Just got started with FastAI and getting addicted pretty quickly
I’m doing the homework assignment, and I’m getting scores for the Kaggle competition above 15 (not good). I’ve spent some time debugging this. At first, I realized that the ids in the file were incorrect due to how get_batches iterates through the directory of test images, but even after correcting for that, I’m still in the 15s.
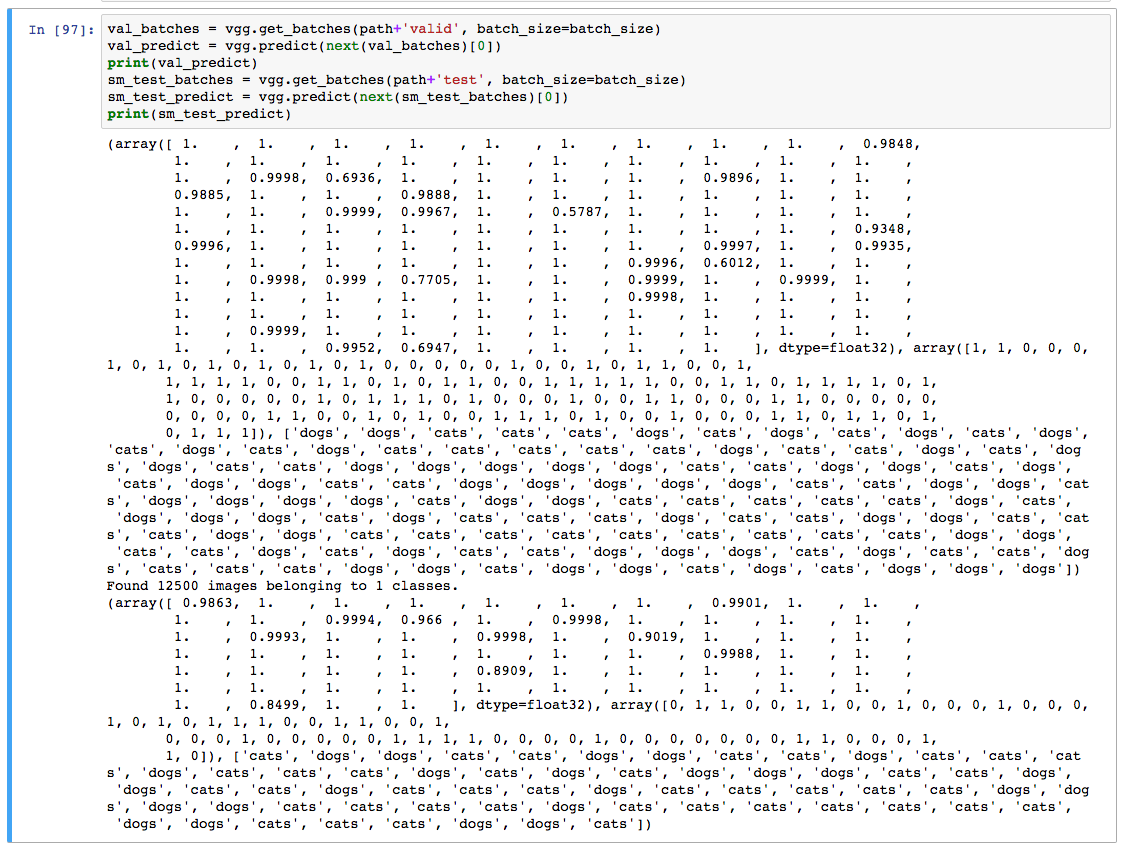
As I dug around, I noticed that there were lots of 1.0 probabilities in my results file. I thought to myself “that doesn’t make sense – the chances of getting a 1.0 on the validation data should be low, let alone on the test data”
But sure enough, when I run a prediction on a small set of both the test data and the validation data, I get tons of 1.0 probabilities.
Jeremy mentioned in one of the lessons that the classifier net used for that example tends to produce overconfident results. One way to avoid it is to increase the temperature of the softmax (if you were using one) (cf.https://www.cs.toronto.edu/~hinton/absps/distillation.pdf ). But more easily, just np.clip() the probabilities between 0.05 and 0.95. The crossentropy loss function hits you hard if you are maximally confident but you happen to get the prediction wrong.
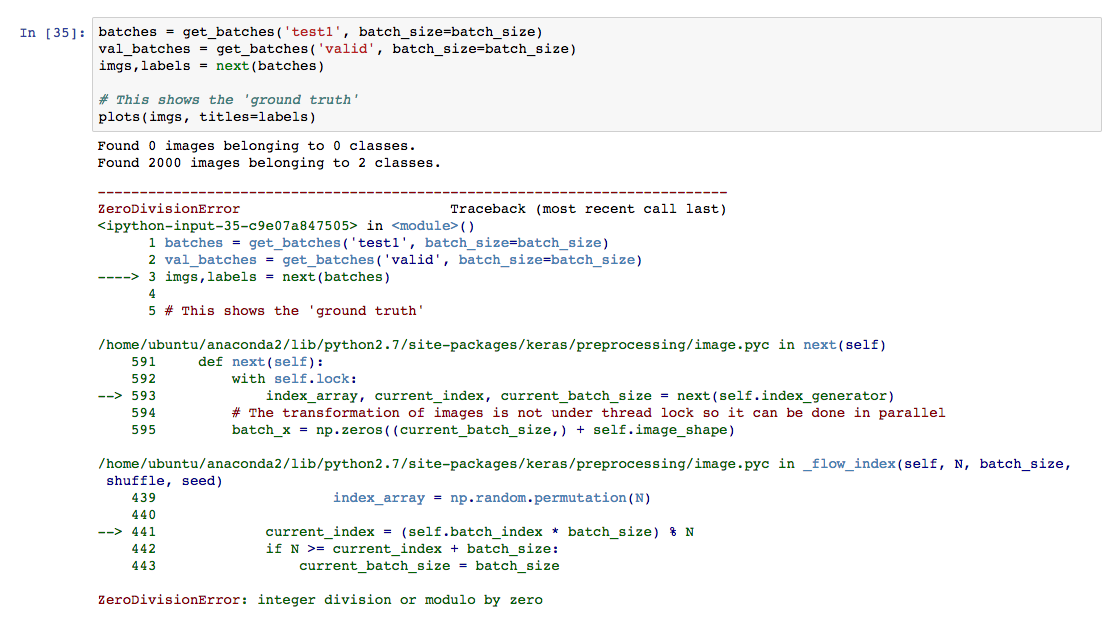
I’m running into errors when trying to run get_batches on my test directory containing unlabeled dog and cat images. I’m working on step 11 of the homework for lesson 1. The structure of /test1 is simple: it doesn’t contain any subdirectories and only contains the set of unlabeled images.
