Sorry if it is a obvious question, I’m quite newbie to data science.
I would like to know why do we assume that once we find a minimum in learning rate vs loss we should stop around it. Are we assuming learning rate vs loss is a convex function? Shouldn’t we check in a completly different ranges before choosing (i.e: 10e-12; 10e-6; 10e3; 10e12, etc)? Thanks!
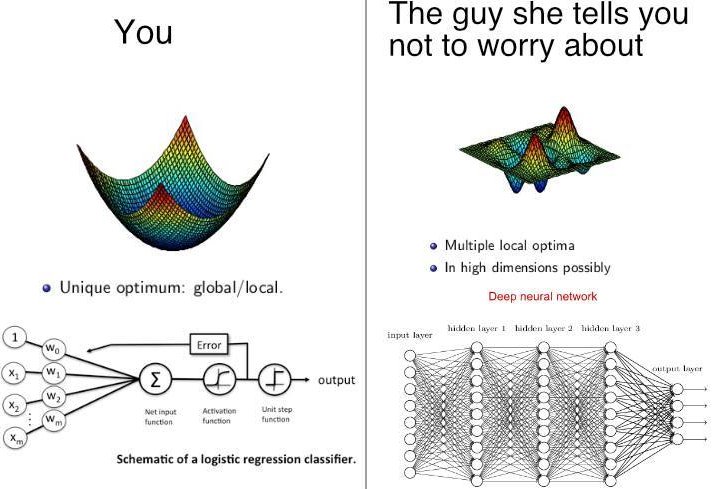
This is a good question. The loss function is not a convex function. Take a look at Lesson 1 Notebook - https://github.com/fastai/fastai/blob/master/courses/dl1/lesson1.ipynb, it has a diagram of multiple Minimums. Using Learning rate finder learn.lr_find() and Cyclical learning rate, we are hopefully getting to one of the better Minimums (lower loss values)
I still try to understand, how do we choose the scale into which we look for the optimal value. for example: why do we test test 10e-3, 10e-2, 10e-1 instead 10e-30, 10e-20, 10e-10, or even 10e-300, 10e-200, 10e-100 etc.
Because if you run with 10e-10, it will take much much longer to converge since you are making infinitely small updates to weights. When you start the network, the weights are all random. If you make tiny updates, it will take a very long time to move to good position. Goal is you want to converge fast - which is, you want set highest learning rate as possible. That’s what lr_find helps you do. I would suggest you re-watch parts of week1 and week2 videos where Jeremy goes this in much more detail.