Hi there!
I’m working on satellite imagery in a Kaggle kernel, using primarily sample code from the class. I am training a segmentation learner, and can reach about 80% accuracy (DICE) after a few minutes. However, when I try to swap the data out for the same images, but in 2x resolution, seg_learn.load('stage-2') fails to load! In particular, it complains as follows:
RuntimeError: Error(s) in loading state_dict for DynamicUnet: Missing key(s) in state_dict: "layers.10.layers.0.0.weight", "layers.10.layers.0.0.bias", "layers.10.layers.1.0.weight", "layers.10.layers.1.0.bias", "layers.11.0.weight", "layers.11.0.bias". Unexpected key(s) in state_dict: "layers.12.0.weight", "layers.12.0.bias", "layers.11.layers.0.0.weight", "layers.11.layers.0.0.bias", "layers.11.layers.1.0.weight", "layers.11.layers.1.0.bias".
To my untrained eye, it seems like the save has failed to prepare the file in a way that the loader expects. Am I doing something wrong? Have you seen this before? Can you help me get past this blocker?
I was having the exact same problem (just on layers.5 instead of on layers.10) loading an old model. After a bit of trial and error, I realized that I’ve enabled self-attention recently. Once disabled, the old model loaded correctly.
Hi Sebastian,
I went back and the old notebook runs without error now, so I must have solved it somehow. I do not see any reference to seld_attention, so I don’t think Avio’s solution was my salvation.
Instead, what I see in my code is:
Strange, I’m rebuilding my model too, but it still fails, the difference is that I’m using resnet18. But thanks a lot for the rapid response, I’ll continue testing
Updage: I tested with resnet34 and I’m still getting the error. I don’t know if the fastai version google colab runs is different from the one that allows unet to do progressive resizing that way…
The error I’m getting is:
/usr/local/lib/python3.6/dist-packages/fastai/basic_train.py in load(self, file, device, strict, with_opt, purge, remove_module)
271 model_state = state['model']
272 if remove_module: model_state = remove_module_load(model_state)
--> 273 get_model(self.model).load_state_dict(model_state, strict=strict)
274 if ifnone(with_opt,True):
275 if not hasattr(self, 'opt'): self.create_opt(defaults.lr, self.wd)
