I have worked through the first two lessons and am now going through them again but this time with my own problem and data set in mind. I want to implement a model that classifies playing cards (Ace of Hearts, Jack of Spades, Four of diamonds, etc).
I created a set of images (~300) from a couple different decks of cards (all digital, not photos of cards).
My first attempt was to try to simplify the problem into two separate models. One model to classify the suit (spades, diamonds, hearts, or clubs) and another model to classify the rank (two, three, four, etc).
It seems like the model classifying the suit was able to reach 100% accuracy (but I’m worried it might be overfit?).
However, the model trying to classify the rank does not do well at all. I’m pretty surprised by this because it feels like a simpler version of MNIST where there is no bad handwriting, all the characters are perfectly drawn so it should be quite simple.
Some of the cards have the rank drawn twice on the face of the card… some of the cards have dark background (most have white background).
Any ideas for what else to try to improve the rank classifier? I’m thinking maybe an extra preprocessing step that attempts to filter out the background color so they all are black/white or grayscale might help.
The other thing I had done was remove all transformations when building the data bunch because these aren’t photos. I don’t want any cropping / rotation / etc. I guess maybe it doesn’t make sense to use ImageNET pretrained weights for this use case?
Can I dive into why you’re not doing any transformations? It’ll substantially increase the number of training examples at no additional cost. Given you’re trying to predict on 13 classes, you only have ~23 training samples for each class. I’d give a read through of the transform docs (https://docs.fast.ai/vision.transform.html) and try training two models - one with transforms and one without.
