After finishing lesson 1, I went ahead and collected images for my own dataset in order to train a model to learn from it. The subject I chose to classify were herbs (specifically sweet basil, Thai basil, cilantro/coriander, and Italian parsley). I built my dataset using the lesson2-download notebook and manually cleaned the data (I’m using Google Colab so certain cells in that notebook could not be run).
My first time training the model, I used 4 epochs and I got an error rate of about ~21%. I continued the steps in the notebook, unfreezing the model then training it with specific learning rates passed into fit_one_cycle. After finishing all this, I decided I wanted to try and get a better error rate, so I restarted the runtime, and repeated the steps. However, this time I used 8 epochs instead of 4 (the bottom of the notebook stated that one of the things that could go wrong was training with too little epochs, so I decided to double the original amount).
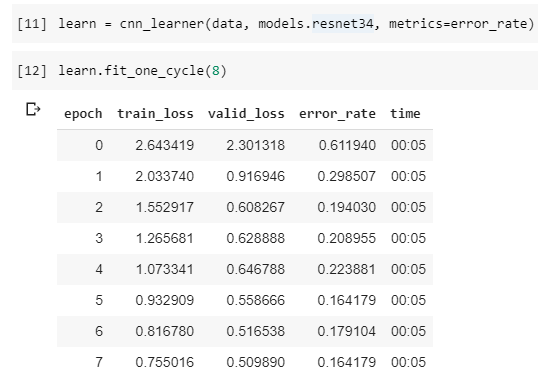
What I’m confused about is the resulting error rates:
Can anyone explain to me how the error rate can fluctuate (epoch 2-5) where it goes down then up then back down? Could it somehow be the nature of my data? I had a very hard time distinguishing certain images of herbs from one another (cilantro vs parsley).
Please let me know if there is any other information I can provide that would make anything more clear! Thank you so much. I appreciate any input/advice
In my experience if your classes are very similar then the techniques in lesson 1 are not quite enough to classify some images with great accuracy. if you change your classes to something very different like parsley, roses and zucchini you will likely see the results improve.
For my first classifier I built a wristwatch classifier it was good with 3 classes Rolex, Breitling and Cartier as I added classes the accuracy dropped. I continued until I had 60 classes but from about 4 classes it was very poor and deteriorated to unusable.
I decided then I would have to use other tools like adding Optical Character recognition to recognize the brand names. I am still learning so haven’t solved this problem yet.
Also in video video 1 at about 1hr 9m Jeremy talks about classifying cats and interp.plot_top_losses() this shows you what your network was confident on but got wrong. Also the confusion Matrix (1hr 13m) shows you the images that the network is struggling with. Also interp.most_confused gives a list of predicted and actual images it got wrong.
Can anyone explain to me how the error rate can fluctuate (epoch 2-5) where it goes down then up then back down?
According to the details in lesson two you never want a model where your training loss is higher than your validation loss. This normally means you have not fitted enough, which indicates that either your learning rate is too low or you haven’t trained for enough epochs. So I would try some more epochs or changing the learning rate and training some more.
Can’t explain the fluctuations still learning as I normally focus on the relationship between train_loss and valid_loss and error rate. From your image it looks like if you carry on training your error rate might improve.
Hey! Thanks for the reply and input. I’m about to start on lesson 2 so hopefully I’ll gain more insight on the things you were talking about. I’ll also play around with the learning rate/# of epochs as you suggested.