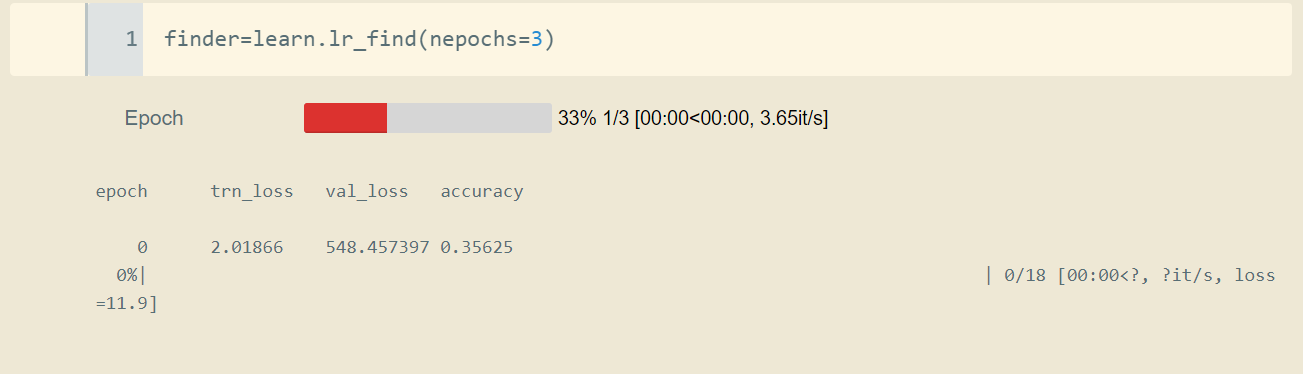
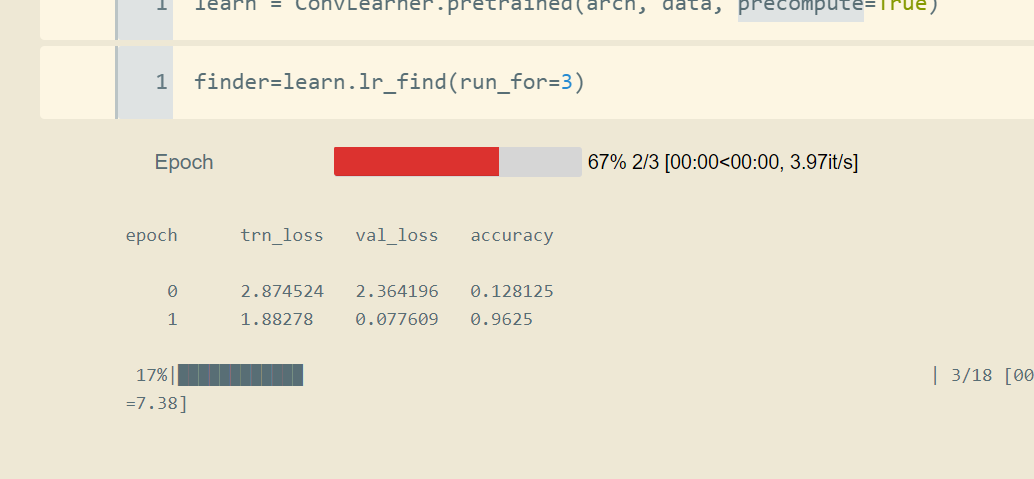
Note that, over 15 epochs:
- at the last epoch, the model still underfits (trn loss is still decreasing). Is that normal??
- we attain tremendous accuracy almost immediately.
- the accuracy stops improving (hard to improve over 1) and yet the validation loss is still decreasing at the last epoch. Why’s that??
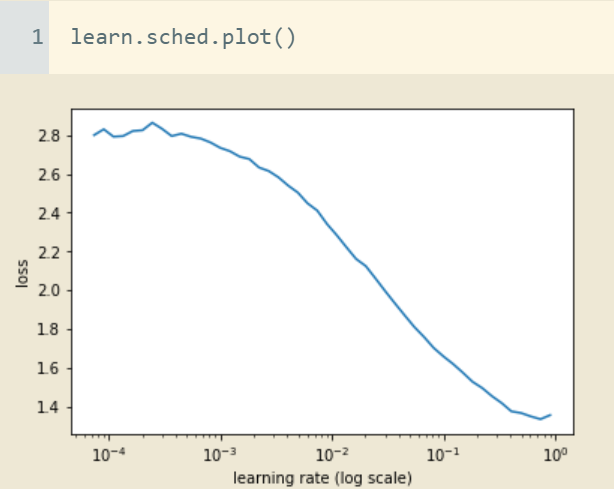
But the question I’d really like you to answer regards the learning rate. Let’s run the finder:
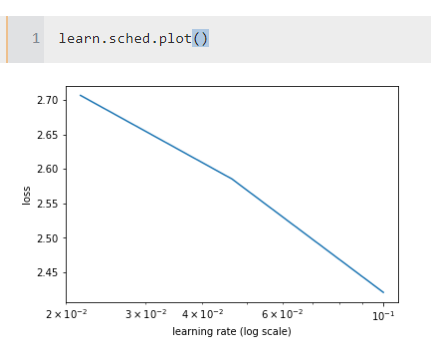
As you may see, the loss is still plummeting at the very right of the graph, suggesting we should test even larger LRs.
I’d like to know:
- How does fastai library selects the interval where it tests the learning rate vs. loss? How can I change the interval?
- What does the
n_skipparameter do? - No matter the graph above, LRs over 10^-1 do seem unreasonable. What do you think about this?
- Last but absolutely not least, loss in the range of ~2.x is not congruous.
Thanks a lot.