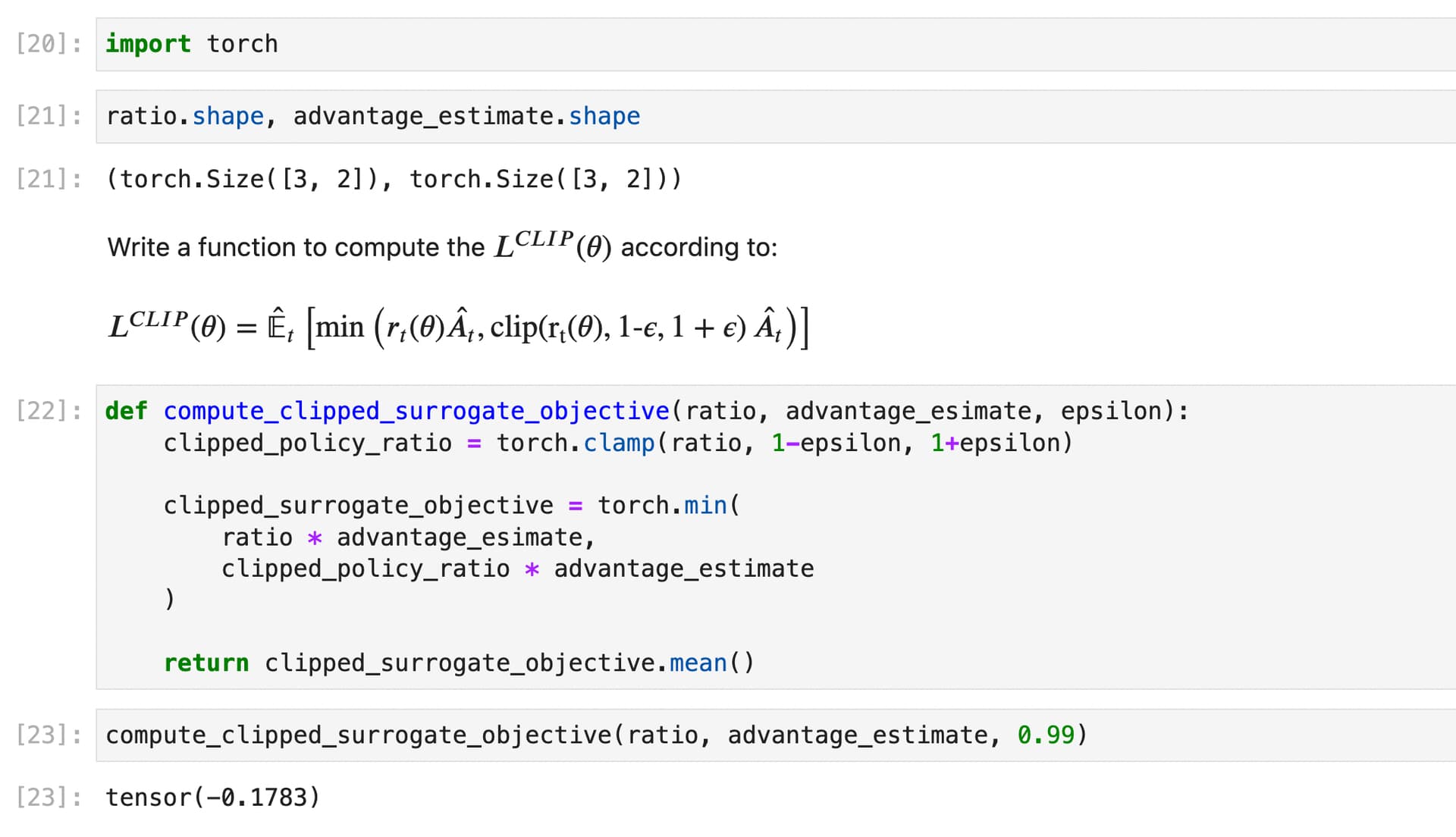
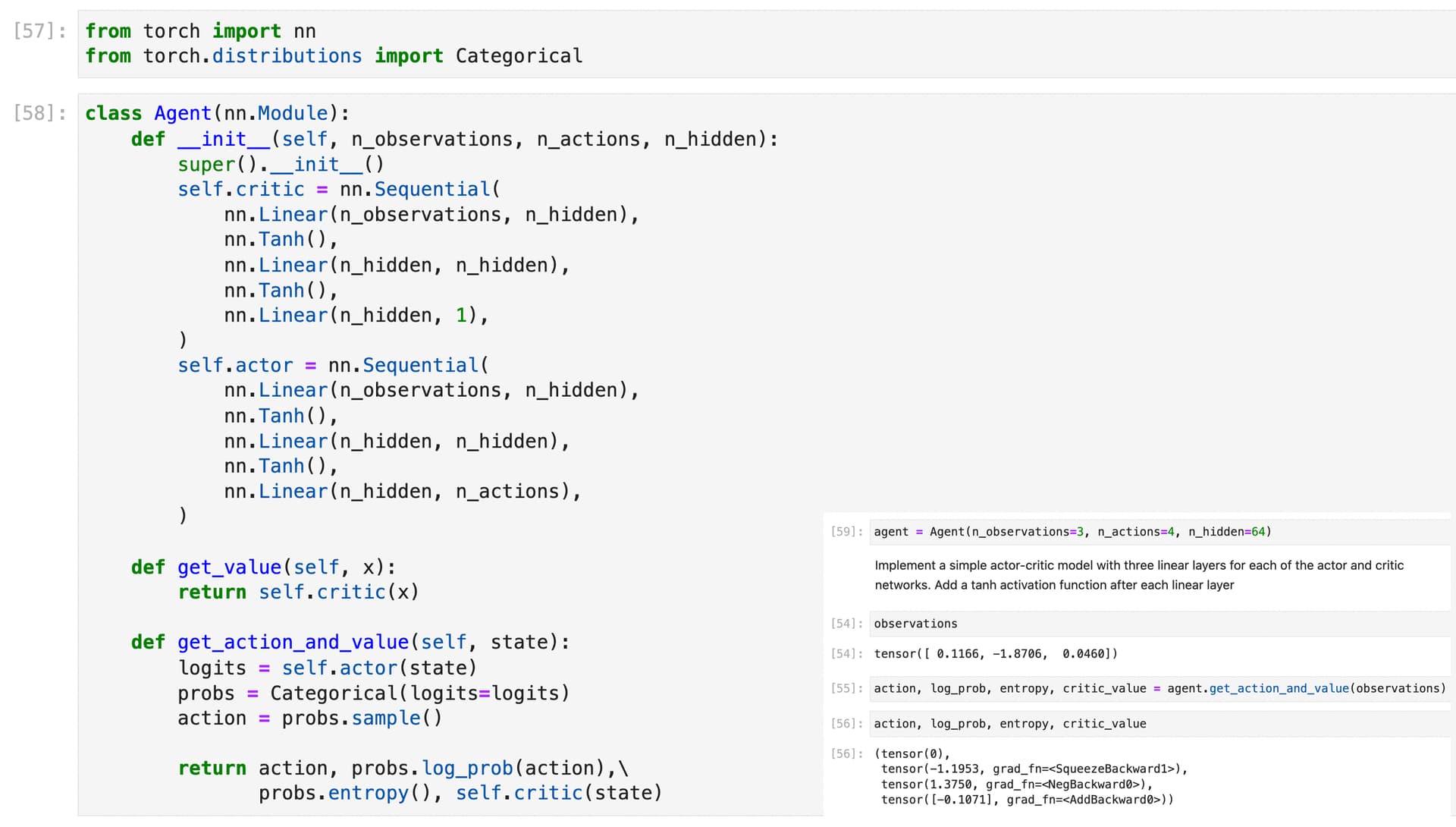
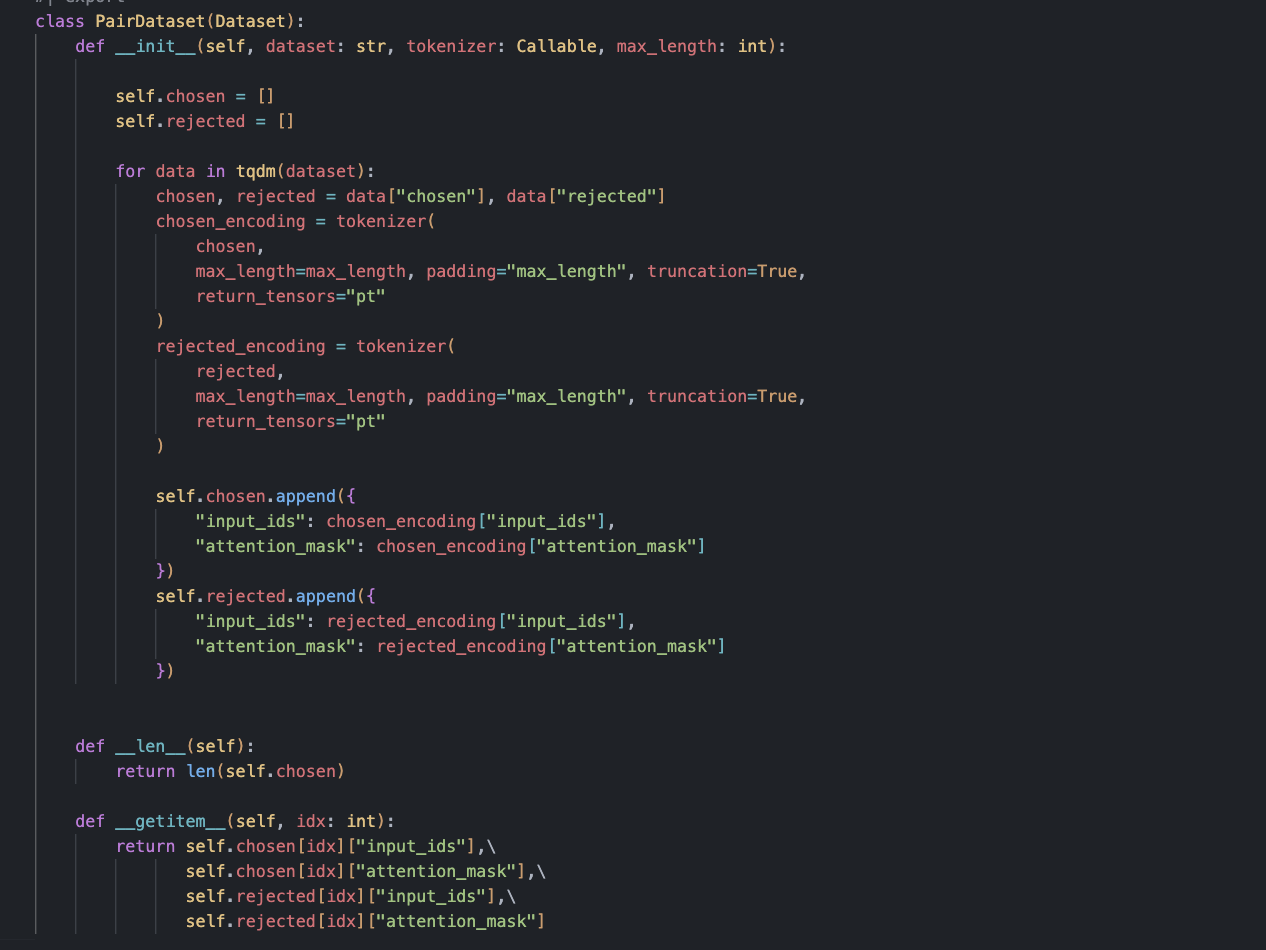
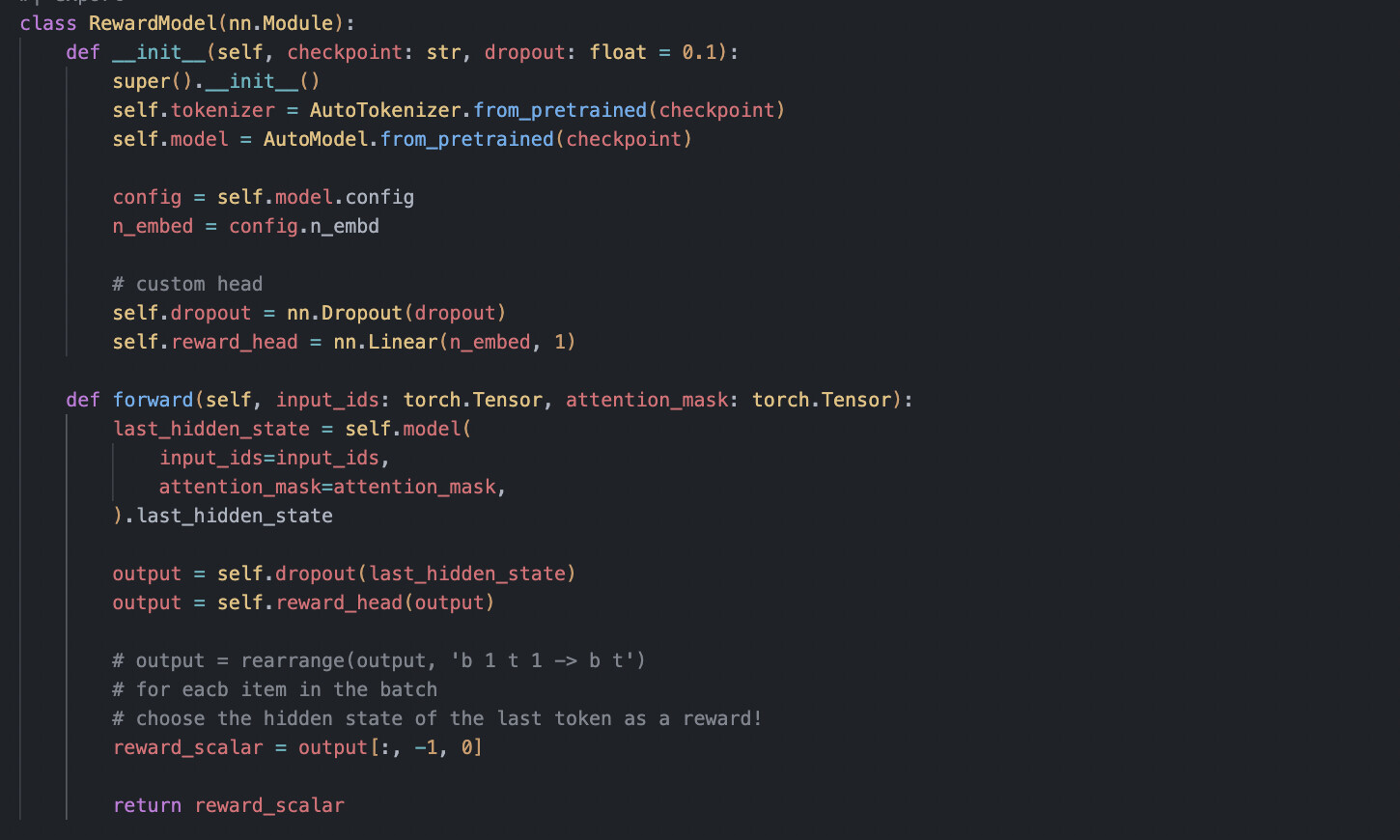
