I’ve trained this for 1 epoch, and now the learn.sched.plot() graph doesn’t seem that useful:
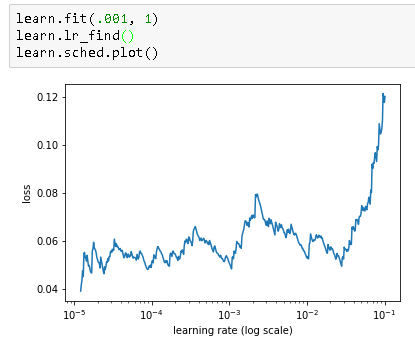
I’ve trained this for 1 epoch, and now the learn.sched.plot() graph doesn’t seem that useful:
It is not useful because after training for 1 epoch you have already started to learn the proper parameters for the model.
The expectation for calling this function is that you have merely initialized the parameters and not already started doing any sort of training/gradient descent to learn proper weights. The idea is that first you call this function to identify the optimal learning rate and second you start training with that learning rate.
Note that there are lots of other techniques for changing the learning rate over time (ie. learning rate decay, cyclical learning rates, etc.). This is just a reliable way to pick a pretty solid learning rate to start with.
By doing operation (shown below) from lesson1 notebook, I wonder aren’t we destroying pre-trained weights?
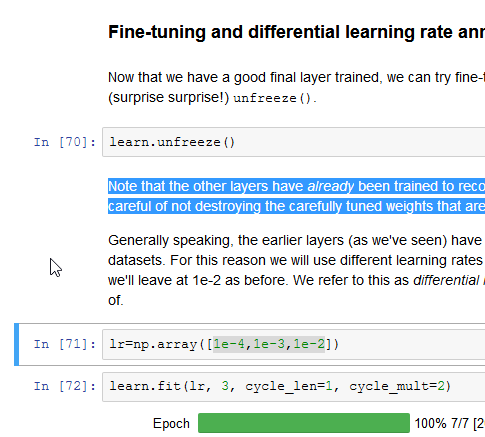
Not if we’re careful… Using a lower learning rate for the earlier layers means that they train slower. But if we do too many epochs, we will may eventually overfit.
Actually, I think calling “learn.lr_find()” muliple times may be of value when training many layers (which would take longer). I was only training the top layer so far, so it was pretty much ‘fully trained’ after 1 epoch!
Ah I see, thanks!
Wouldn’t it be better to do L1 or L2 regularization toward the pre-trained values (rather than just early stopping via a slow training rate)?
Great suggestion - there’s a recent paper called (something like) “lifelong learning” that tries exactly that, and it works really well!
Man - I had that idea a long time ago!
@wbrucek would you suggest where to read about it?
I don’t know - the pre-trained weights just seemed like reasonable prior value to regularize toward.
OK found the paper - I totally misremembered the title! http://arxiv.org/abs/1612.00796