My thought was that in my situation (playing cards on a desktop computer) think online casino / poker room are ALWAYS in the same orientation (perfectly vertical, 0 rotation or cropping). So I thought that by performing transformations the training examples would not be representative of the future test set.
The other concern I had was that my training/validation sets are already full width and full height cards (there’s no background image, the image is just the card itself) so any cropping ends up losing information about the card.
How do you think I should approach transformations in this case?
It seems like ideally I would keep all transforms except for one’s that crop/zoom/flip. I see I can pass do_flip=False and max_zoom=1.0 to get_transforms() to disable those. But I don’t see anyway to control resize/crop.
Ideally I would use ResizeMethod.PAD as a lot of the useful information on a playing card is often in the top left corner. I don’t see a way to use this option with get_transforms() default. I guess I’ll have to create my own custom set of transforms?
Also, I didn’t realize that the transformed versions of the cards are additive (in the sense that they keep all originals AND the transformed versions) in the training set. I thought it was only the transformed ones.
I put back the transforms without flip or zoom and restricted size to (224,224) which removes the cropping. I can’t figure out how to easily use ‘zeroes’ for padding instead of the default reflection as I think reflection can introduce some oddities into the image.
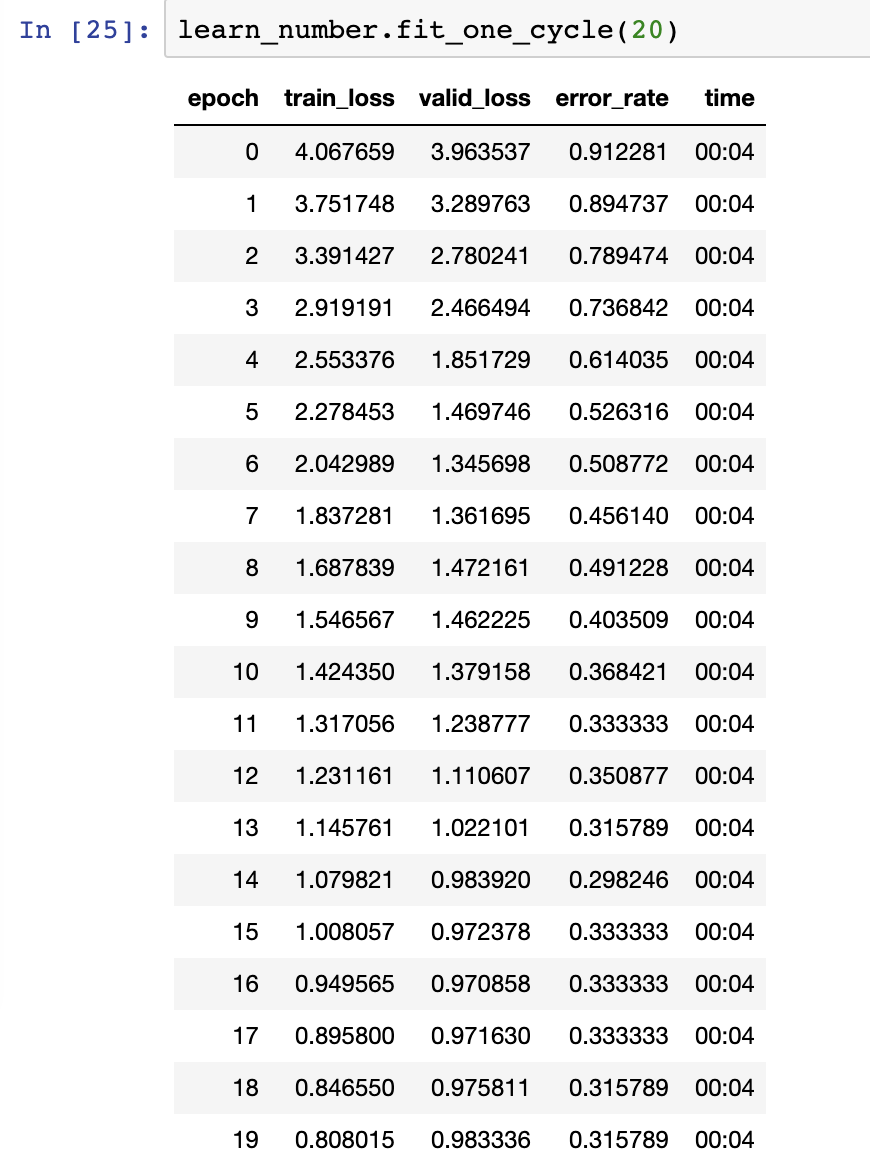
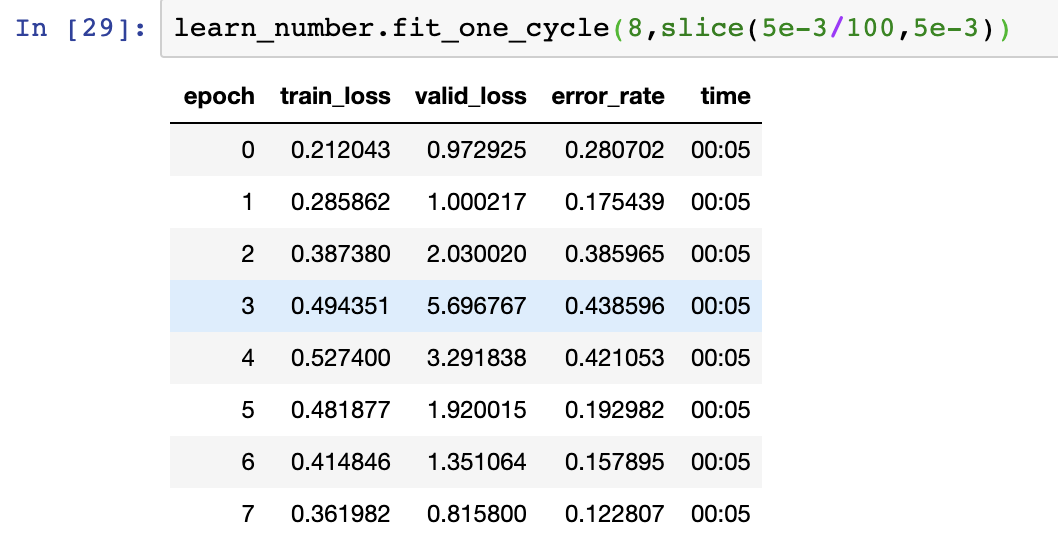
With the new transforms and resnet50 I was able to get down to 31% error rate with:
If I look at the errors it’s almost all from classifying Kings as Aces. Weird. I think I might just need more data at this point? It still feels like this should be an easy problem compared to classifying 35 breeds of dogs. I’d expect to be able to get near 100% accuracy.
