Hi @shay1309,
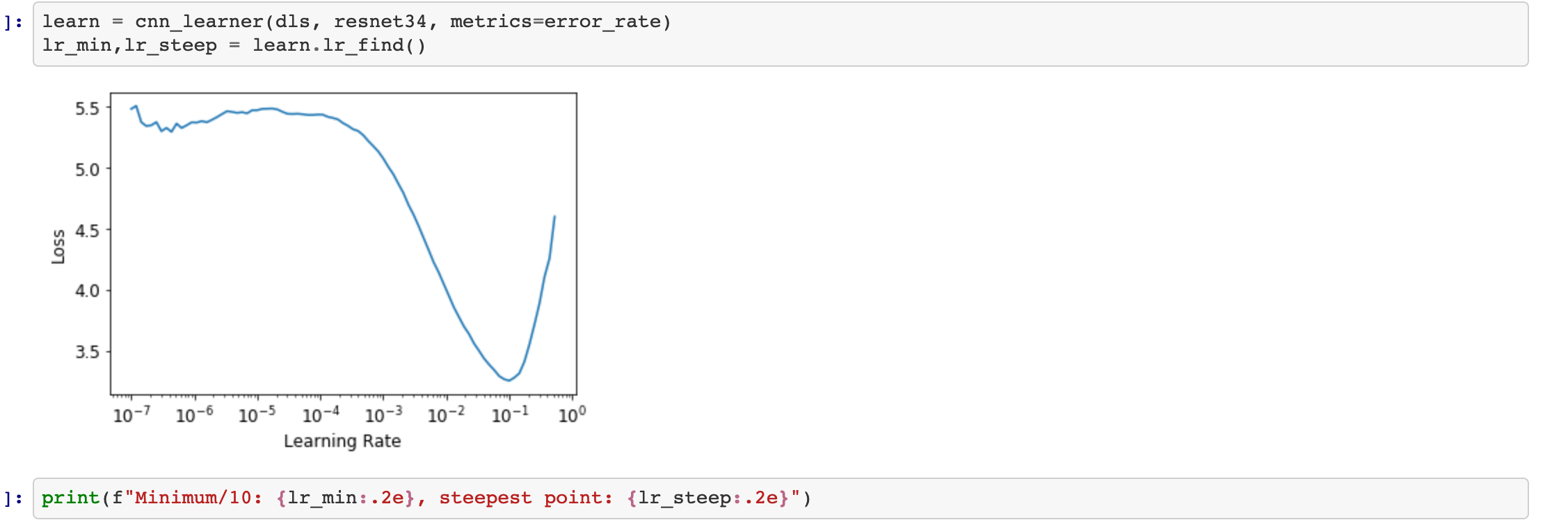
There is not an exact way to deduce this value. In general, in the video, Jeremy mentions the steepest point or the min divided by 10. Generally, you want to take a point in the slope, not too close to the end to have time to learn. In that case, they are quite a few possibilities and 3e-3 is right in the middle of the slope so it will work. You can maybe tweak it a bit better but for illustrative purposes it is close enough.
Hi Charles you helped once again, I see what you mean now, I thought that 3e-3 was one of the 2 stated values above converted from log to linear form … silly mistake forgot that he just took the average of the 2 values …
also Mr Charles, would you happen to know why we use
vs learn.fit_one_cycle(6, lr_max=5.5e-5)
In learn.fit_one_cycle(3, 3e-3) this was my first round of training just the last few layers ,
the round right after we create the learner …
For learn.fit_one_cycle(6, lr_max=5.5e-5) this was after i found the new learning rate is there a reason why we had t use lr_max … if i use lr_max then what was my initial lr and isnt lr supposed to be a constant that we multiply to the gradient … so why should I have a max i.e Why does is my lr a dynamic and not a constant value ?
Hi @shay1309,
learn.fit_one_cycle(6, lr_max=5.5e-5) and learn.fit_one_cycle(6, 5.5e-5) are the same. In general, Jeremy keeps it implicit as ‘lr_max’ is not required but to illustrate that ,NO, the learning rate is not constant he writes it explicitly this time.
When learning rate is taught on tutorials, it is constant yes but in reality, all optimisers adapt it with time, reducing it as we get closer to the minimum of the loss function.
The particularity of fit_one_cycle is that it progressively increases the learning rate until lr_maxand then reduces it. The rational behind it is that initially, you start from random and ‘do not necessarily know where to go’ (so the learning rate should start small) and after a few epochs, you are more confident about what you are learning and can speed up (increase the learning rate). In the ultimate phase you should slow down again to not pass the minimum and avoid diverging.
Hi, get_x is user defined in that case. It has been defined to return the file names in a given folder. Here it is fine to use it as we know the dataset is clean but if there was a text file in the folder, it would also select it and that would be a problem. get_image_files is a FastAI function that you can reuse for other datasets, it basically return all the image files in the path you give to it (using the extension of the files).