Nice observation! This has to do with so called dropout layers in the model. In these layers information is “thrown away” to avoid overfitting. The higher training loss means that the model is better in identifying correctly on the validationset (without dropout) than it is on the trainingsset (with dropout). This will all be explained later in the course.
Question from lesson-1 (codeblock 9 in the original notebook):
data.normalize(imagenet_stats)
imagenet_stats has following values: ([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
And it is defined in fastai/vision/data.py. In fact there are bunch of these: mnist_stats, cifar_stats. These numbers seem specific to an image datasets. Anybody knows how this works?
3 Likes
Thanks Jeremy. I’ve updated the notebook and 20 epochs is definitely better, getting me to 74% accuracy with the smaller model.
I tried a higher learning rate but that didn’t seem to help with either. Am I applying it correctly? I’ll read up on this some more as I don’t exactly understand what it’s doing under the hood.
Would love to see a deeper dive on this dataset in class - it’s available at https://storage.googleapis.com/bstovold-fastai/galaxies.tgz
that you’re still underfitting. So, you can keep trying to push those down further. In general, as long as your training loss is higher (or equal) to validation loss, while you keep reducing the error rate, it’s going all good.
1 Like
While most images will be public domain, if “published” as a dataset (whatever that means), I’d imagine they should definitely be cleared and/ or attributed. Within the context of this course and forum however, I’d be surprised if it’s a problem.
1 Like
This will all be made clear! ![]() You’re now overfitting. Try 10 epochs, then unfreeze, then 4 epochs.
You’re now overfitting. Try 10 epochs, then unfreeze, then 4 epochs.
I am currently working on a binary classification dataset. I used ImageDataBunch.from_folder() function to load all the images. I have created this as my custom dataset which comprise 100 images per class. The problem is whenever I try to run learn.recorder.plot() function it gives me a blank graph even though the learn.lr_find() doesn’t generate any error ?
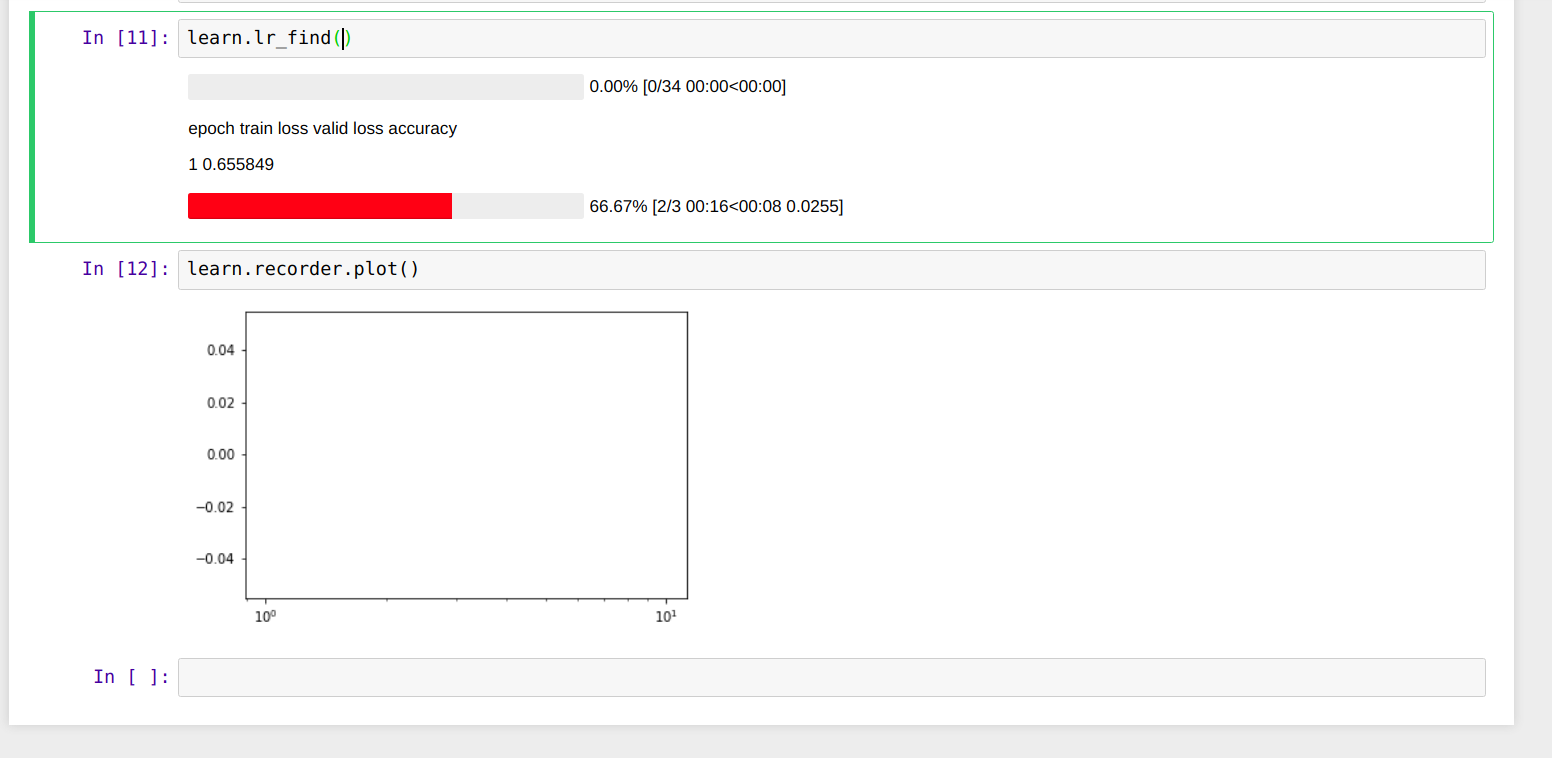
1 Like
Where is learn.save() store the data? I can’t really located in my GCP instance. I found the resnet model in .torch folder, but I don’t think the trained weight is there.
