Thanks for you comments about SP tokenization, they are very insightful!
I think fast.ai does not support subword sampling in the usual setup. You would have to replace the LanguageModelLoader class in text.py (Careful, there is one in nlp.py, too, I hope I didn’t get it wrong).
This could be involved because the iterator tries to return a certain number of tokens and that would mean that how much text you grab with each iteration depends on the subword sampling (and you would need to deal with funny splits). Maybe the best strategy is keep a queue of tokens to be returned next and do the conversion and subword sampling in batches.
You would mean moving quite a bit of the preprocessing into the training itself, probably with some performance impact. On the other hand, in PyTorch it is very common to do data augmentation on the fly, and it might not be too bad given that the vocabulary is much smaller when using SP instead of full words.
I’m looking into testing SP-based training for German, so I hope to learn from your experience and maybe also be able to add some of my own.
You don’t need more dropout or wd - your val loss is still decreasing. You can train for a few more epochs if you like. But your perplexity is already excellent so you should be able to create a good classifier now.
Sure it does fastai.text simply takes a numericalized list of tokens as input. That list can be generated using SentencePiece - and everything will work just fine!
Thank you for the correction! My impression was that “sampling from the possible sets of subwords according to likelihood” would also be done at training time - which sounded not too unlikely when looking at the Subword Regularization’s on-the-fly subword sampling method.
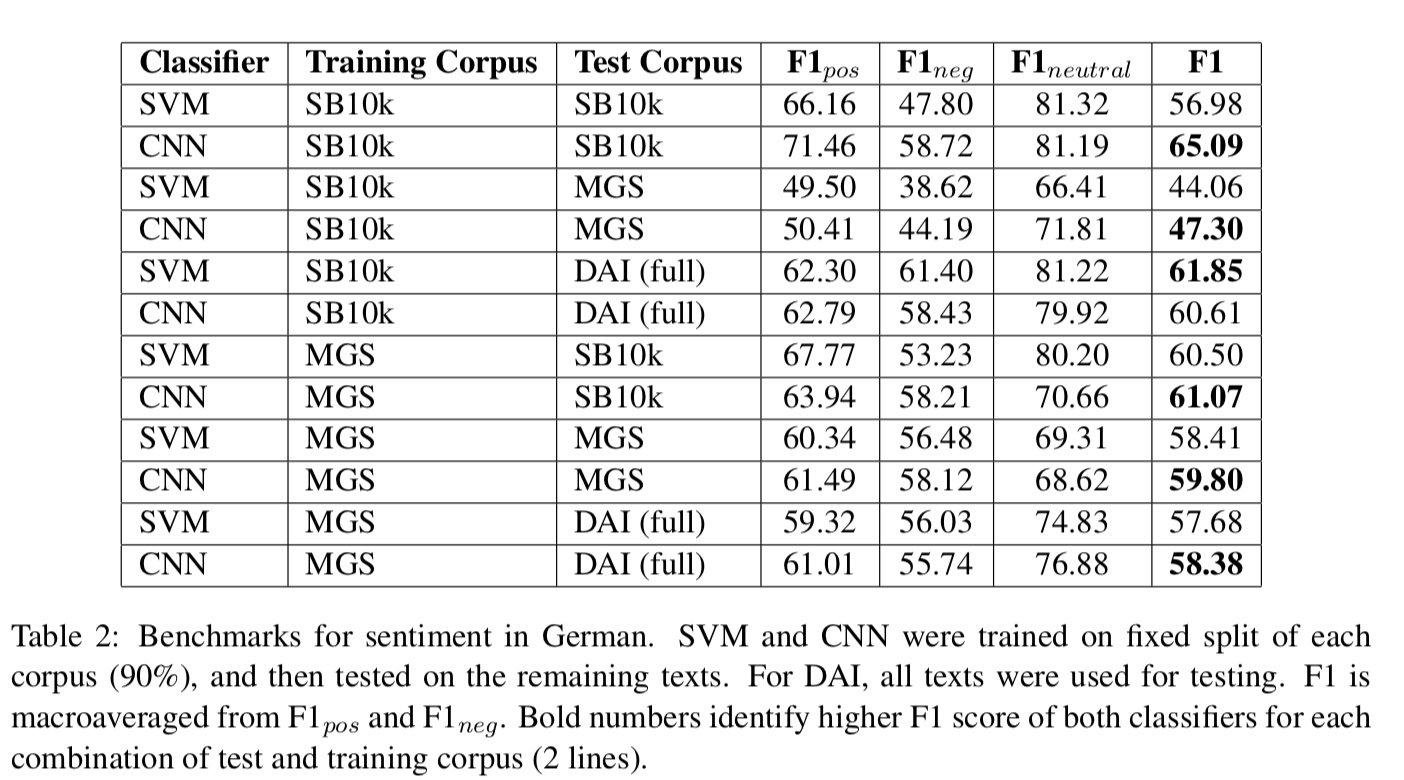
So I used the language model for German Language shared by @t-v yesterday and trained a classifier for sentiment analysis of Twitter messages using the SB-10k Corpus.
I have also trained a new classifier using a fixed learning rate for all layers (lr=1e-2 as obtained from lr_find()), but the results seem to be the same…
Are you sure it is low, at least for the polish language it would be around SOTA? We have 0.795 on micro accuracy and 0.54 for accuracy calculated on whole sentences.
Micro accuracy is precentage of correct prediction of sentyment for each node in a sentence tree (ie word/subsentence in the sentence. So if you count neutral sentiment as well then such accuracy is >0.6 (guessed) for model that simply predicts neutral sentiment everywhere.
