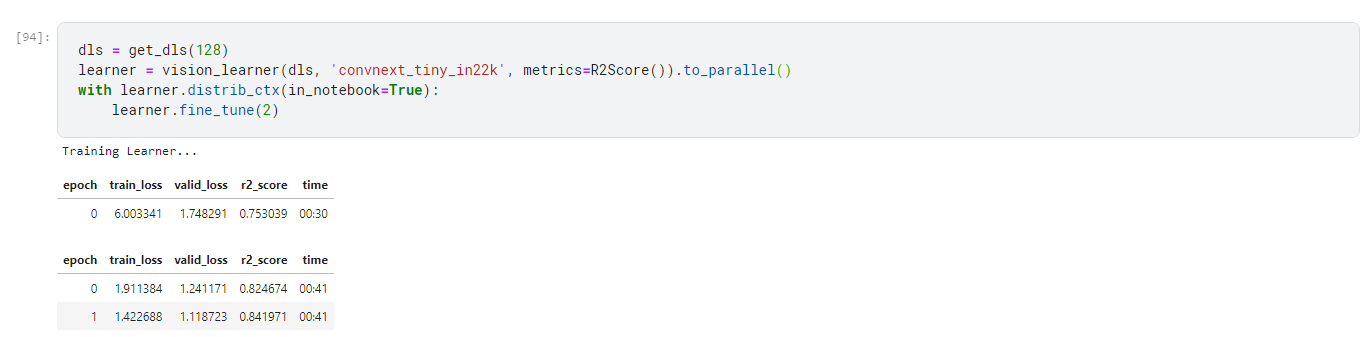
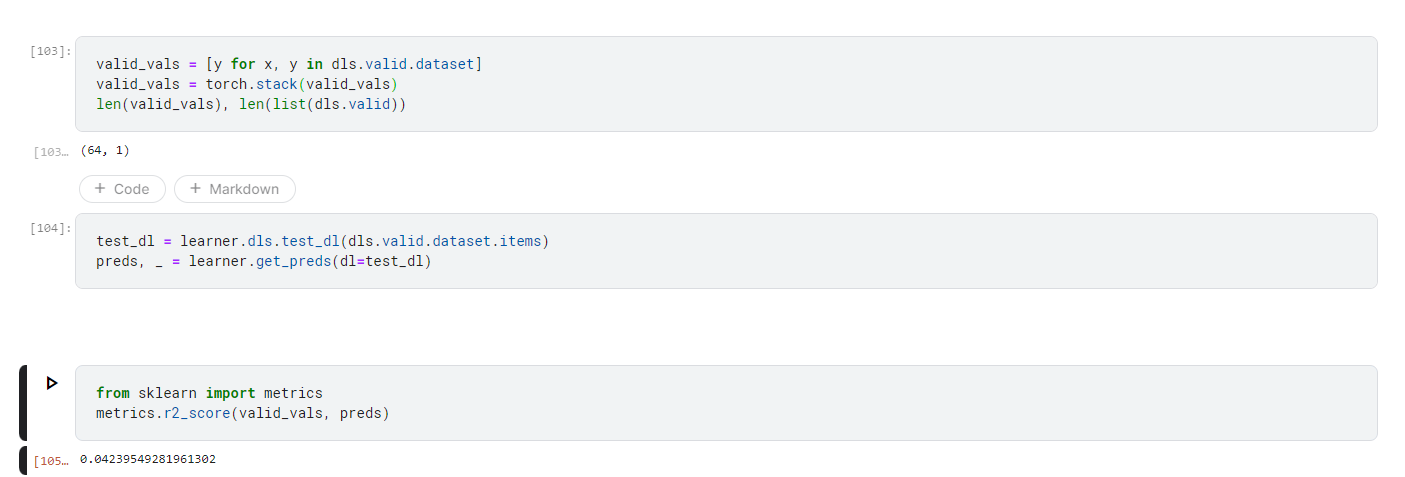
I’m training an image regression model and evaluating it using an r2 score. I noticed that the r2 score on the validation set was much higher than the r2 score on the test set, so I wanted to see if I could duplicate the metric result on the validation set. However, when I make predictions on the validation set using learn.get_preds, the r2 score is wildly different than the one being output by the recorder.
