Hi, all.
When building a language model with fastai, I would like to get the word count to find p(w) for the training dataset based on the itos in the vocabulary. However, such a feature does not seem to be saved when it builds TextDataBunch.
Could you give me some suggestion on how to do it? Thank you very much.
Actually, it is part of the preprocessing done in fastai, just that the intermediate results are not saved. I won’t go into excruciating detail, but basically this is what happens after the sentences are tokenized.
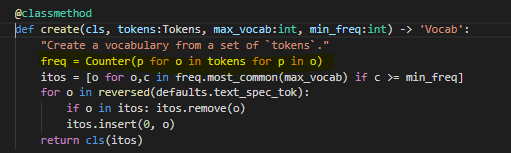
The above method belongs to the Vocab class since it needs to only keep words that occur frequently in the corpus. So perhaps the easiest thing to do is run a tokenizer on your corpus and run that line of code I highlighted on the tokenized text.