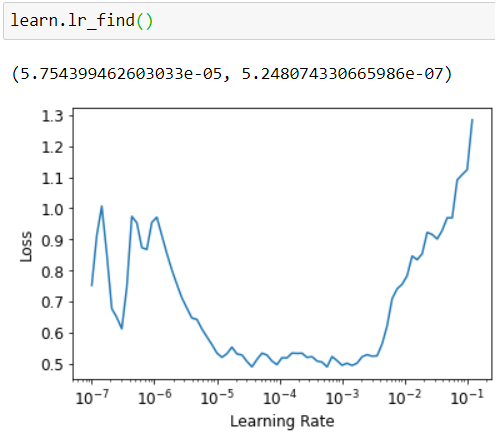
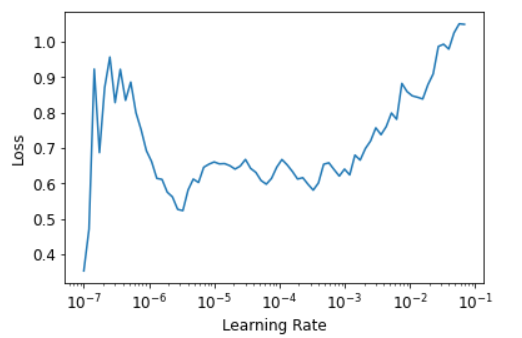
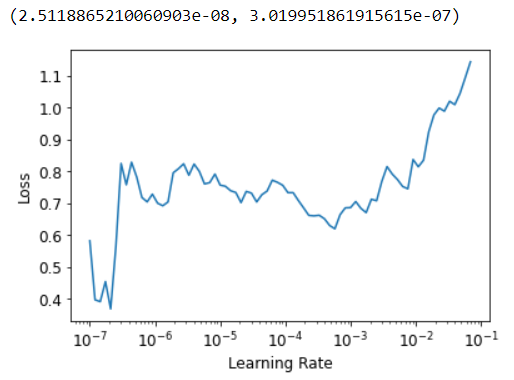
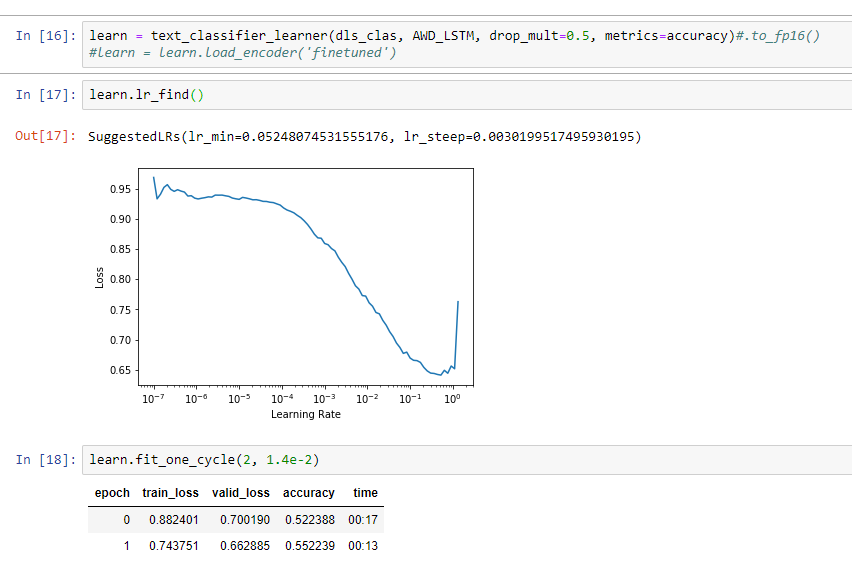
Sure! Here it is
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-12-0cf7fe200e35> in <module>()
----> 1 learn.fit_one_cycle(2, 1.4e-2)
~/anaconda3/lib/python3.6/site-packages/fastai2/callback/schedule.py in fit_one_cycle(self, n_epoch, lr_max, div, div_final, pct_start, wd, moms, cbs, reset_opt)
110 scheds = {'lr': combined_cos(pct_start, lr_max/div, lr_max, lr_max/div_final),
111 'mom': combined_cos(pct_start, *(self.moms if moms is None else moms))}
--> 112 self.fit(n_epoch, cbs=ParamScheduler(scheds)+L(cbs), reset_opt=reset_opt, wd=wd)
113
114 # Cell
~/anaconda3/lib/python3.6/site-packages/fastai2/learner.py in fit(self, n_epoch, lr, wd, cbs, reset_opt)
196
197 except CancelFitException: self('after_cancel_fit')
--> 198 finally: self('after_fit')
199
200 def validate(self, ds_idx=1, dl=None, cbs=None):
~/anaconda3/lib/python3.6/site-packages/fastai2/learner.py in __call__(self, event_name)
122 def ordered_cbs(self, cb_func): return [cb for cb in sort_by_run(self.cbs) if hasattr(cb, cb_func)]
123
--> 124 def __call__(self, event_name): L(event_name).map(self._call_one)
125 def _call_one(self, event_name):
126 assert hasattr(event, event_name)
~/anaconda3/lib/python3.6/site-packages/fastcore/foundation.py in map(self, f, *args, **kwargs)
370 else f.format if isinstance(f,str)
371 else f.__getitem__)
--> 372 return self._new(map(g, self))
373
374 def filter(self, f, negate=False, **kwargs):
~/anaconda3/lib/python3.6/site-packages/fastcore/foundation.py in _new(self, items, *args, **kwargs)
321 @property
322 def _xtra(self): return None
--> 323 def _new(self, items, *args, **kwargs): return type(self)(items, *args, use_list=None, **kwargs)
324 def __getitem__(self, idx): return self._get(idx) if is_indexer(idx) else L(self._get(idx), use_list=None)
325 def copy(self): return self._new(self.items.copy())
~/anaconda3/lib/python3.6/site-packages/fastcore/foundation.py in __call__(cls, x, *args, **kwargs)
39 return x
40
---> 41 res = super().__call__(*((x,) + args), **kwargs)
42 res._newchk = 0
43 return res
~/anaconda3/lib/python3.6/site-packages/fastcore/foundation.py in __init__(self, items, use_list, match, *rest)
312 if items is None: items = []
313 if (use_list is not None) or not _is_array(items):
--> 314 items = list(items) if use_list else _listify(items)
315 if match is not None:
316 if is_coll(match): match = len(match)
~/anaconda3/lib/python3.6/site-packages/fastcore/foundation.py in _listify(o)
