My corpus has more than 98 million words (about 49k articles, more than 42k for training). Each epoch takes more than 3 hours to run! Does anyone have a similar problem with wikipedia corpus? Is there any strategy to alleviate this kind of problem? My batch size is 32 and the training takes 4 - 5 iterations per second, in a GPU (32MB RAM).
for me it takes ~two hours per epoch, I had a GTX1080 and a similar parameters (in particular 32 batch size and 100M words). It seemed like drastically decreasing dropout would a good idea there (surprise, when Jeremy recommends it), as the train loss was still rather high after 7 epochs with dropout factor 0.5. Or you might try whether Sylvain’s 1-cycle parameters earlier in the thread get you there faster.
Thomas
P.S.: I’m not sure whether we should try to debug spacy somewhere else to not derail the Language Zoo topic, but maybe you open a new thread somewhere and paste the output of the sudo python3 -m spacy download pt or whatever you use to install the spacy language model.
I reduced the dropout constant from 0.7 to 0.05 and now the first epoch is still running with an estimate of more than 3 hours to complete. The problem seems to be due to the small number of iterations (about 4.28 iterations per second) combined with a small batch size.
It’s still not very clear for me the relation between decreasing dropout rates and training times. Is it because of some overhead due to calculating average gradients (compensating for the dropped out units) ? In practice, dropout is implemented with a mask, so it shouldn’t generate much overhead (at least intuitively).
Finally, I also pretend to try 1-cycle and super convergence.
It doesn’t change the time it takes. I think the experience is that with that large a dataset, you can reduce dropout significantly. The other bit of wisdom is that while this takes long, you can see it as a one-off investment that will give you (and everyone else if you share the model) a really great basis for fine-tuning. These fine-tuning steps to specific tasks then are fast (so low “running costs”). I know from my own experience letting things sit and calculate for a whole day can be painful, but it seems that this is the recommended path here.
After the 3-hour-length 1st epoch training, I realized a slightly worse validation error, and lr_find gave a hint about the learning rate - it should be higher, to compensate for the lower dropout regularization, as pointed by Leslie Smith.
I’ll follow @urmas.pitsi’s suggestions because the full training cycle (eg: 15 epochs) is taking 3 days. I understand the first iterations should be used to try different settings and see which hyperparameters are the most important. Finally, after finding the best results, I expect to be able to replicate them with the larger dataset.
@t-v, I have a spare GPU so I can help you run the code if you have the script with all the hyper parameters setup.
Then maybe we can together figure out how to work with results that follows Stanford Sentiment Treebank, I think German has results using that metric as well, am I right?
Hello Piotr,
He thanks! I hope to have a GPU again when I return on the weekend, if not I’ll certainly take you up on that. For the SST you mean discarding all the tree info and just keeping the sentiment for the entirety? I think that should be relatively easy to convert to fast.ai-ish CSV. I’m happy to share code for that if it helps.
I’ve reduced my vocab size to 30000 - now each epoch takes about 2 hs (as opposite to 3 hs).
I’m following 1cycle, with most parameters similar to the ones used by @sgugger, except for dropout (constant factor = 0.05, just to compensate for higher learning rate), and now, with 2 epochs, I got a validation error a little closer to the French and Spanish language models shown in this thread (I don’t think it’s relevant, but coincidentially PT, FR and ES are latin languages):
I guess what may cause such different plots just by changing iterations number (something related to the rate scheduling, don’t remember the details from the paper right now). Finally I chose the higher learning rate (5.0) to train for the remaining epochs.
That specific problem (". A") won’t occur anyways because SP by default does not cross whitespace boundaries.
Still learning about internals of SP, but one anecdote is that I put a huge concatenated single line of scraped text into SP learner by accident, and this seemed to have no ill effect on efficacy of tokenization.
I hope you received your GPU replacement :), if not let me know.
Re. SST, I was more looking for a way to interpret the files provided in poleval as no one bothered to describe them. Fortunately, I’ve found the model that won this competition, so I just read the code to figure out the structure of the competition files.
Btw. Once I’ve converted the “micro-accuracy” to macro? / normal accuracy ie one that checks the overall sentiment of a sentence, it dropped from 0.78 to 0.54. (I wasn’t expecting it to be that bad especially when English accuracy is above 0.9). I’m curious how good is SOTA for German models, let me know when you convert the micro-accuracy to the normal sentence wise accuracy.
A core benefit of SP is that it attempts to still read anything OOV as a series of subword segment, sampling from the possible sets of subwords according to likelihood.
i.e. if “abracadabra” is not in the vocab, the following are all possible subword sequences: ["abra", "cad", "abra"], ["a", "bra", "cada", "bra"], ["ab", "ra", "cada", "bra"] ...
Doing this subword sampling during training apparently improved NMT models and made the trained weights more resilient to OOV words.
My question is does fastai support this kind of training with LanguageModelData and LanguageModelLoader? Essentially, rather than pre-building a tokenized and stoi’d version of the train/test, I want to keep the train/test as the original text, and tokenize w/ subword sampling at each epoch.
Hi, thanks!
So I’m back in business and even with a larger batch size.
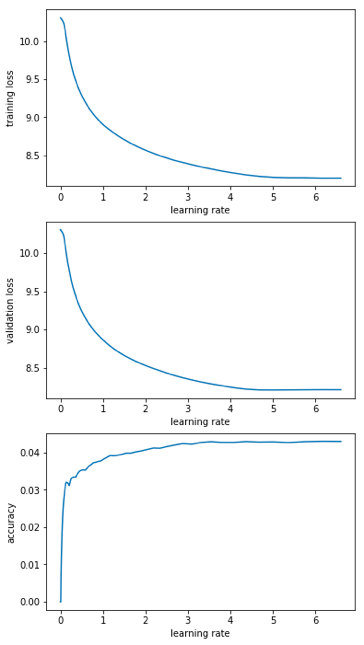
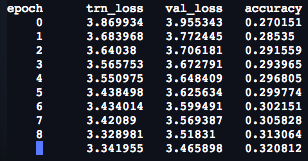
So for German with 0.1 dropout factor and sgugger’s parameters I get for the first 10 epochs
Based on Jeremy’s comments, I’m benchmarking with dropout factor 0.05, too, but after 4 epochs, it’s not seeing any improvement over 0.1.
I have also been wondering about a good intrinsic metric for comparing sentencepiece vs. spacy word segmentation - application performance is one thing, but an intrinsic metric would be cool, too.
Perplexity depends on the distribution of the codebook and isn’t applicable, but would bits or nats per character be a good metric?
Best regards
Thomas
P.S.: If the format is the same as the Stanford sentiment tree bank, there is a readme in that - though it says “look at the matlab code”…