Hi all,
So I am training a text classifier on my custom dataset annotated it manually. Currently I was able to annotate 1700 text comments with an average length of 30-50 tokens in each comment.
I have gone through the steps of Part-1, Lesson-4 for NLP i.e. IMDB reviews. While running the classifier I was plotting the learn.recorder.plot() and was not happy with the results. 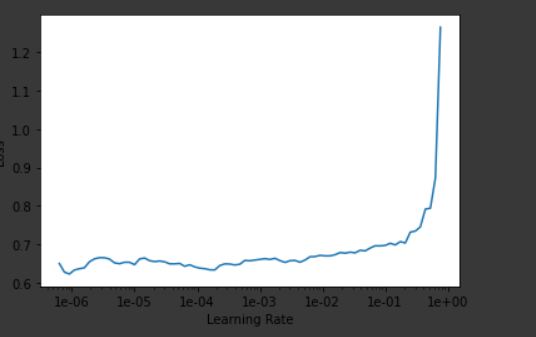
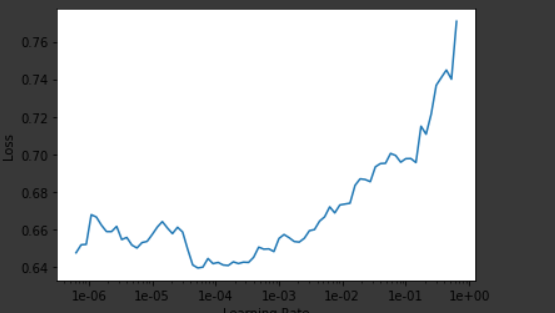
Please suggest the next steps that I can try.
Thanks