248 if isinstance(o, list): return o
249 if isinstance(o, str) or _is_array(o): return [o]
--> 250 if is_iter(o): return list(o)
251 return [o]
252
~/anaconda3/lib/python3.6/site-packages/fastcore/foundation.py in __call__(self, *args, **kwargs)
214 if isinstance(v,_Arg): kwargs[k] = args.pop(v.i)
215 fargs = [args[x.i] if isinstance(x, _Arg) else x for x in self.pargs] + args[self.maxi+1:]
--> 216 return self.fn(*fargs, **kwargs)
217
218 # Cell
~/anaconda3/lib/python3.6/site-packages/fastai2/learner.py in _call_one(self, event_name)
125 def _call_one(self, event_name):
126 assert hasattr(event, event_name)
--> 127 [cb(event_name) for cb in sort_by_run(self.cbs)]
128
129 def _bn_bias_state(self, with_bias): return bn_bias_params(self.model, with_bias).map(self.opt.state)
~/anaconda3/lib/python3.6/site-packages/fastai2/learner.py in <listcomp>(.0)
125 def _call_one(self, event_name):
126 assert hasattr(event, event_name)
--> 127 [cb(event_name) for cb in sort_by_run(self.cbs)]
128
129 def _bn_bias_state(self, with_bias): return bn_bias_params(self.model, with_bias).map(self.opt.state)
~/anaconda3/lib/python3.6/site-packages/fastai2/callback/core.py in __call__(self, event_name)
22 _run = (event_name not in _inner_loop or (self.run_train and getattr(self, 'training', True)) or
23 (self.run_valid and not getattr(self, 'training', False)))
---> 24 if self.run and _run: getattr(self, event_name, noop)()
25 if event_name=='after_fit': self.run=True #Reset self.run to True at each end of fit
26
~/anaconda3/lib/python3.6/site-packages/fastai2/callback/fp16.py in after_fit(self)
66 run_before=TrainEvalCallback
67 def begin_fit(self): self.learn.model = convert_network(self.model, dtype=torch.float16)
---> 68 def after_fit(self): self.learn.model = convert_network(self.model, dtype=torch.float32)
69
70 # Cell
~/anaconda3/lib/python3.6/site-packages/fastai2/fp16_utils.py in convert_network(network, dtype)
68 convert_module(module, dtype)
69 if isinstance(module, torch.nn.RNNBase) or isinstance(module, torch.nn.modules.rnn.RNNBase):
---> 70 module.flatten_parameters()
71 return network
72
~/anaconda3/lib/python3.6/site-packages/torch/nn/modules/rnn.py in flatten_parameters(self)
127 all_weights, (4 if self.bias else 2),
128 self.input_size, rnn.get_cudnn_mode(self.mode), self.hidden_size, self.num_layers,
--> 129 self.batch_first, bool(self.bidirectional))
130
131 def _apply(self, fn):
RuntimeError: param_from.type() == param_to.type() INTERNAL ASSERT FAILED at /opt/conda/conda-bld/pytorch_1579022034529/work/aten/src/ATen/native/cudnn/RNN.cpp:541, please report a bug to PyTorch. parameter types mismatch