I have been searching for Japanese language classification/sentiment analysis papers, results, or anything. I saw many positive/negative dictionary that classifies each word to positive or negative, and classifiers that utilize those dictionaries. But that’s about it.
thanks for sharing! I am planning to start experimenting with German models and this is very helpful. Any chance you will also share the preparation notebook?
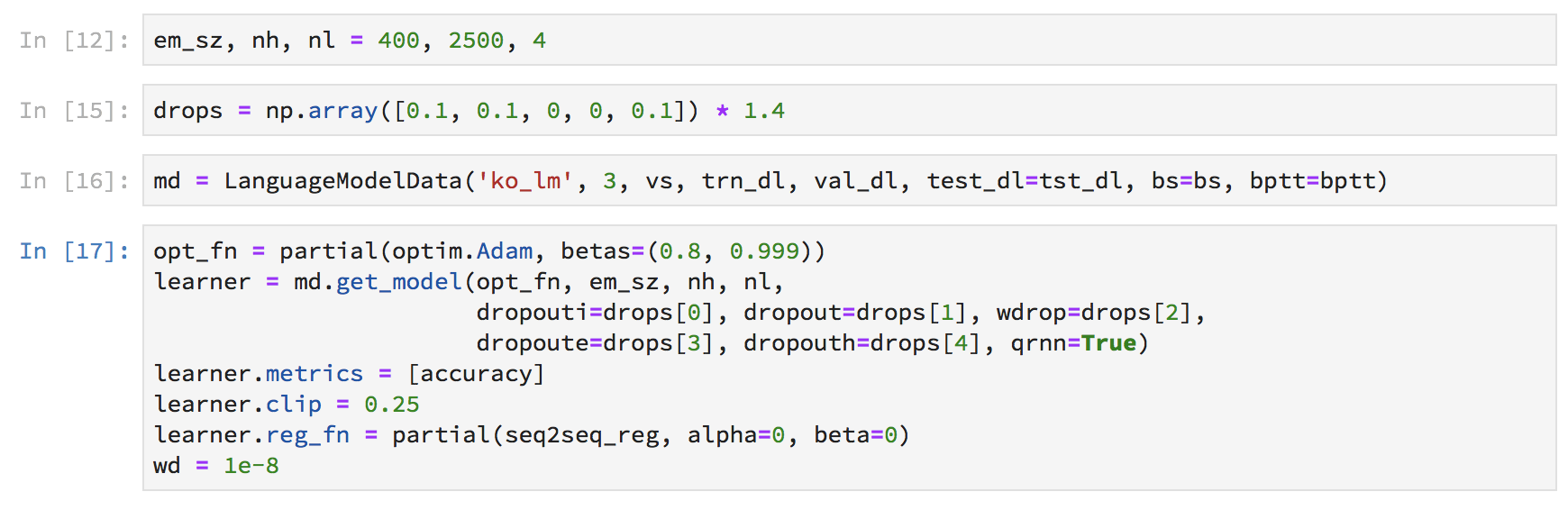
What’s the intuition on the embedding size of 400 for words, and how appropriate is it to change across language families?
I’m having a hard time achieving perplexities below ~73 for Korean on kowiki text tokenized with sentencepiece, and I’m wondering CJK have been found to benefit from higher dimension embeddings.
I was missing in action for a bit due to a heavy work schedule. Crunching away at a German language model now (using the same parameters). 3 epochs in the crossentropy is at about 3.89.
I started with a 48 bs which lead to Cuda OOM so I halved it and it works now. Once the crunching is done I’ll go up to 36 and see if that’ll fit. Seems like it’ll be a bit worse than Thomas’ model when all is set and done but I want a baseline system to experiment with and wanted to walk through the procedure once.
I’ll post the results once it’s finished tomorrow (ETA around 15:00h).
Do you usually run multiple epochs or one epoch at a time and save after each? Also does it make sense to ensemble say a wiki103 and some newspaper corpus or the like. I think it does in theory but might make more sense to use the other corpus as extra layers if you’re eventually trying to infer in that domain?
Edit: Only got 3.56 after 10 epochs. I think the only thing I changed was min freq of 3 (since I saw some meaningful words with 5) and I might have increased the vocabulary size (+another snapshot of the wikipedia). But the good news is the stress test/running through all steps seems to have worked. I’ll clean up the notebooks a bit and think about parameters.
Couldn’t really find recent perplexity values for German so far as that would have been an interesting comparison. I’ll try some classifier on top next week but cleanup comes first
The generated text is still gibberish, but what gives me hope is that the model seems to have learned some short and long range grammatical dependencies. For those who read Korean:
Regarding embedding size for Korean, I’ve found prior research suggesting that depending on tokenization method (space, token, char), 500 ~ 1000 size embeddings are not unreasonable.
If you’re still looking for a dataset, maybe this is useful: https://github.com/dennybritz/sentiment-analysis/tree/master/data. There also a japanese-english subtitle dataset (https://nlp.stanford.edu/projects/jesc/) thats used for Machine Translation but maybe you can use the trained English model to label the English dataset and then label the corresponding Japanese sentence as well. It would be a bit noisy but better than nothing. But a lot of Japanese sentiment analysis research (as you discovered) revolves around polarity, mostly because there’s a lack of open datasets like English.
Oh wow, thank you!! The movie review one looks great!
I did think about translating English dataset into Japanese, but then I hesitated a little because machine translation is not perfect and idioms and metaphors do not translate very well.
Thank you for sharing the data. I was this close to start scraping Rakuten site for user reviews somehow which would have taken me ages