Hi,
following lesson 1 part 1, dogs and cats, and wondering what reason that
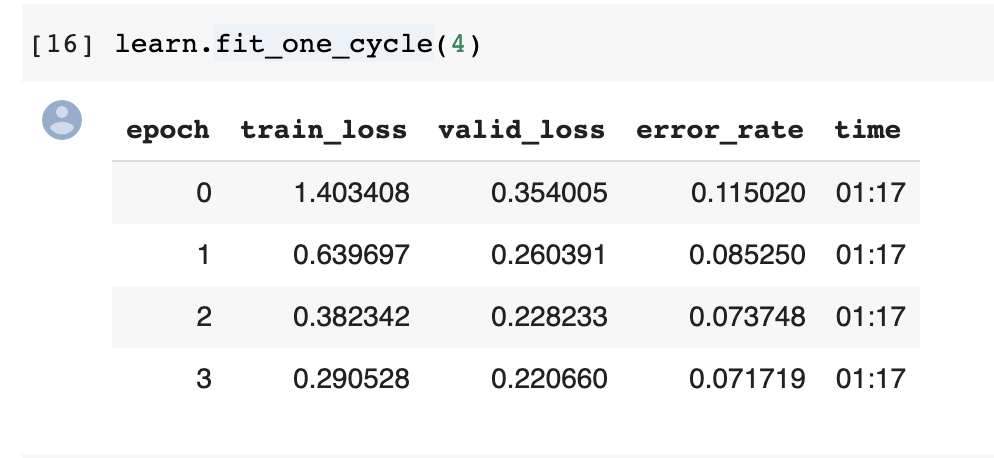
the learn.fit_one_cycle(4) line takes so long? Using a TPU and just executing the cells in the notebook. Could someone point me in the right direction please?
Fastai (and pytorch) are not compatible with TPUs… The program is instead using the CPU and that is why it is so slow
3 Likes
Thanks for that, it is most useful:)
Btw, would you know why fastai is incompatible, and is that a good or bad thing?
Nothing bad, nobody has gotten around to making TPUs compatible with PyTorch… TPUs are still a relatively new piece of hardware developed by Google… And since Google also develops TensorFlow, Google has made Tensorflow compatible with TPUs… So if you want to use TPUs for immense speedups (though it probably won’t have much advantage for toy problems like dogs vs cats) you will have to use TensorFlow directly. You could also use Keras which is similar to fastai in that it is a wrapper for TensorFlow just like fastai is a wrapper for PyTorch, and is also quite simple to learn/play around with.
I bet in 1-2 years someone will make PyTorch compatible with TPUs, which should automatically make fastai compatible…
There is actually TPU support for PyTorch it’s just pretty new and not in the main repo. See https://github.com/pytorch/xla. I haven’t tried it but you might be able to follow those instructions in Colab, nothing jumps out as impossible, though compilation output in a notebook won’t be too pretty. Issues would be around how they allow access to TPUs under Colab (which I think should be fine) or perhaps due to the need to use Clang 7 for the TPU libraries if they are using different compilers for other parts of the system.
Of course even if it does run there may be issues with TPU compatibility for various PyTorch features. I also don’t know how it will work with any FastAI specific C++ stuff (or how widespread that is).
Biggest thing is that you’d have to go through all the compilation stuff every time you start the notebook (or restart kernel) so it’d just be for playing around not really a usable thing. Though I guess you could compile it and then stick it on your Google Drive so you could just pull down the prebuilt libraries each time.
Tom.
2 Likes
Indeed there is experimental support for PyTorch with TPUs it seems, but I was referring to anything official from PyTorch… Even then, I bet it would be pretty hard to get this to work with fastai
1 Like
Well, that is an official PyTorch repo, just not the main one. But you are certainly correct that integration in fastai is a different thing and I hadn’t properly considered that in my previous reply. It isn’t simply a matter of device='tpu' or anything. From my (very minimal) experience with TPUs in tensorflow and looking at examples, for PyTorch on a TPU you wrap everything up in a TPU specific handler for the whole training loop (which supports CPU fallback but I think not GPU). Something like the fastai Learner but offloading various parts to the TPU (I think beyond just offloading the tensor stuff like with GPUS as the TPU is remote).
