I’m trying to implement a Music Genre Classifier using CNNs, wherein I first convert music file into a spectrogram( Image for representing audio in frequency vs time graph) and then pass into the CNN model to classify it.
I first created the spectrograms of the music files in GTZAN dataset which contains 100 examples for 10 genres, using a python script.
I tried both fastai library and keras for this model, but the not even getting accuracy >35%
I have already generated the spectrograms of the GTZAN dataset’s music file through a python script. Here’s the link to the dataset of the spectrogram
- Spectrogram RGB: https://drive.google.com/open?id=1SNky91nOdmM_5EdXa9DHIKNahLnb9TLE
- Spectrogram Grayscale: https://drive.google.com/drive/folders/1JKZO89Fw5UDLW0l5q-xitfV4ZdZKav9-
1) With RGB Images
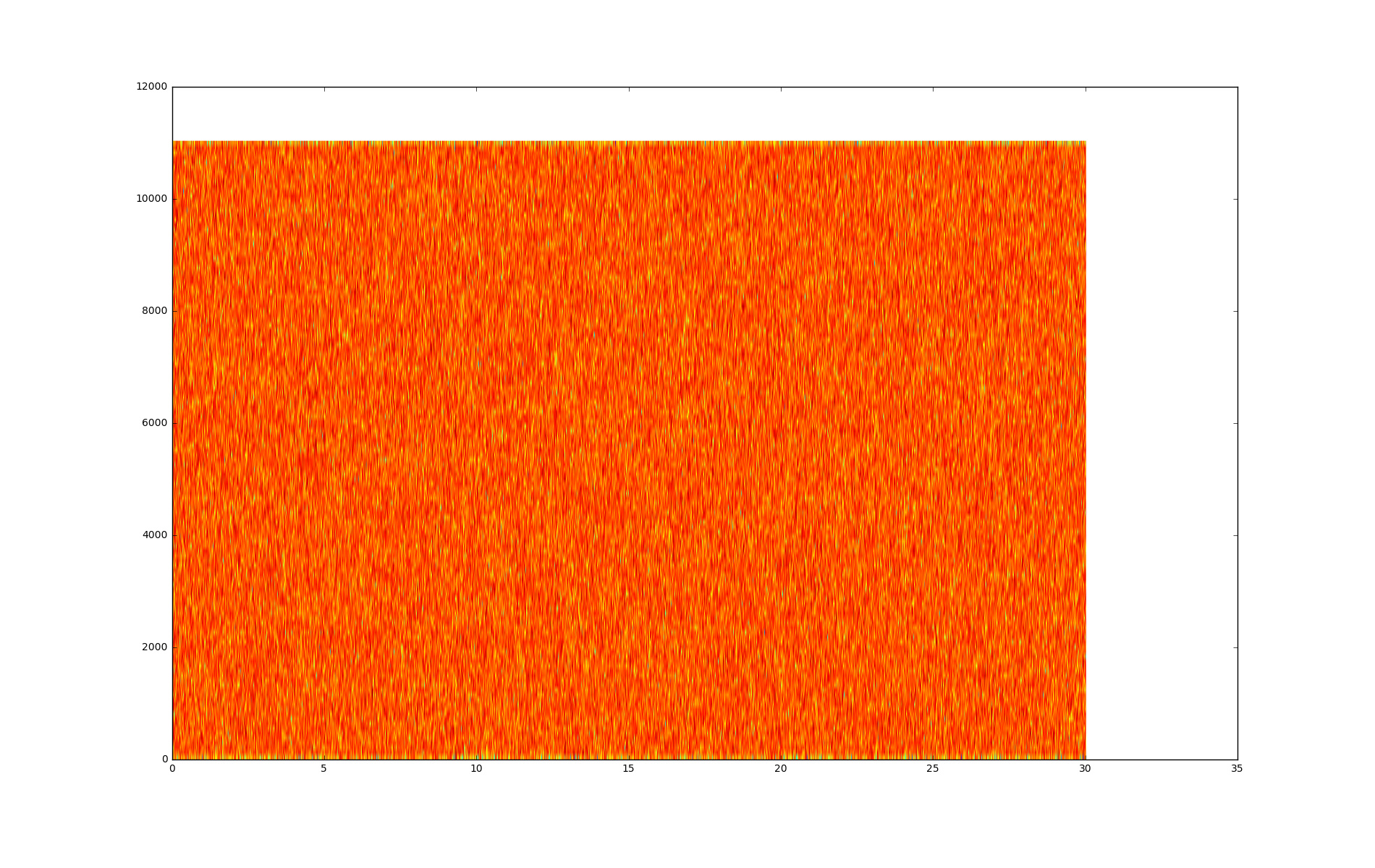
This is a spectrogram represeting a music file of rock genre
I distributed those images in same fashion, like in the cats v dogs wherein I created train,test,valid and sample folder. Then I ran the classifier of lesson 1 using resnet34 architecture, but I’m getting very less accuracy, about (14-35%) and the accuracy changes a lot even if I run the same cell again. Here’s the iPython Notebook and the data used for this notebook.
-
fastai Library(ResNet34) 18-30% Accuracy
https://drive.google.com/open?id=1uiM905qpV4JChb47YWPE2QIA7ige0zI8 -
Using keras
Inception: Upto 18% Accuracy
https://drive.google.com/open?id=1tV9WkYd2UaLj1g51AOTnXf57HKQTgZLS
ResNet50: Upto 20% Accuracy
https://drive.google.com/open?id=17ZhrELXrEsMgBKc8BCSg2ATkf4DZsc-6
2) With Grayscale Images
Then my friend suggested me, to convert those RGB spectrogram into grayscale spectrograms. I tried that, but didn’t work, I was getting the accuracy around 23% even after using the best learning rate from the learning rate finder.
This is a spectrogram represeting a music file of rock genre in grayscale

This is the notebook that I used for this.
-
fastai Library (ResNet34) 7-18% Accuracy
https://drive.google.com/open?id=1xNEnWjv5koxJOSyBOuI3ibDTs-knRQtT -
Using keras
Inception: 10-13% Accuracy
https://drive.google.com/open?id=1_VIVHy_MCgu2pPjxGgvBWcKpsHfX50-j
ResNet50: 11-17% Accuracy
https://drive.google.com/open?id=1OipBlrpo4h2BYTUFkX-qVNjUkBs_NWt5
I have been trying to improve the performance of the model by changing learning rate, changing the colour of the dataset(RGB->Grayscale) but didn’t get any satisfying results and slightly frustrated.
Please suggest any changes and the mistakes I’m making, so that it will help to improve the performance of the model. Also I tried to visualise the model in keras using the tensorboard, the model doesn’t starts training when the “write_grads=True”, in the callbacks.
Thanks!

 .
.