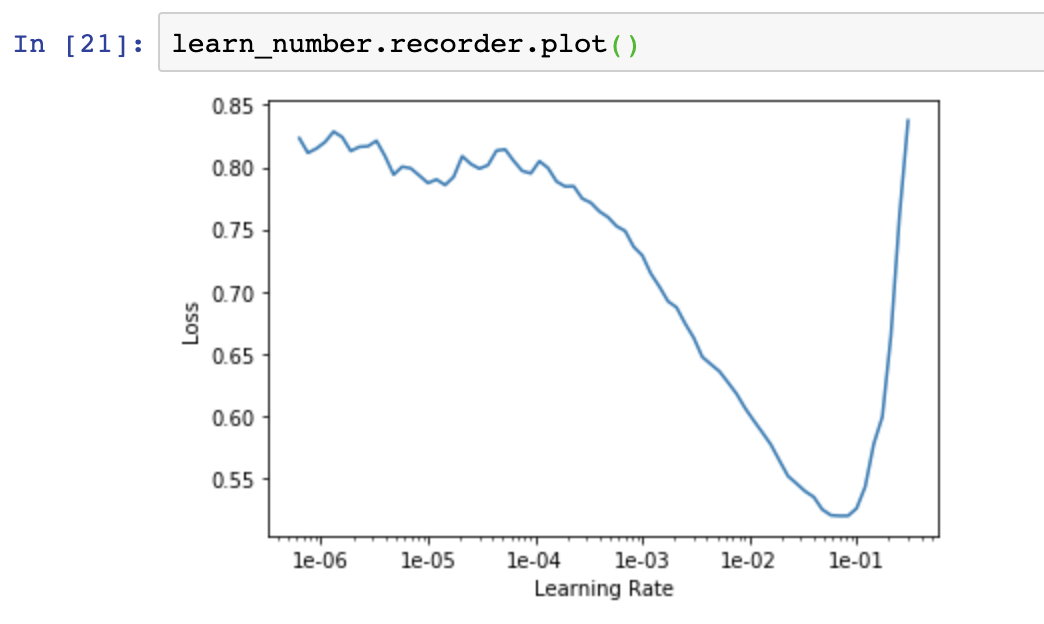
Are my LR tweaks okay based on the LR plot I showed? Any other tips / thoughts?
Sounds like progress! The transformations in this case are less about teaching the network to recognize off-center cards than it is to get “free” training samples. I would say, at this point, you would benefit from more training data. In either lesson 2 or 3 (can’t remember), Jeremey shows a handy script to scrape images from Google Images - perhaps give that a try?
Another option is to resize your images down to something like 128x128, train that model, then resize the pics to 256x256 and keep training. It’s always helped my accuracy scores and, again, gives you more synthetic training examples.
My intuition on the difficulty here is that the cards are ALMOST exactly the same (compared to dog breeds which have more variance). Even if you start by upping your examples of your problem classes, you should see improvement.
Thanks! I’ll create some more training examples and see how/if that helps. I’ve largely been creating them manually from different poker/casino sites. Sourcing some from google images like Jeremey does in lesson 2 might be interesting to try.
Interesting thought about them being almost the same hence making it harder to differentiate. I’m also using card images from different ‘themed’ decks. That is likely making it a bit harder as well.
It’s me again and I doubt that I will ever stop unless I get all the answers I need
I’ve heard on some other forum that the syndicate casinos is pretty much way to go for all people who want to link gambling games/activities and ML. I won’t link the casino in order to avoid ban but here’s an article is syndicate casino legit