So even if you did somehow plug it into fastai you’d likely lose a lot of functionality without significant work across the codebase which is probably not worthwhile. You might be able to add support for fastai data loaders easily enough but callbacks would be another matter so you’d lose all that. You probably don’t often want fastai on a TPU either. You might want to use TPUs to train up a model which can then be used within fastai, which might in general be possible with PyTorch support (any fastai specific tensor stuff aside), but TPUs as a fastai backend seem less useful.
Tom.
1 Like
I’m facing the same issue;
Isn’t there a workaround like manually moving the network and the tensors on the GPU memory rather than the library (fastai) doing it for you?
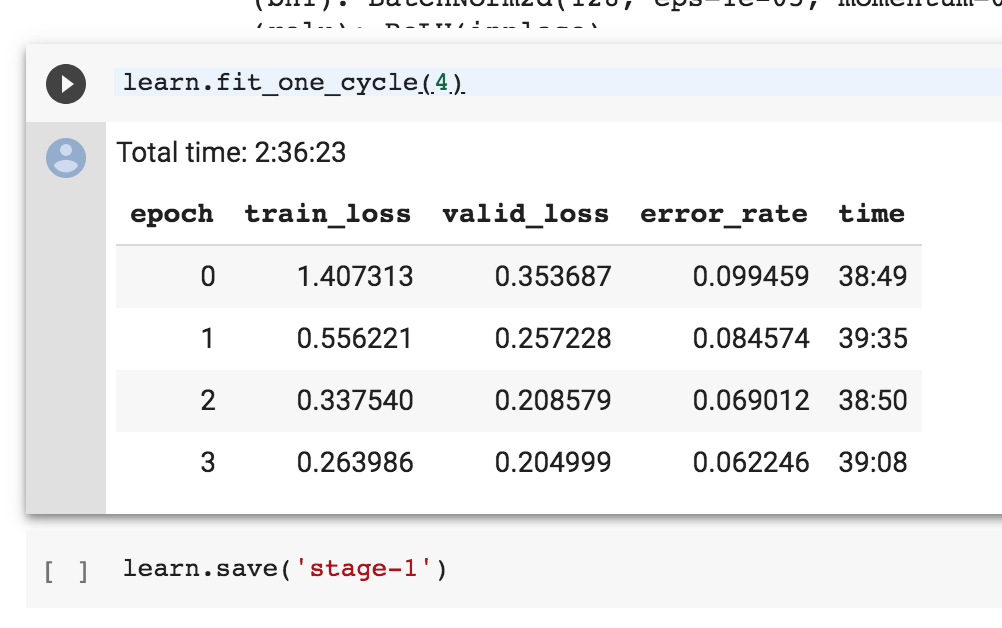
I’ve selected the runtime with a GPU but one epoch still takes 20 mins whereas in the lesson the total time for 4 epochs is around 2.5 mins.
Colab is slower because it’s using a slower GPU (K80) and has lower RAM (~13GB).
Check out this article for a comparison between the speed of different platforms and GPUs https://towardsdatascience.com/maximize-your-gpu-dollars-a9133f4e546a .Colab does take about 20min to run the cat-dog classifier, so your setting seems correct, the slow speed is just the limitation of Colab.
2 Likes
What did you do reduce the time?
I am facing the same exact issue. So, it will really help if you can tell how you overcame this issue.
1 epoch on pets on colab does not take 20 mins, it takes about 1.5
| epoch | train_loss | valid_loss | error_rate | time |
|---|---|---|---|---|
| 0 | 1.375482 | 0.334731 | 0.108254 | 01:35 |
| 1 | 0.637199 | 0.284223 | 0.091340 | 01:30 |
| 2 | 0.369672 | 0.230383 | 0.073748 | 01:31 |
| 3 | 0.259170 | 0.213778 | 0.069689 | 01:34 |
make sure you have GPU switched on in the runtime. NOT TPU, and make sure everything is up to date.
you can do both of these things if you use this as your first notebook cell. if the assert fires, you’ve got either CPU or TPU selected.
!curl -s https://course.fast.ai/setup/colab | bash
import warnings
warnings.filterwarnings('ignore')
import torch; assert torch.cuda.is_available()
Hi joedockrill,
The code that you shared should go in the first cell of the notebook. Is that correct?
