to fit our needs and this uses actual files for the FILES variable. So I was wondering if there was a different class we should be using or if there is a way to turn our data into the type of argument that is looking for. Here is what arguments are available:
I doubt that’s going to do what @KevinB wants. Although it’s a little hard to know since we really need to find out the structure of those CSV files Can you provide an example of a couple of rows?
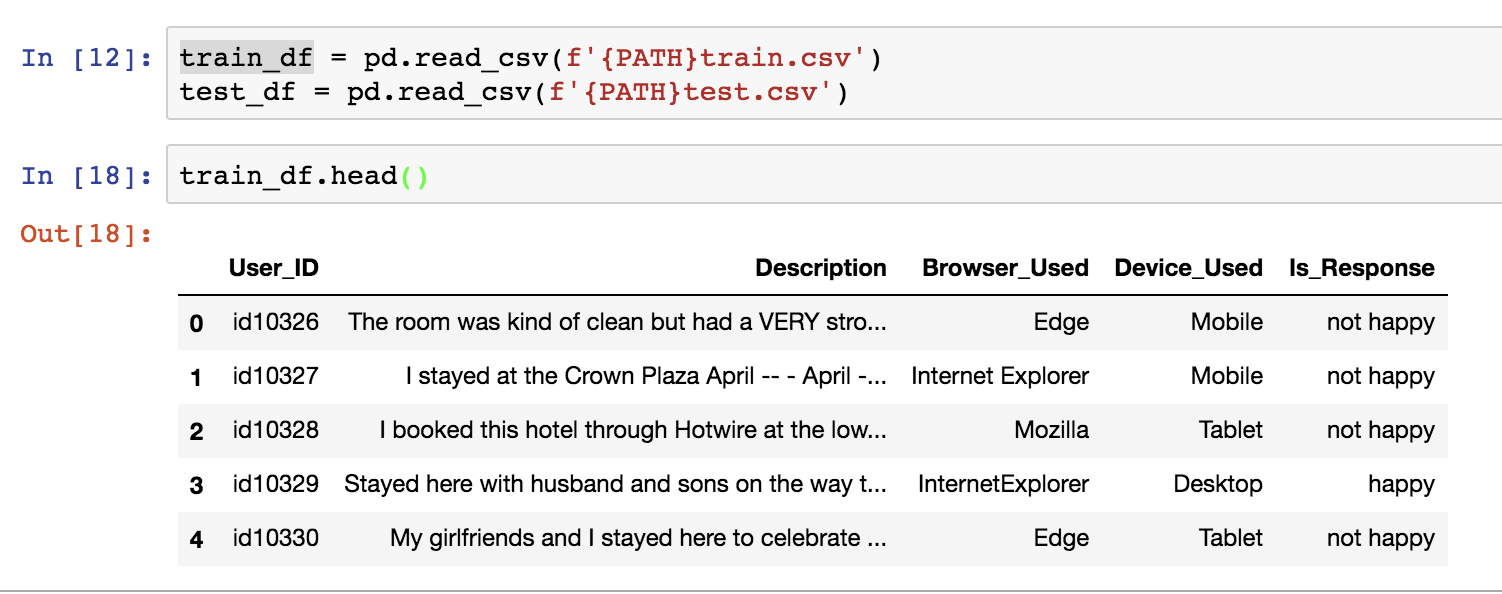
It is the Predict the Happiness Challenge. Here is my head of the train:
User_ID Description Browser_Used Device_Used Is_Response
0 id10326 The room was kind of clean but had a VERY stro... Edge Mobile not happy
1 id10327 I stayed at the Crown Plaza April -- - April -... Internet Explorer Mobile not happy
2 id10328 I booked this hotel through Hotwire at the low... Mozilla Tablet not happy
3 id10329 Stayed here with husband and sons on the way t... InternetExplorer Desktop happy
4 id10330 My girlfriends and I stayed here to celebrate ... Edge Tablet not happy
I was just about to ask the same question, for the IMBD notebook we have all of the text reviews as separate text files so we are using the function texts_from_files. Do you think it would make sense to have another function texts_from_csv to handle data like this more easily? Similarly to how we are handling image files from_csv vs from_paths.
@KevinB just fyi you can actually use pandas to_csv function to save the df to text instead of saving as a csv. I found this a little easier to work with than np.savetxt. The below code worked well for me assuming the text string is in the second column and id is in the first column.
for x in train.iterrows():
pd.DataFrame([x[1][1]]).to_csv(TRN + str(x[1][0])+".txt", header=False, index=False)
I actually didn’t end up using np.savetxt. Just followed @hiromi’s lead and used straight up python like this:
for i in range(trn.values[:,1].shape[0]):
f = open(PATH+"train/"+trn.values[i,0]+".txt", 'w')
f.write(trn.values[i,1])
f.close()
So all this does is saves each description into a file called id#####.txt. It worked pretty well and it seems to be what LanguageModelData expects to get.
I found that reading in the csv with pandas and then using LanguageModelData.from_dataframes worked well. It saved a lot of time because I didn’t have to write each individual file to disk, which was taking a while.