@lesscomfortable the javascript which you have added for downloading the url file for the images is not working .
urls = Array.from(document.querySelectorAll(’.rg_di .rg_meta’)).map(el=>JSON.parse(el.textContent).ou);
window.open(‘data:text/csv;charset=utf-8,’ + escape(urls.join(’\n’)));
Hello, when collecting my own data set, let’s say collecting images of insects, if images in a training set have paper labels (e.g. species and size indicator of the insect), would you recommend to crop this area out, especially images in a test set are not likely to have these paper labels?
Thanks, the access control is not a problem now but when i run data = ImageDataBunch.from_folder(path)
I am getting this ValueError: num_samples should be a positive integeral value, but got num_samples=0 .
Listing a few doubts that i got while working on different experiments. Any help is appreciated.
The data and learner pipeline is breaking we are using batch size = 1. Though higher batch sizes are preferred, the pipeline is supposed to work for batch size of 1 as well ryt?
Error while trying to run learner.fit
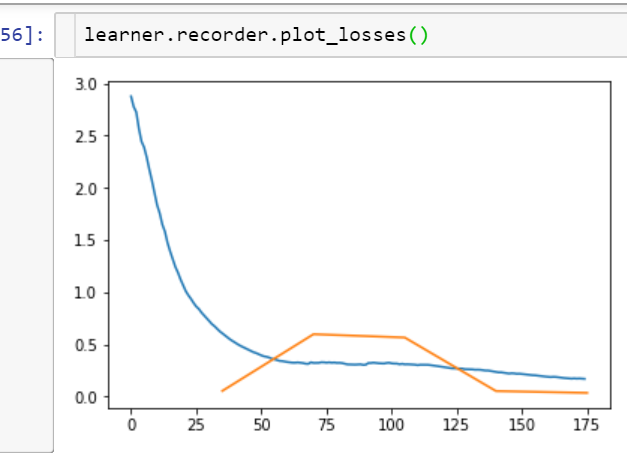
recorder.plot_losses starts plotting validation loss after 1 epoch. Any specific reason for this?
Is there a way to get reproducible results using random.seed() in someway for fastai models?
Currently way of defining np.random.seed() doesnt give reproducible results!! Tried a few things from these links as well but couldnt get reproducible results.
Is there a way we can get back the file names of specific images for e.g.that are wrongly classified or those having top losses?
Since i was working with images generated from audio in an example, plotting the images as such dint help much but checking those audio clips if something is wrong in annotation or too background noise etc. would have helped
These are the layers appended to the resnet34 model after chopping off some of its end layers.
You can get all of its code by just going into the ConvLearner source code.
??ConvLearner
??create_head
??bn_drop_lin
Diving into just these 3 functions will give you a decent idea of what’s happening.
Even if you don’t get precisely what’s happening in each line of the code, you can simply refer to the docstring to get a big picture of what’s happening in that function.
Not quite - if you go back and listen to the lesson at this point, you’ll here that the first one was simply to show that a poor learning rate choice means I needed to find a better one.
But MaxPool layers don’t retain the relative positions {what I’ve read on internet, I’m not sure though}. This is addressed in Capsule Networks. These networks work more like inverse graphics. This video covers the core content of the paper. This is a very recent area of research.
@jeremy what are your thoughts on Capsule Networks? Are they really better than ConvNets and is it worth learning them?
My understanding was when we unfreeze and fit we are trying to see if we have choosen good pretrained model or not and with this if we can go ahead and fine tune further to get the most out of this model.
Thanks for correcting me @jeremy but now I wonder is there any guideline for the model selection for eg. we have resnet34, 50, 101 etc how to choose one and when.
I have been digging inside the fastai library to find out where the loss function is defined for the learner in Lesson 1. The optimizer is by default “Adam” and is defined in the class Learner which is inherited by ConvLearner. But I am not able to find where the loss function which happens to be F.cross_entropy is defined. Any help is appreciated.
Thanks—maybe there is nothing better to do than what you and Michael suggested. I was just hoping there is a way to reduce the human effort. I guess in addition to checking the validation set, one could train and validate on different subsets and gradually clear up the mislabeled data on the whole dataset. I’d love it if there was any additional automation to reduce the effort in such tasks.
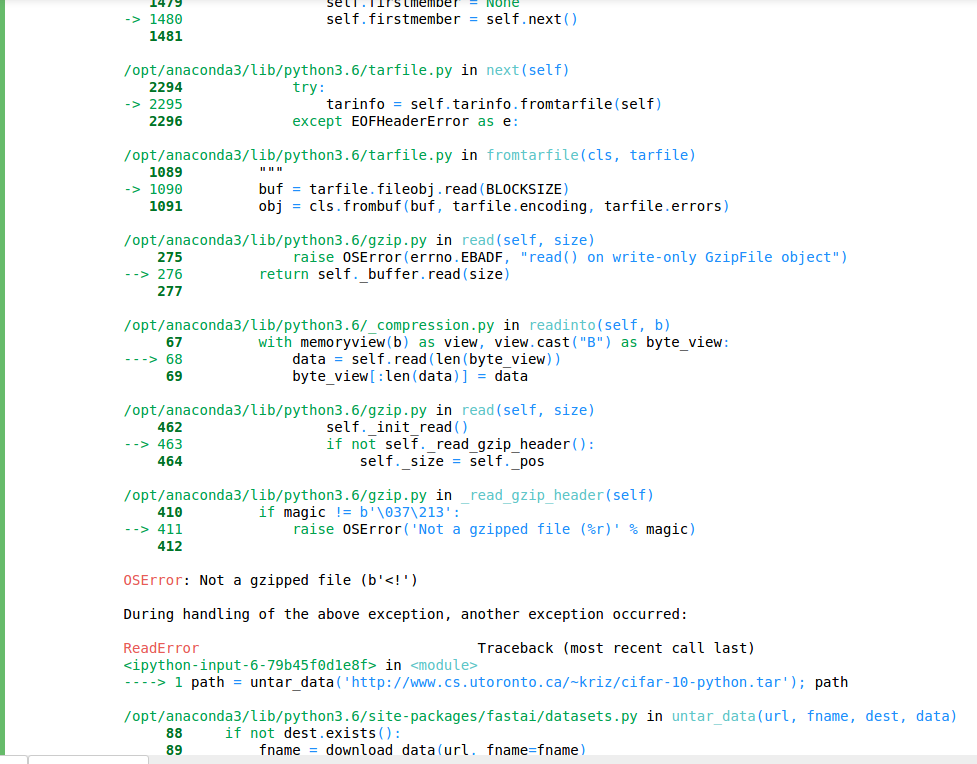
I got this resolved. The issue is because of the extension .tar.gz. untar_data function is not treating tar.gz as a gzip file. But actually .tar.gz extension means the same as .tgz. I managed to get the dataset URL with .tgz extension and using this URL excluding the extension solved my issue.