@jeremy
I thought transformation would be done on the validation on the fly, no? I thought (or at least it looks like) learn.TTA(…) is done on the testing set at the very end, to produce the inferences on the unknown set.
Reason I ask is that it seems like it would be better to do TTA on the fly on the validation, to get a better measure of model quality.
I don’t know the answer for sure, but I’d suspect that the error on TTA validation and validation should be highly correlated, and there’s a cost. You’re running your validation 5x more frequently with TTA on top of any costs to do data augmentation.
My guess is that the slight benefits of a better measure of model quality don’t outweigh those costs because the main use of validation loss is to ensure we’re not over or underfitting. I’m guessing the situations are few and far between where TTA validation would cause you to make a different decision about when to stop training the model.
Actually we use learn.TTA both on validation set and on test set when running predictions. The only difference is that we pass it an argument is_test=True when we are using it on the test set.
As far as the regular data augmentation/transformations, those are done on the fly during training but are only applied to the training set I believe. The difference with tfms and TTA is that with TTA we are predicting on augmented images and then taking the average of those predictions (either predicting on validation set or test set). With valid set we can see in the notebook that we usually get a bump in accuracy, with the test set we don’t know how it improves accuracy unless we submit it to Kaggle or something like that.
I’m here after searching for conversation about TTA, this looks like a good one!
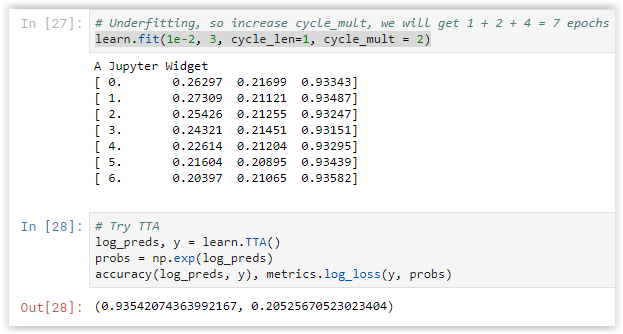
So far I have found that TTA has not increased my accuracy, the results are typically not much better or even a little worse than my last epoch (see snapshot - validation error rate is better but accuracy is worse). So, apart from getting in idea of whether or not I am overfitting I don’t yet have any condidence in using it.
But the use of it confuses me - sorry about the number of questions!
I thought that having augmented images would be useful during the training of the network - like giving it more data to train with, but we only use the augmented data for testing accuracy - why is that?
Could you use the augmented images to train with, if so, how - if they are only made available via a call to TTA.
Is TTA the only way we can prepare data for submission to kaggle? And how is that done anyway - I tried test=True as a parameter and I got a message from one of the accuracy calls to “Please provide the true labels explicitly through the labels argument” - not sure what that means!
If TTA is the only way to prepare data for kaggle, how can we avoid actually processing augmented images - do we just set val_idxs = [0] before running through it?
When you ask your model to make a prediction on an unseen image, it basically looks at that image. It can be helpful to make it look at slightly transformed versions of the same image, since, in doing so, you lower the probability that your model can get confused.
TTA makes predictions over a group of transformed versions of the same image, then averages them, and present this average as its answer.
All I just said is my understanding and could very weel be wrong.
Training time augmentation is a different thing. Read the whole lesson1 nb.
No. It is up to you how you prepare your data for submission, as long as you follow their guidelines.