/usr/local/lib/python3.6/dist-packages/torch/nn/modules/module.py in load_state_dict(self, state_dict, strict)
828 if len(error_msgs) > 0:
829 raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
--> 830 self.__class__.__name__, "\n\t".join(error_msgs)))
831 return _IncompatibleKeys(missing_keys, unexpected_keys)
832
RuntimeError: Error(s) in loading state_dict for DynamicUnet:
Missing key(s) in state_dict: "layers.11.layers.0.0.weight", "layers.11.layers.0.0.bias", "layers.11.layers.1.0.weight", "layers.11.layers.1.0.bias", "layers.12.0.weight", "layers.12.0.bias".
Unexpected key(s) in state_dict: "layers.10.layers.0.0.weight", "layers.10.layers.0.0.bias", "layers.10.layers.1.0.weight", "layers.10.layers.1.0.bias", "layers.11.0.weight", "layers.11.0.bias".
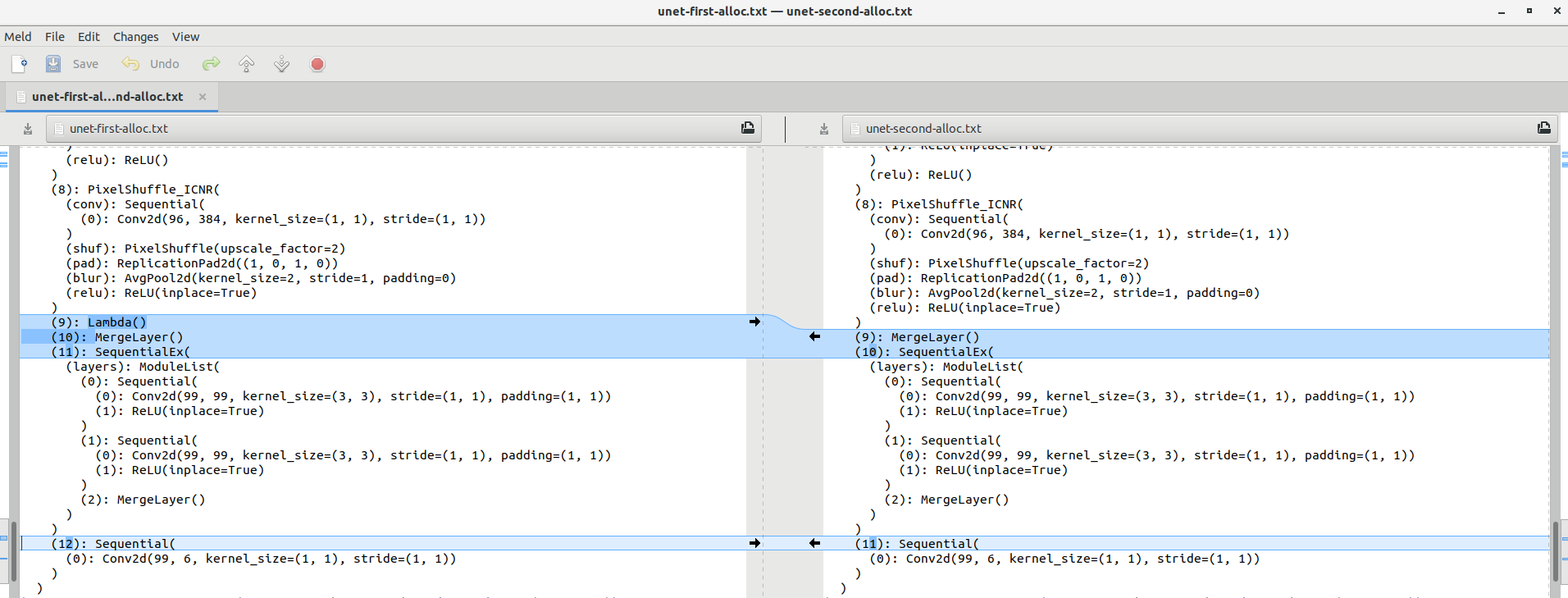
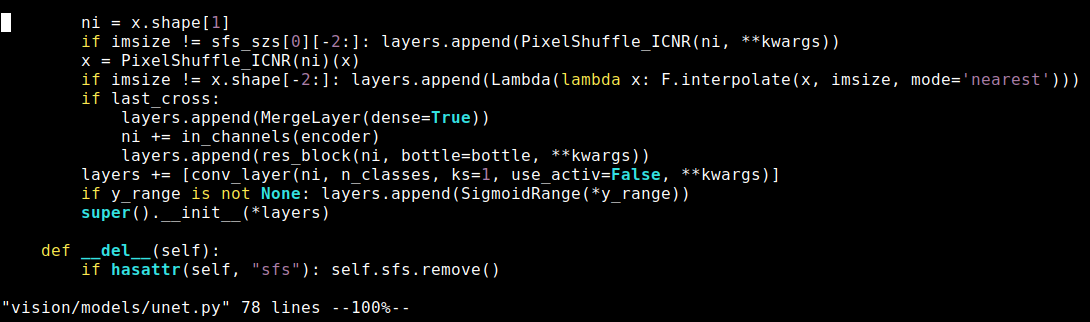
This line in the DynamicUnet class changes the structure of the network according to the image size provided. But I can’t understand why…
if imsize != x.shape[-2:]: layers.append(Lambda(lambda x: F.interpolate(x, imsize, mode=‘nearest’)))
EDIT2:
I’ve restarted the notebook and now the DynamicUnet constructor creates the lambda() layer also in the first U-Net allocation with the smallest image size (51, 100). So strange…
I didn’t dig in to the code like you did (and I should have done that), but figured out that the problem was with the image sizes too. I discover that if the sizes used to initialize the Databunch where odd numbers, I always got that error, but using images with 2^n sizes always worked, didn’t tried with even numbers because I resized the images from 128, to 256 and to 512, but probably if all the image size are even numbers you will stop getting those errors.
Yep, that’s seems the explanation, but it’s not deterministic. Now I’m getting the opposite, the first U-Net is created with the lambda layer, the second one doesn’t get it. Same code, same image sizes.
EDIT:
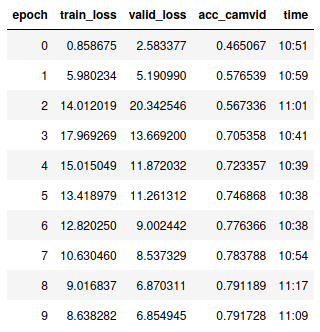
The other super weird thing is that with the lambda layer I get these losses:
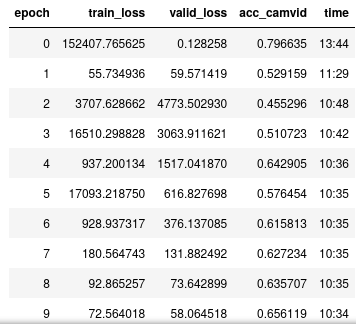
Without the lambda layer I was getting these losses:
So it looks that, without the lambda layer, the network behaves… weirdly…