Definitely very interested. Let me know if you all form a group.
In your data directory, which by default is ~/.fastai/data/(folder)
I believe you ![]() 10 epochs, then unfreeze, then 4 epochs still has me at 74% accuracy on both models.
10 epochs, then unfreeze, then 4 epochs still has me at 74% accuracy on both models.
1 Like
Ah still overfitting! Try just 5 epochs in the first stage.
2 Likes
Hoping someone can help me understand what an epoch is.
Quick google search on what epoch is leading me here machine learning - Epoch vs Iteration when training neural networks - Stack Overflow
An epoch describes the number of times the algorithm sees the entire data set. So, each time the algorithm has seen all samples in the dataset, an epoch has completed.
So my question is, why would we run the same data through a neural net “x” times? Shouldn’t one pass through of the data be enough to obtain the weights?
I tried searching, but couldn’t find if this question was already answered somewhere (it was asked, but didn’t get enough likes):
What was the thought/insight behind changing the image size to 299 when using resnet50 (instead of the 224 that was used with resnet34)?
data = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=get_transforms(), size=299, bs=48)
1 Like
Bigger images generally get better accuracy, since they have more detail. Combining with a bigger model is often a good idea.
5 Likes
Got it, thanks @jeremy .
Follow up Q:
You gave some intuition on how we arrived at the 224 number (final layer being 7x7 - and we wanting 7 times to a power of 2)
Was there a specific thought behind 299? (not divisible by a power of 2 in this case)
I guess your dataset is quite small for your current batch size, so lr_finder don’t go through enough iterations. On top of that, learn.recorder.plot, skip some iterations when plotting. You should consider:
- Using
learn.recorder.plot(skip_start=0, skip_end=0)in order to avoid spiking iterations when plotting. - Reducing your batch size, in order to increase the number of batches.
Hope it helps.
1 Like
For some reason some imagenet networks were pretrained at 299 - and using the same size as the original can help a little. I can’t recall if rn50 was one of those; I guess it’s kinda a habit for me to try it.
2 Likes
@MagnIeeT Check this this out! the use case we were discussing a few months back 
1 Like
ok 