The validation set is a single batch of 64 images. As you can see the recorder output is 0.841, but the sklearn r2 score output is 0.042. Since I’m only using a single batch, why aren’t they the same?
Are you able to share your code in a Kaggle/Colab notebook?
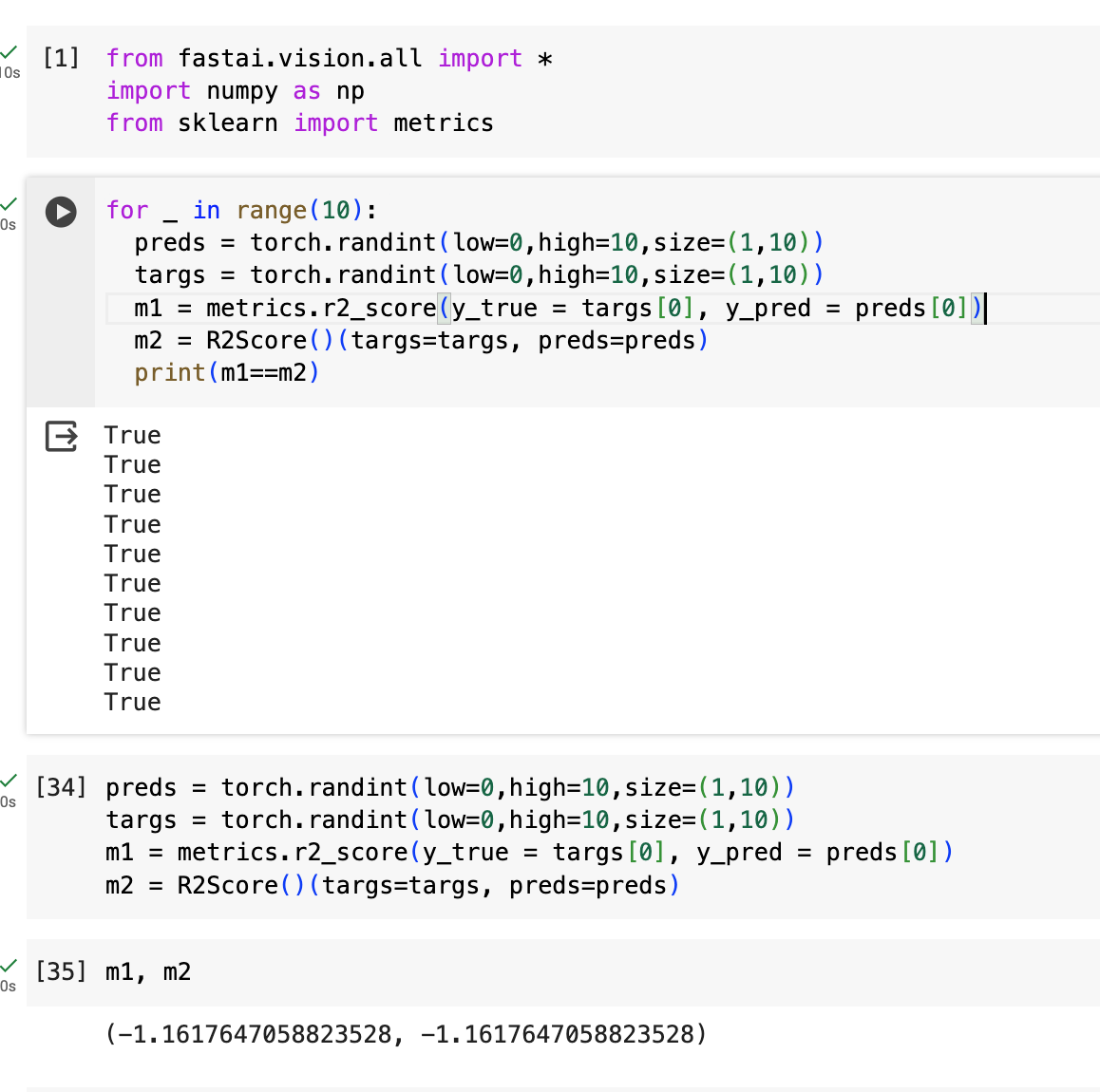
It looks like sklearn.r2_score and fastai’s R2Score() give the same result if they are given the same predictions and targets (note that I have to pass preds[0] and targs[0] to r2_score otherwise it doesn’t compute correctly):
Thanks for the thorough answer! Yeah that’s what makes things really confusing. If the scores work the same then I’m definitely misunderstanding how the metric is calculated. I know it’s averaged over batches, which is why I only used one batch, but the scores are still very different. All the images are center-cropped during validation and inference, so I don’t think it’s a transformation issue either. It’s been a real head-scratcher for me.