I tried that but I got an error; please refer to the attached pic.
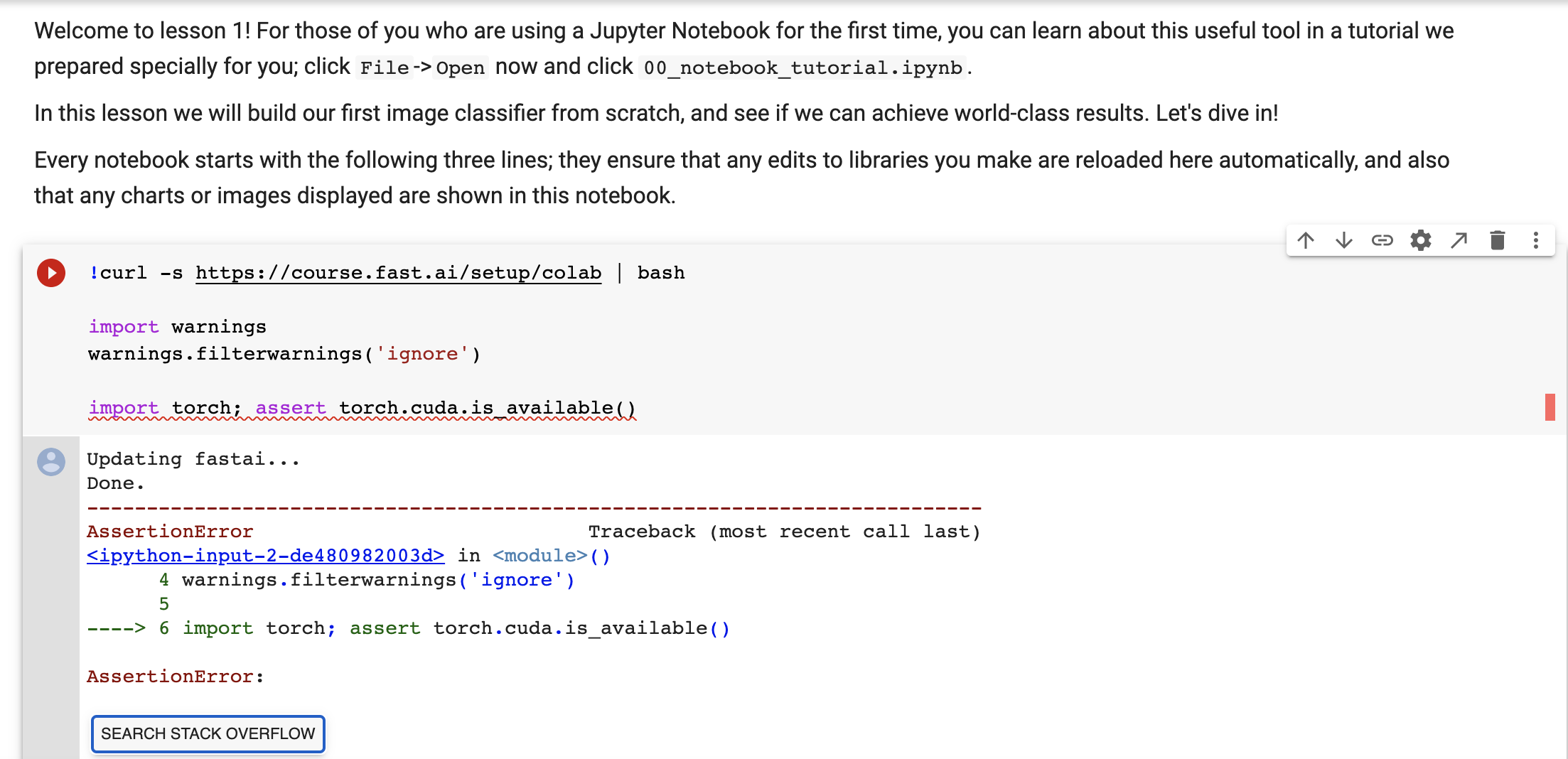
Go and turn on GPU. On the menu, click runtime->change runtime type then change hardware accelerator to GPU