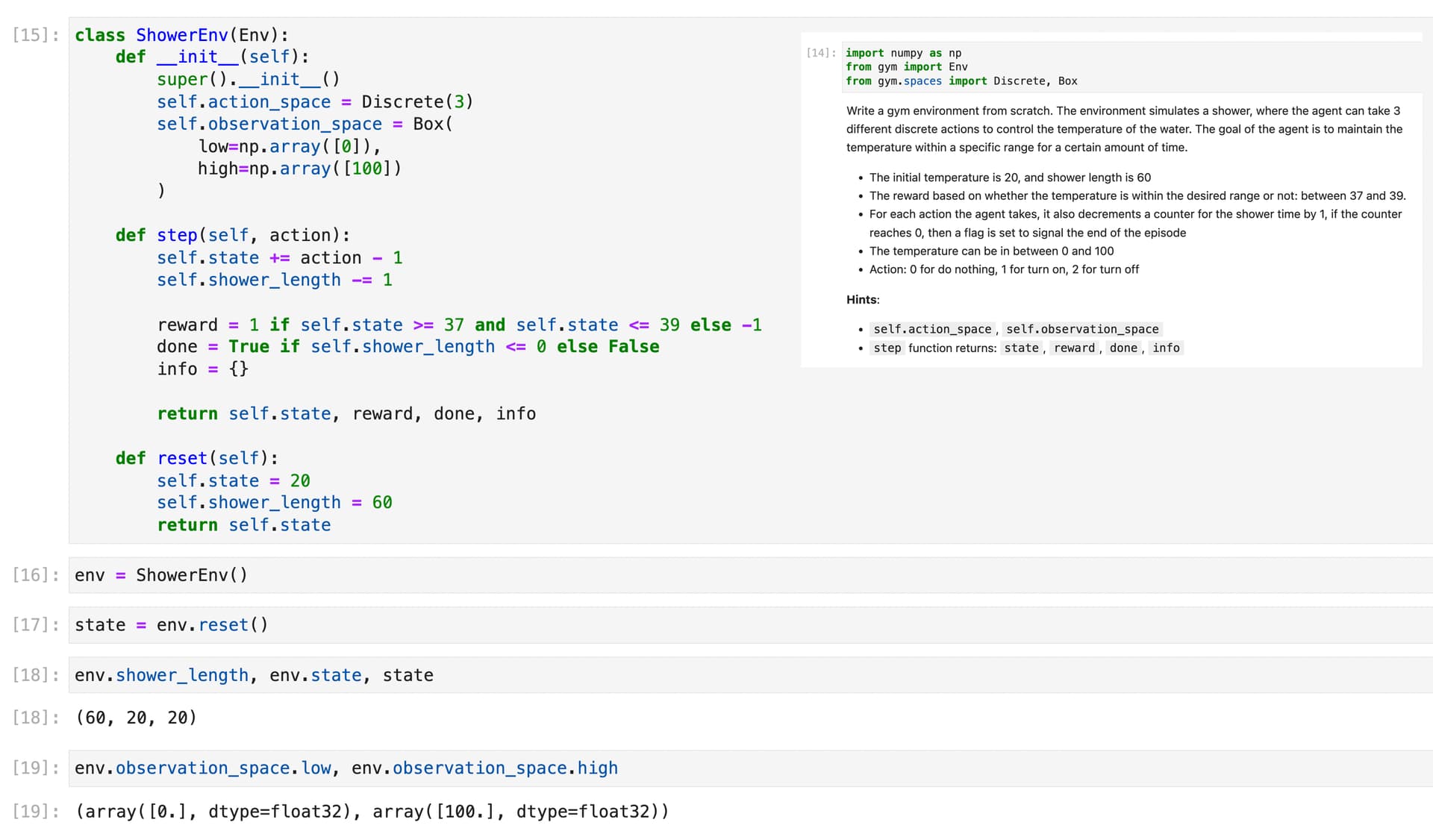
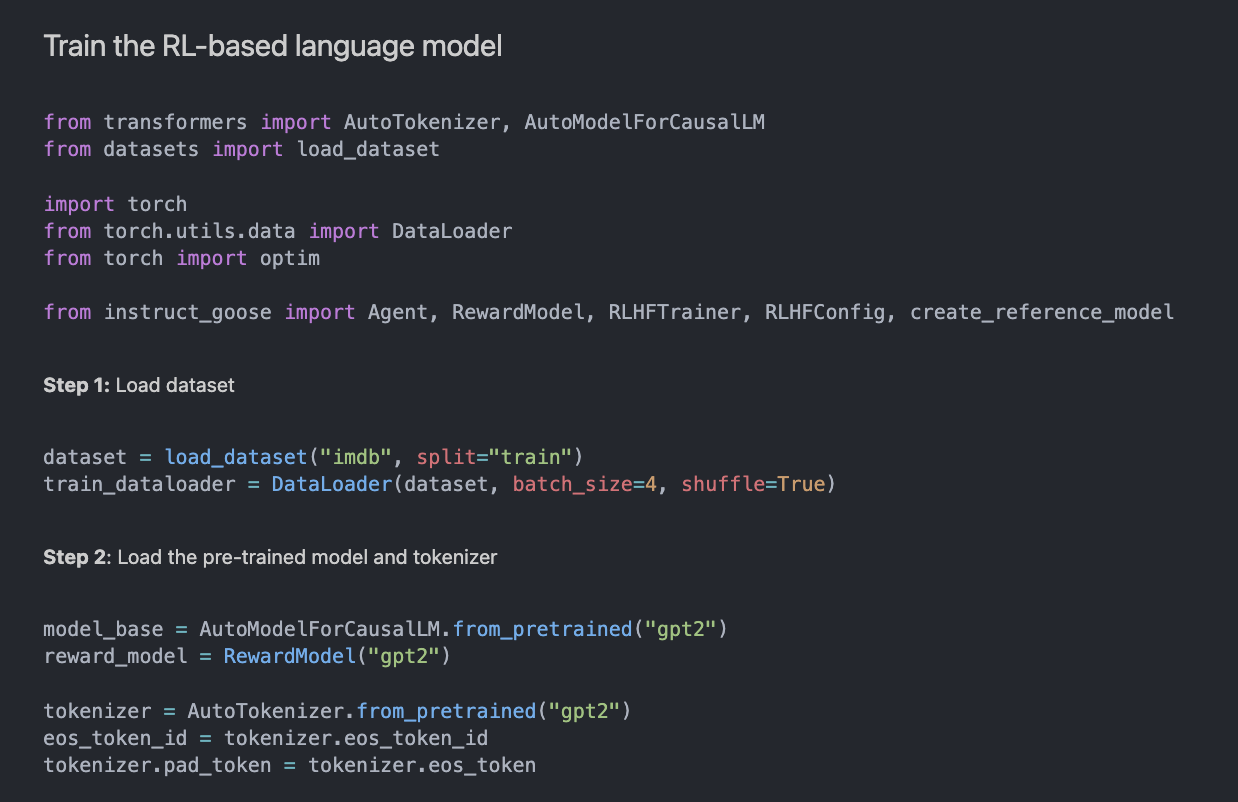
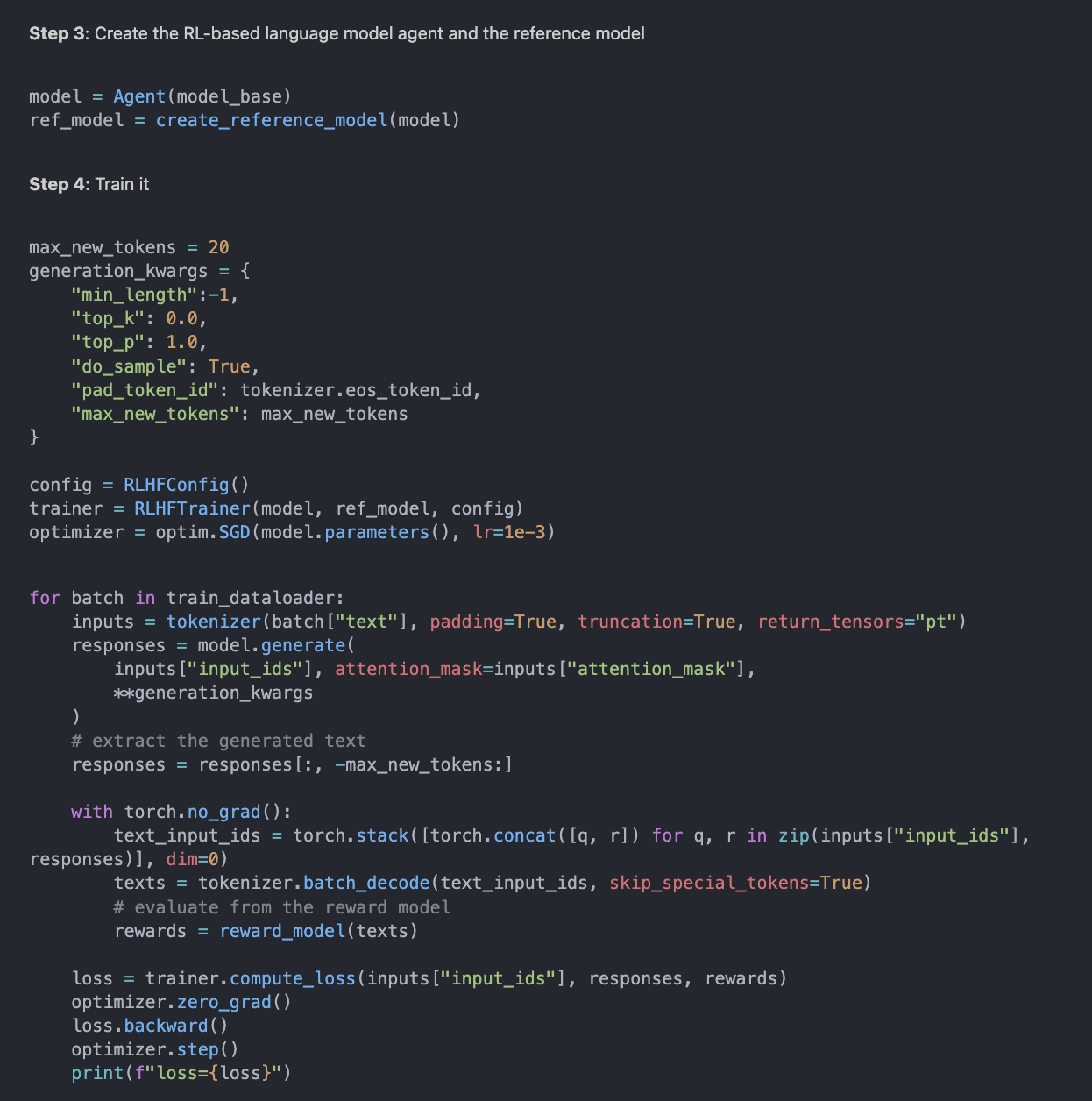