Here’s the notebook:
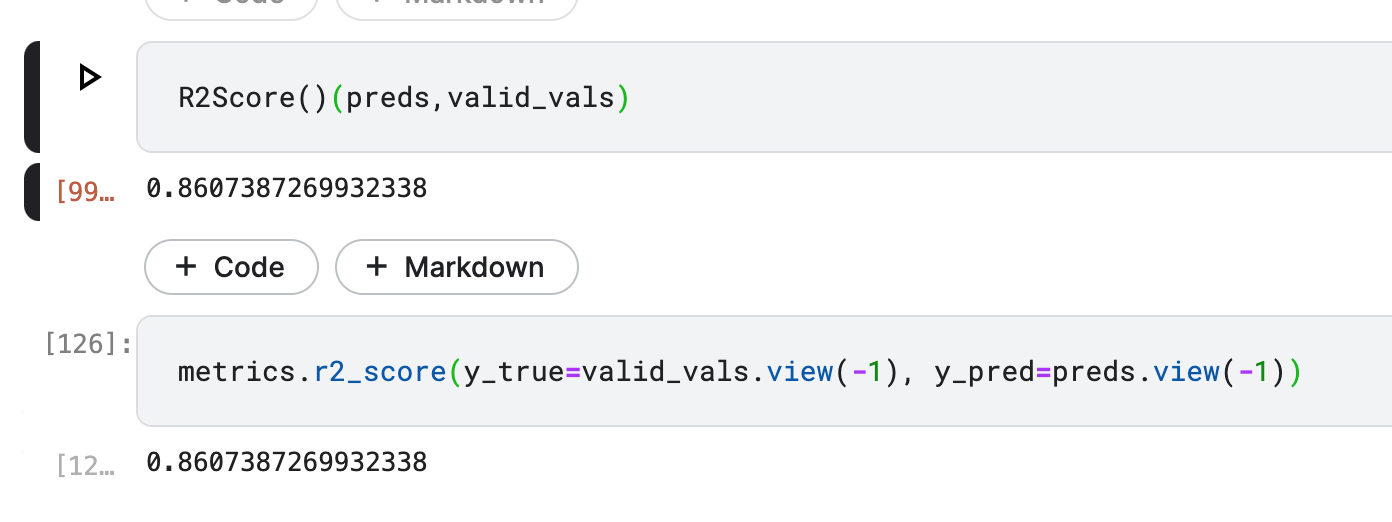
Okay I think I figured out at least how to make them equal—if you follow the source code for R2Score you’ll eventually come across this line where fastai flattens the targets and the predictions.
If you flatten valid_vals and preds (using .view(-1)) and then pass them to metrics.r2_score, you get the same value as R2Score:
So I think one way to summarize this is that fastai’s implementation of R2Score is looking at the metric across the entire batch (lumping together all 6 predicted variables) whereas sklearn’s implementation is looking at the metric for each of the 6 variables in the batch and then taking the mean across those 6 R^2 values by default.