Looking at the error messages, it seems like the error is occurring image.pyc in the flow_index method which has the function signature:
_flow_index(self, N, batch_size, shuffle, seed)
I’m having a hard time seeing why N is getting the value 0. Has anyone else run into this problem?
Edit: this issue doesn’t happen for /train which does have two subdirectories…my suspicion is that the issue has to do with directory structure, but I’m not sure.
After a while with no feedback, I stopped the kernel and run it again and then it gives a different error
AttributeError Traceback (most recent call last)
in ()
----> 1 import utils; reload(utils)
2 from utils import plots
/home/yousry/nbs/utils.py in ()
26 from IPython.lib.display import FileLink
27
—> 28 import theano
29 from theano import shared, tensor as T
30 from theano.tensor.nnet import conv2d, nnet
/home/yousry/anaconda2/lib/python2.7/site-packages/theano/init.pyc in ()
98 # needed during that phase.
99 import theano.tests
→ 100 if hasattr(theano.tests, “TheanoNoseTester”):
101 test = theano.tests.TheanoNoseTester().test
102 else:
AttributeError: ‘module’ object has no attribute ‘tests’
I tried to update Theano to latest version [0.9.0rc4] but still got the same error
So my problem was due to using Ubuntu 16.1 instead of Ubuntu 16.04
Also the shell script for adding Theano config was missing the below which seems to be critical to make it use GPU
Those two lines are found in the AWS setup script
[cuda]
root = /usr/local/cuda
Anyway, this passed the above errors but it seems the Keras copy installed has some problem as shown below
ImportError Traceback (most recent call last)
in ()
----> 1 import utils; reload(utils)
2 from utils import plots
/home/yousry/courses/deeplearning1/nbs/utils.py in ()
40 from keras.layers import TimeDistributed, Activation, SimpleRNN, GRU
41 from keras.layers.core import Flatten, Dense, Dropout, Lambda
—> 42 from keras.regularizers import l2, activity_l2, l1, activity_l1
43 from keras.layers.normalization import BatchNormalization
44 from keras.optimizers import SGD, RMSprop, Adam
ImportError: cannot import name activity_l2
Will see what I can do but help is really appreciated
When it tries to initialize Vgg16 it came back with an error, it says requires h5py (when it tries to load the weights) I downloaded the model properly and install h5py also.
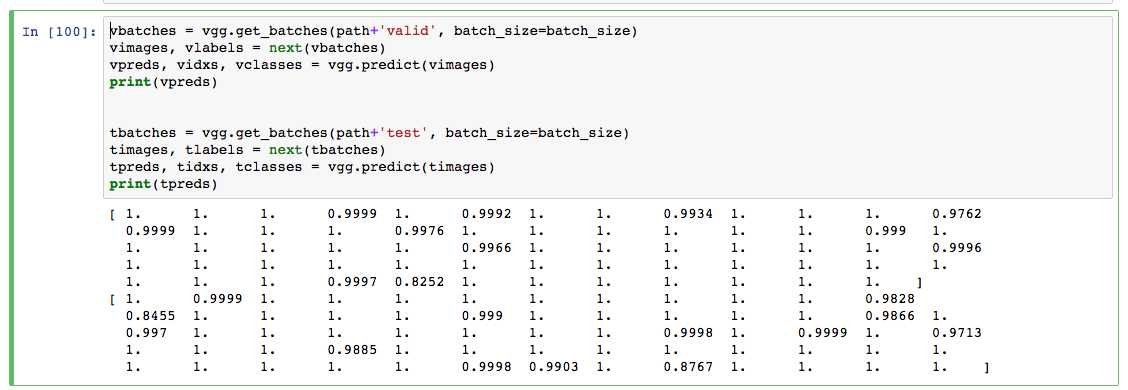
Thank you very much for that, Jose! I want to add some color here so anyone else seeing similar scores can learn from my mistakes. While it’s true that bounding probabilities does improve performance, my problem was a typo. Notice in my screenshot above how none of the probabilities were close to 0? Well that should have been my first clue. I had simply typo’d my python code that took the output from vgg.predict.
With the typo, my score was 15.41851. With the typo fixed, my score dropped to 0.20384. Using Jose’s clipping technique, I got all the way down to 0.10064!
While training in the jupyter notebook, getting invalid unicode characters rendering as boxes in the end, after the accuracy values etc Should I set some encoding in environment variables?
In container, (following install_gpu.sh) apt-get update, install anaconda, set PATH, install cunn (CUDA comes with the container image), install/configure keras/theano, configure jupyter without password.

{kind=link}