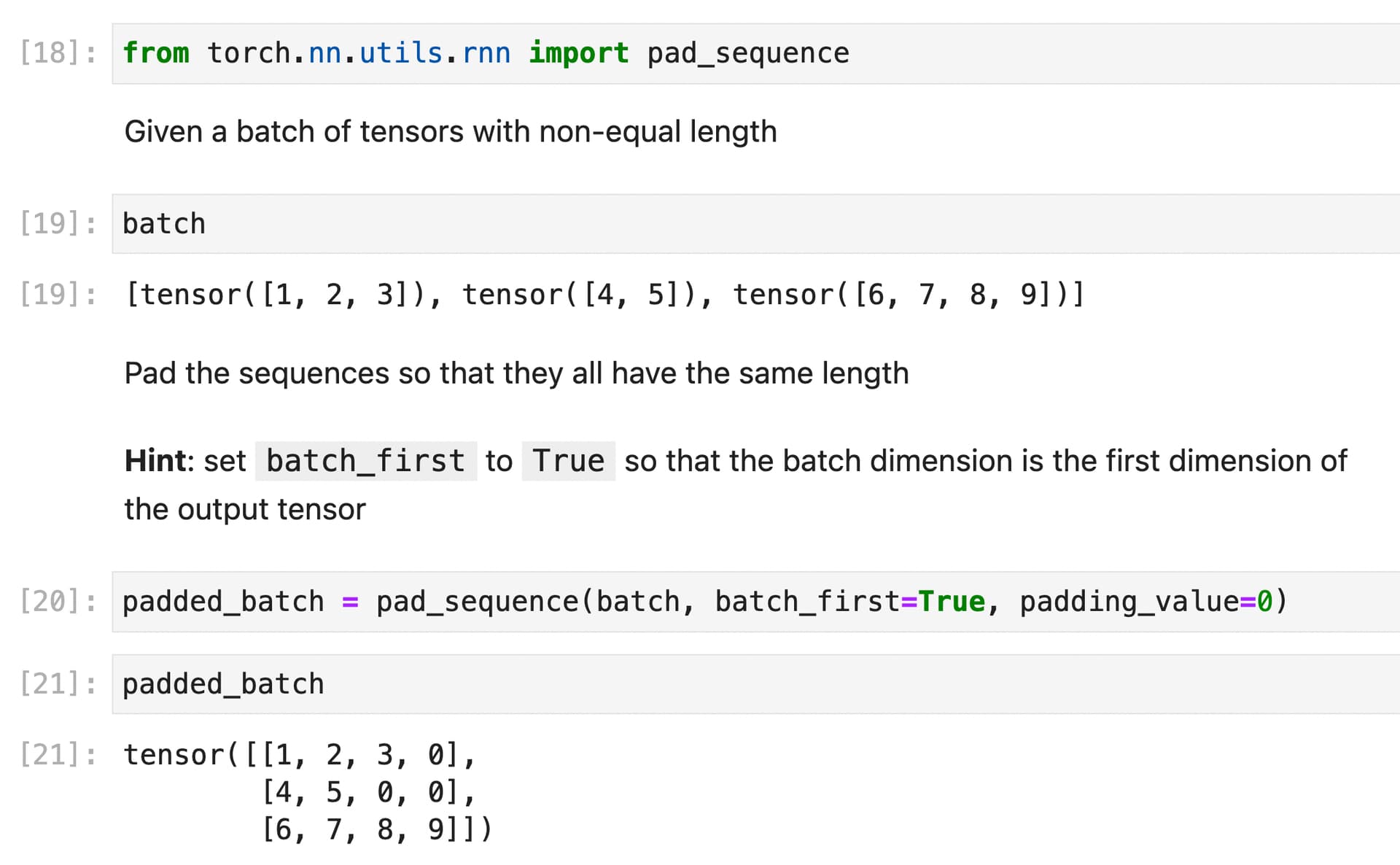
I am currently learning about deep reinforcement learning, which builds upon the foundations of deep learning. I think that understanding deep reinforcement learning can be especially helpful for those who already have a foundation in deep learning.
