I see the learner has 2 predict functions. predict_with_targs & predict. What is the difference between the two?
Follow up question while I was trying to understand that myself opening the learner.py: Is this function recursively calling itself? I know it should be calling the model.py’s predict function at the end.
def predict(self, is_test=False, use_swa=False):
dl = self.data.test_dl if is_test else self.data.val_dl
m = self.swa_model if use_swa else self.model
return predict(m, dl)
It’s not recursively calling itself, because in Python to refer to the method you’d need to use self.predict. (I know in other languages like Java that’s not the case, which is probably the source of the confusion). Instead it’s using the function predict that came from the imports.
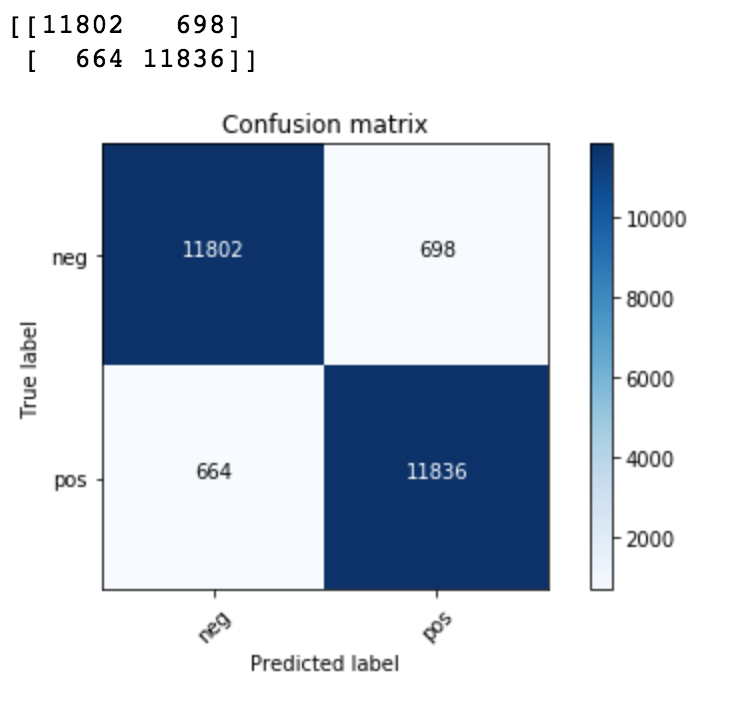
predict gives you only the predictions. predict_with_targs gives you both predictions and true Labels. That you can then use to measure Accuracy or feed to confusion matrix. Otherwise the code is the same -