I have trained a ‘Aeroplanes vs Helicopters’ dataset using ResNet34 pre-trained model and here is the following information -
-
Images - Aeroplanes - 216, helicopters - 350
-
25% of this data is kept in validation set
-
Initial Validation accuracy with bs=8 and LR=0.01 is 91%
-
Learning rate finder plot is slightly weird
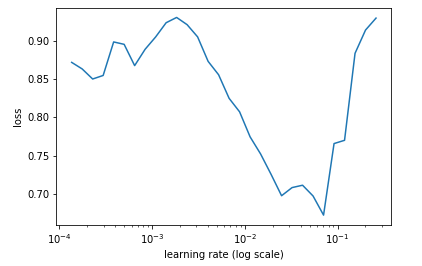
-
I have chosen 0.01 as learning rate though.
-
Augmenting the data and training the model again didn’t improve the accuracy (It actually came down to 89.5%)
-
Later used 3 cycles of 1 epoch each and reached 92.3% accuracy (Train and Validation losses at 0.24 and 0.23 respectively)
-
Unfroze the initial layers and learn.fit(lr, 5, cycle_len=1, cycle_mult=2)
This seems to overfit my data as I can see that my training loss is decreasing but my validation loss is more or less fluctuating around same range. Final accuracy is 92.3%

My 2 questions -
- Why did Data Augmentation didn’t exactly improve the model in this case?
- Although TTA gave final accuracy of 94.4% accuracy, I would like to know if this is the maximum I can get with this data. (6 incorrect aeroplanes, 2 incorrect helicopters)
Incorrect Aeroplanes -
Incorrect Helicopters -


Thanks!