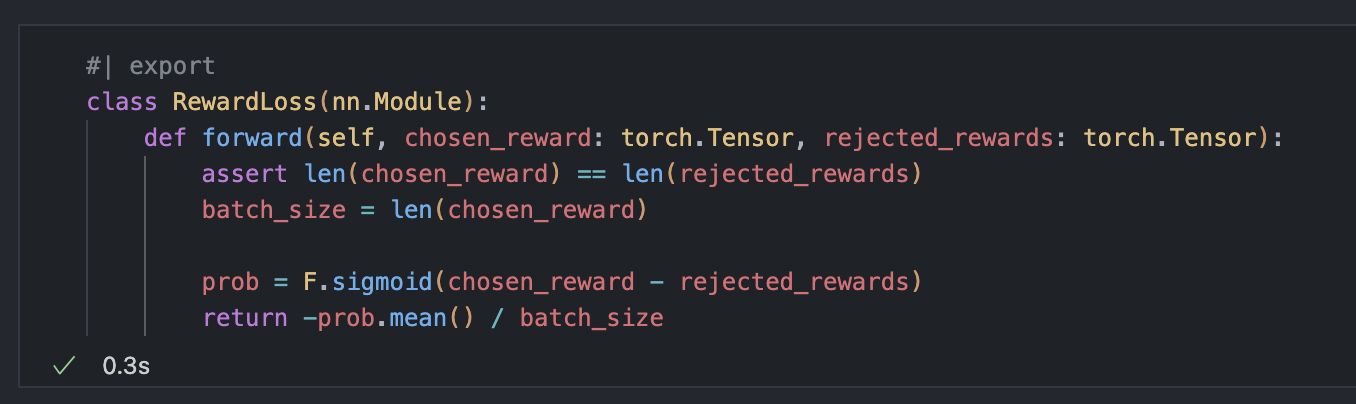
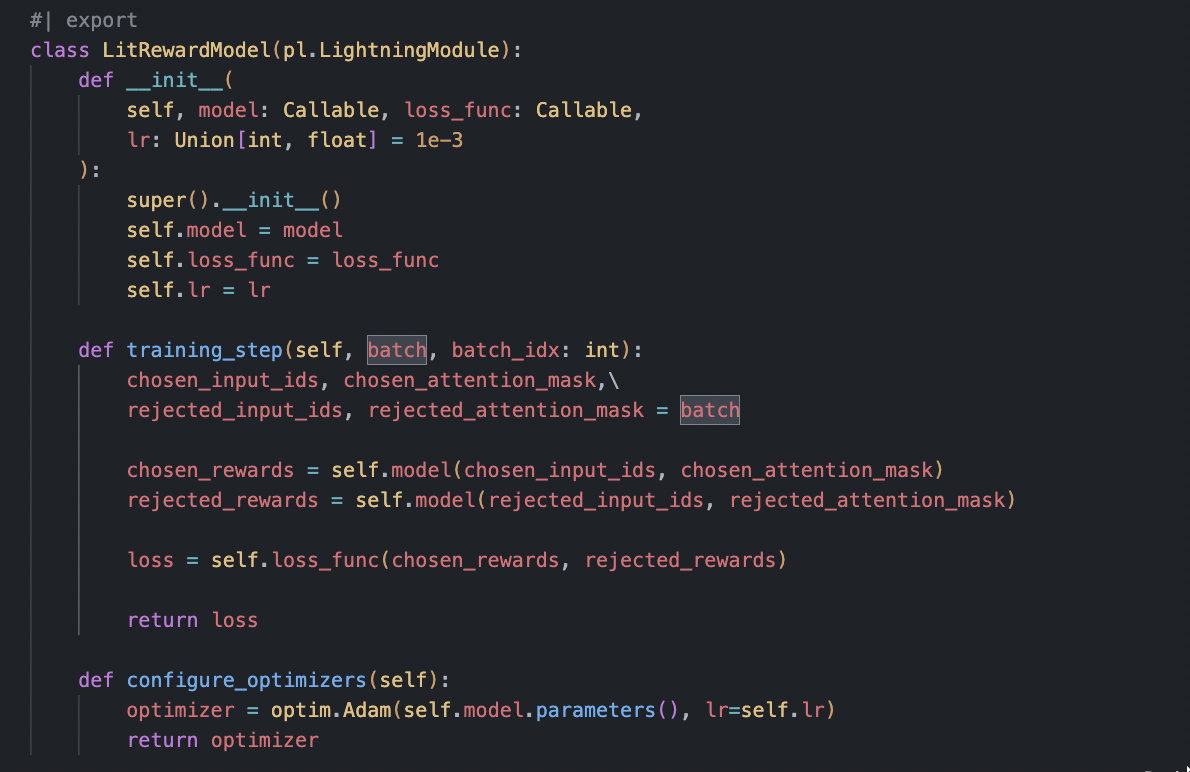
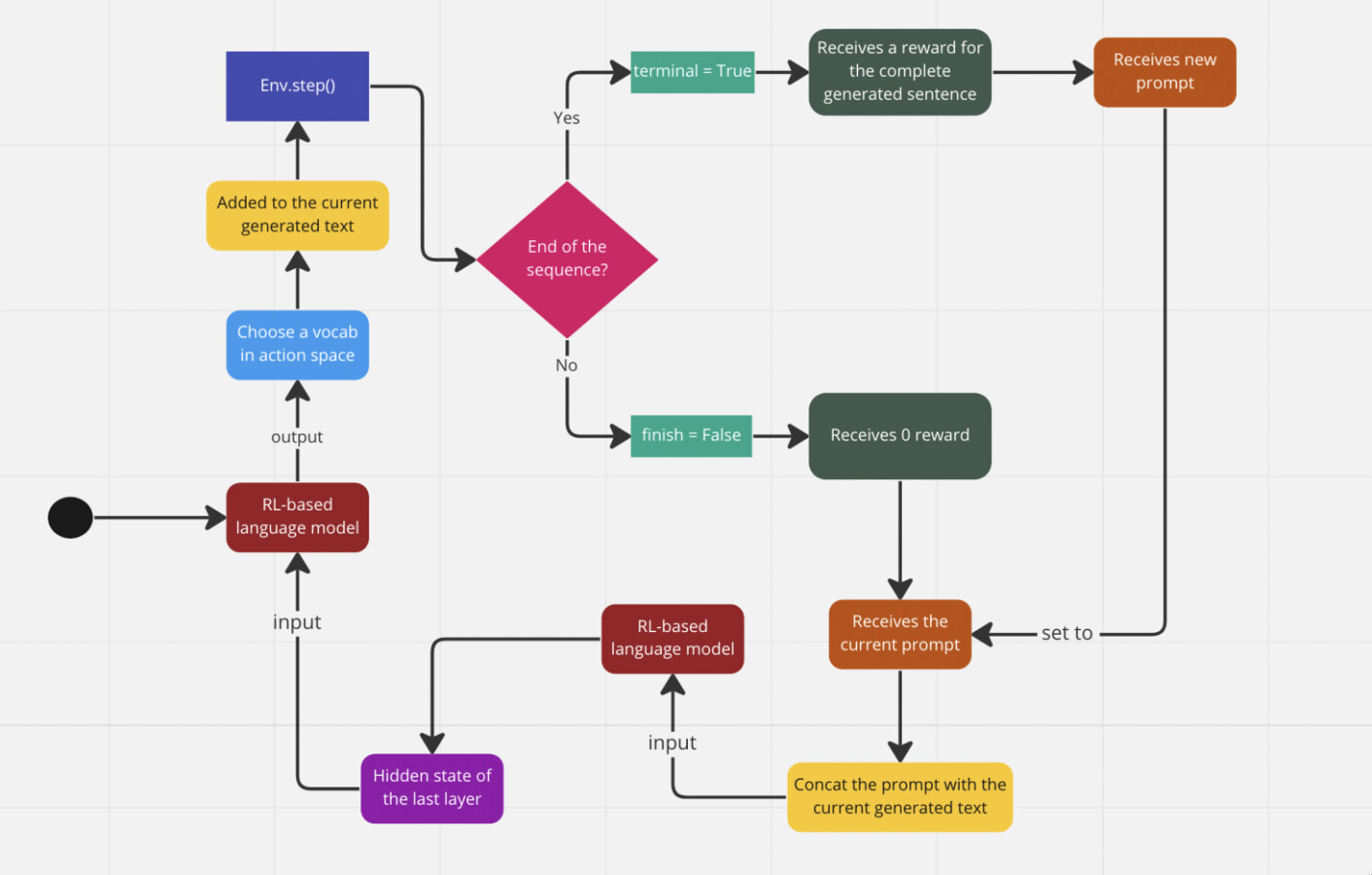
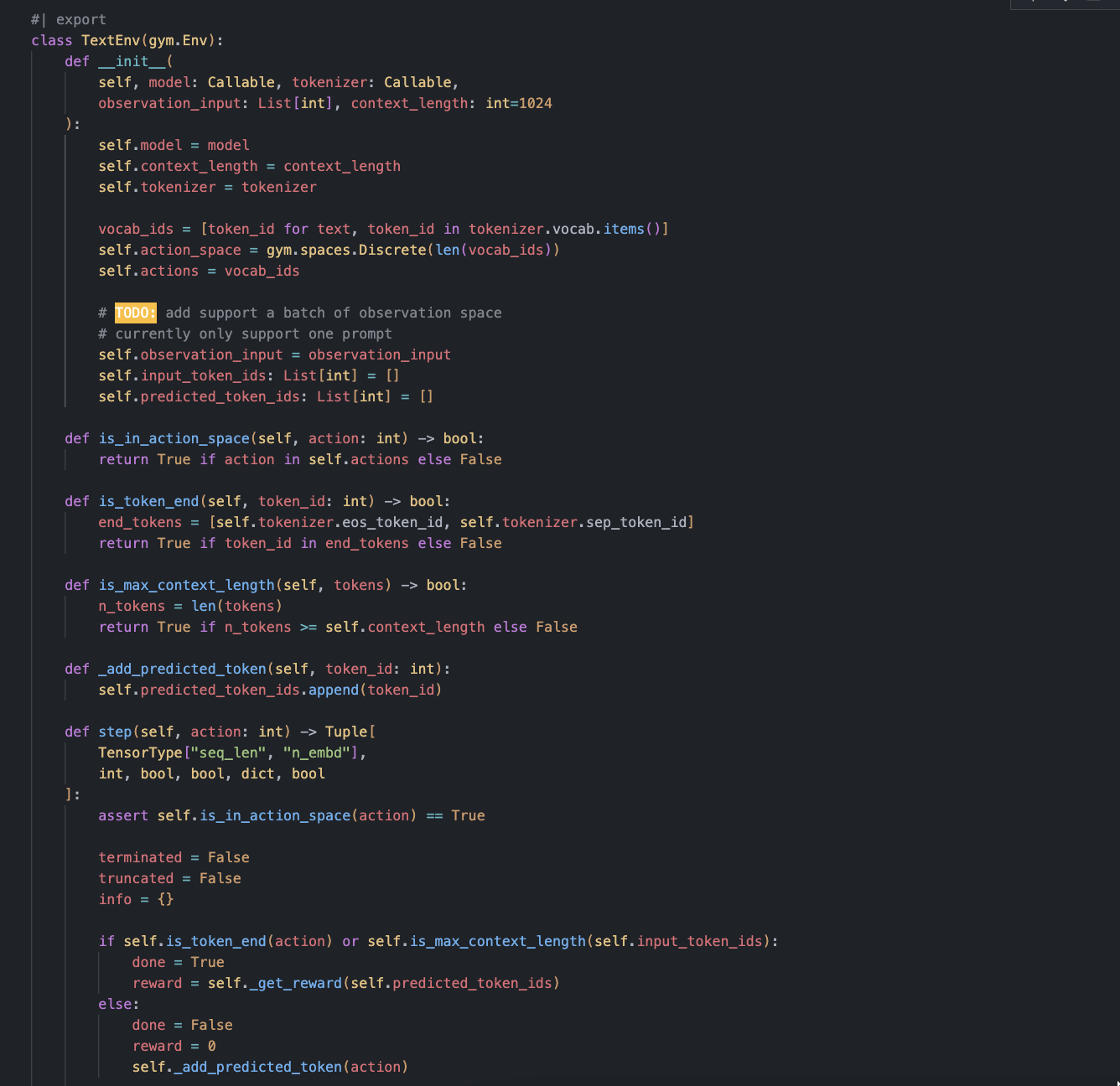
I am currently learning about reinforcement learning and implementing MuZero and RLHF (a technique used to train ChatGPT) from scratch. I would like to share my learning progress here.
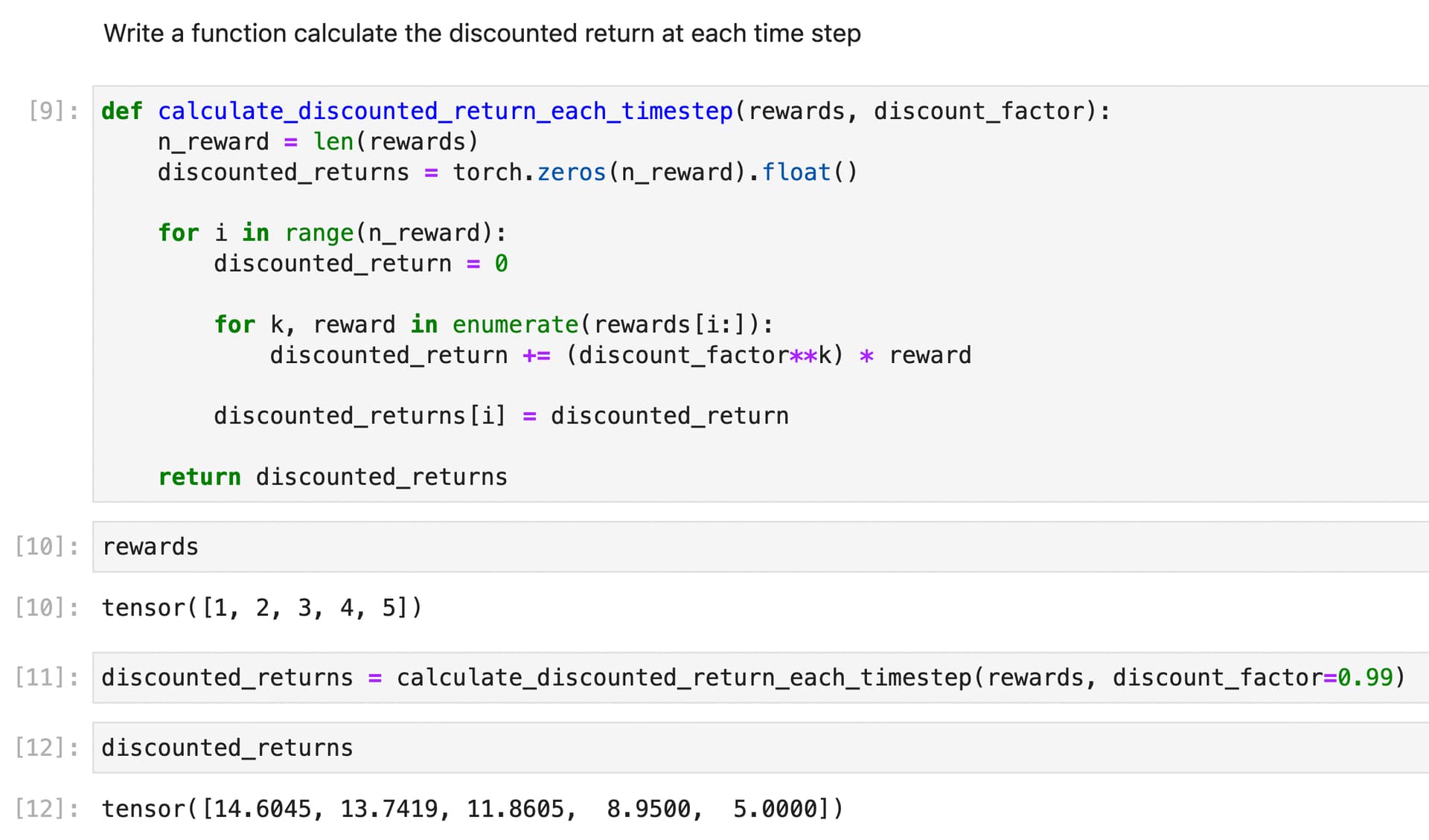
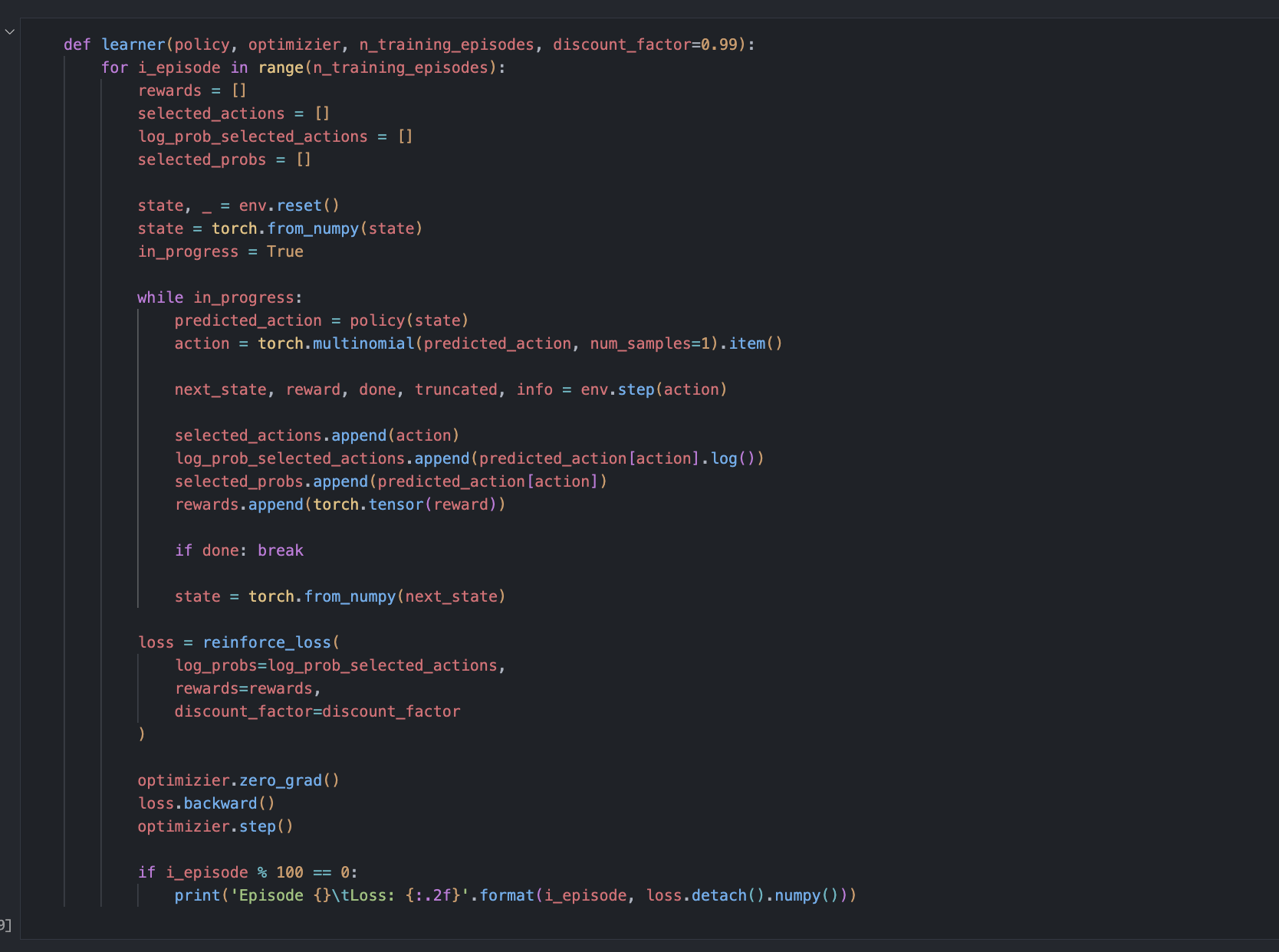
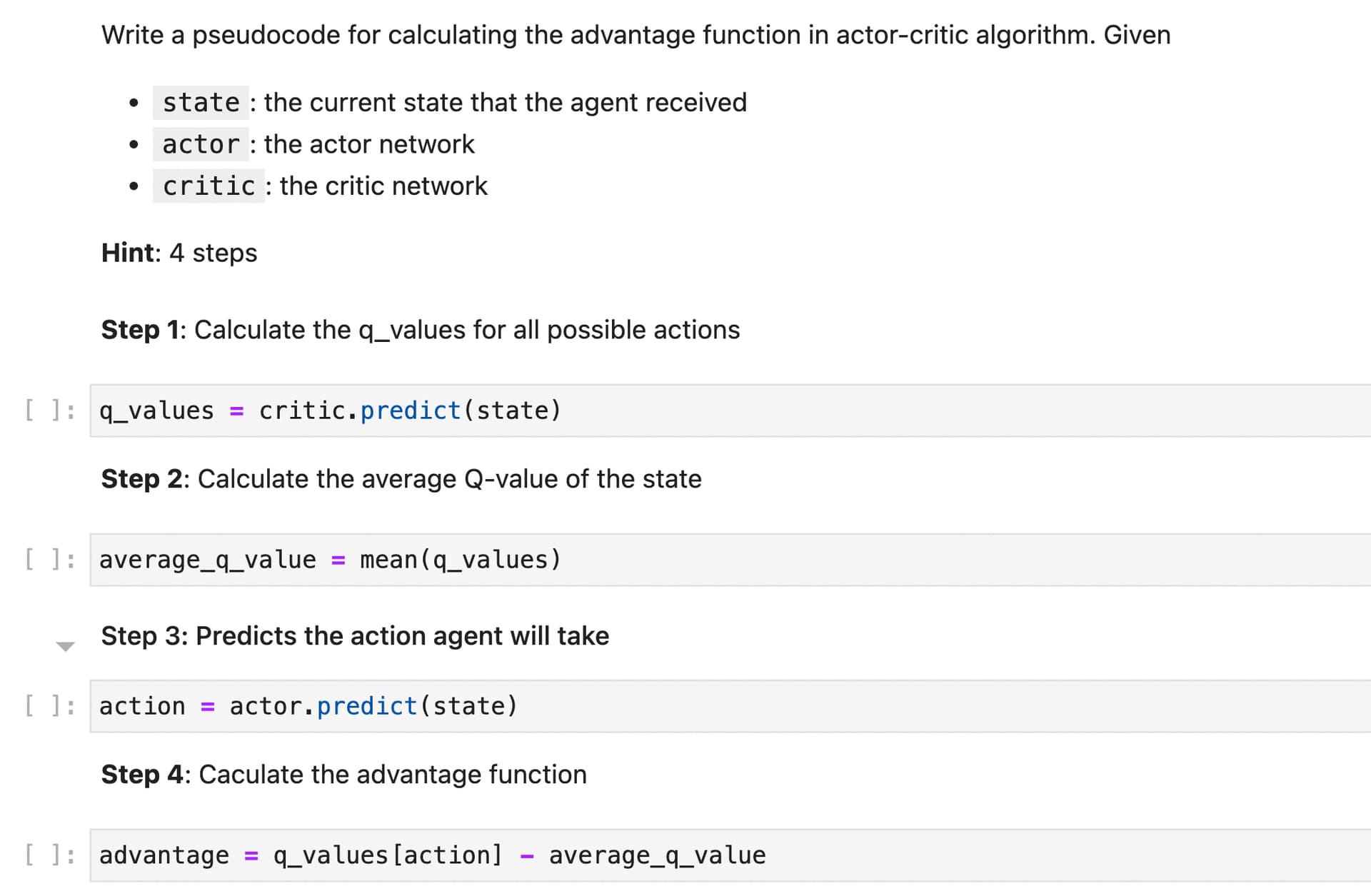
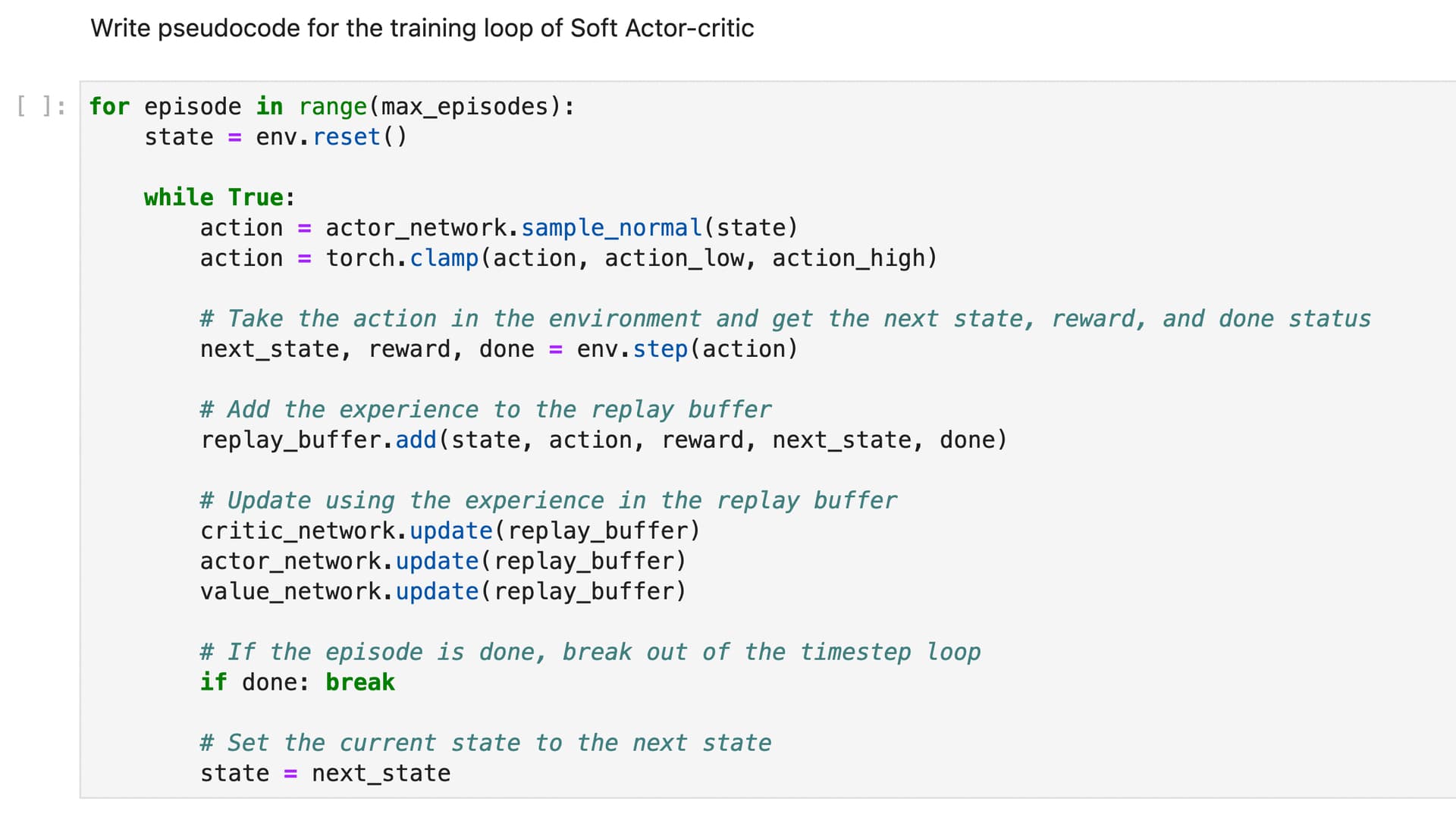
TIL: Fixed my reinforce algorithm training loop (previously i got the loss function wrong), understand how advantage function works in actor-critic (will implement from scratch very soon)
the last two day i learned: the idea of MuZero, some basic of PPO, and how MCTS works (I will post my notes on the last two topics once I finish going through them)
the last five days i learned: how RLHF works and implemented a vanilla representation network in MuZero (will fix it when all the components are put together)